I need to explain this in excruciating detail because I don't have the basics of statistics to explain in a more succinct way. Asking here in SO because I am looking for a python solution, but might go to stats.SE if more appropriate.
I have downhole well data, it might be a bit like this:
Rt T
0.0000 15.0000
4.0054 15.4523
25.1858 16.0761
27.9998 16.2013
35.7259 16.5914
39.0769 16.8777
45.1805 17.3545
45.6717 17.3877
48.3419 17.5307
51.5661 17.7079
64.1578 18.4177
66.8280 18.5750
111.1613 19.8261
114.2518 19.9731
121.8681 20.4074
146.0591 21.2622
148.8134 21.4117
164.6219 22.1776
176.5220 23.4835
177.9578 23.6738
180.8773 23.9973
187.1846 24.4976
210.5131 25.7585
211.4830 26.0231
230.2598 28.5495
262.3549 30.8602
266.2318 31.3067
303.3181 37.3183
329.4067 39.2858
335.0262 39.4731
337.8323 39.6756
343.1142 39.9271
352.2322 40.6634
367.8386 42.3641
380.0900 43.9158
388.5412 44.1891
390.4162 44.3563
395.6409 44.5837
(the Rt variable can be considered a proxy for depth, and T is temperature). I also have 'a priori' data giving me the temperature at Rt=0 and, not shown, some markers that i can use as breakpoints, guides to breakpoints, or at least compare to any discovered breakpoints.
The linear relationship of these two variables is in some depth intervals affected by some processes. A simple linear regression is
q, T0, r_value, p_value, std_err = stats.linregress(Rt, T)
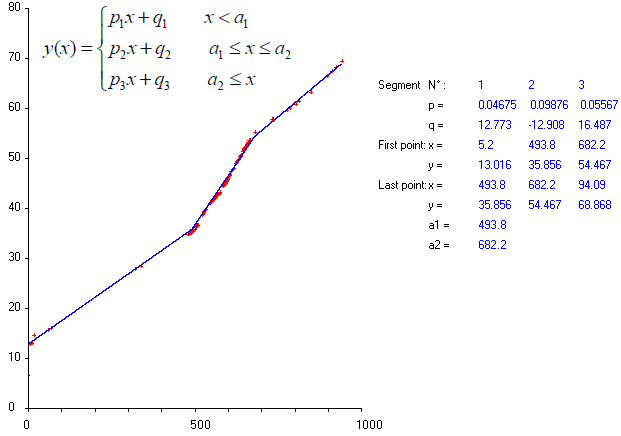
and looks like this, where you can see the deviations clearly, and the poor fit for T0 (which should be 15):

I want to be able to perform a series of linear regressions (joining at ends of each segment), but I want to do it: (a) by NOT specifying the number or locations of breaks, (b) by specifying the number and location of breaks, and (c) calculate the coefficients for each segment
I think I can do (b) and (c) by just splitting the data up and doing each bit separately with a bit of care, but I don't know about (a), and wonder if there's a way someone knows this can be done more simply.
I have seen this: https://stats.stackexchange.com/a/20210/9311, and I think MARS might be a good way to deal with it, but that's just because it looks good; I don't really understand it. I tried it with my data in a blind cut'n'paste way and have the output below, but again, I don't understand it: