I have a dataframe with around around 9k rows and 57 cols, this is 'df'.
I need to have a new dataframe: 'df_final' - for each row of 'df' i have to replicate each row 'x' times and increase the day in each row one by one, also 'x' times. While i can do this for a couple of iterations, when i do it for the full length of 'df' ' len(df)' the loop it takes so long (>3 hours) that i actually had to cancel it. I have never seen the end of it. Here's the current code:
df.shape
output: (9454, 57)
df_int = df[0:0]
df_final = df_int[0:0]
range_df = len(df)
for x in range(0,2):
df_int = df.iloc[0+x:x+1]
if abs(df_int.iat[-1,3]) > 0:
df_int = pd.concat([df_int]*abs(df_int.iat[-1,3]), ignore_index=True)
for i in range(1, abs(df_int.iat[-1,3])):
df_int['Consumption Date'][i] = df_int['Consumption Date'][i-1] + datetime.timedelta(days = 1)
i += 1
df_final = df_final.append(df_int, ignore_index=True)
x += 1
The result of the loops for the first two rows of ' df' are below.
First two rows of df:
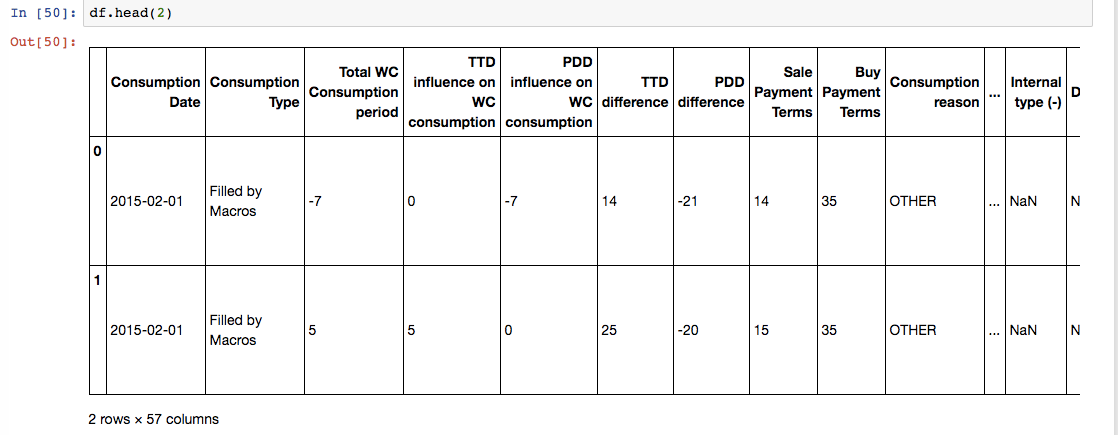
Desired result:
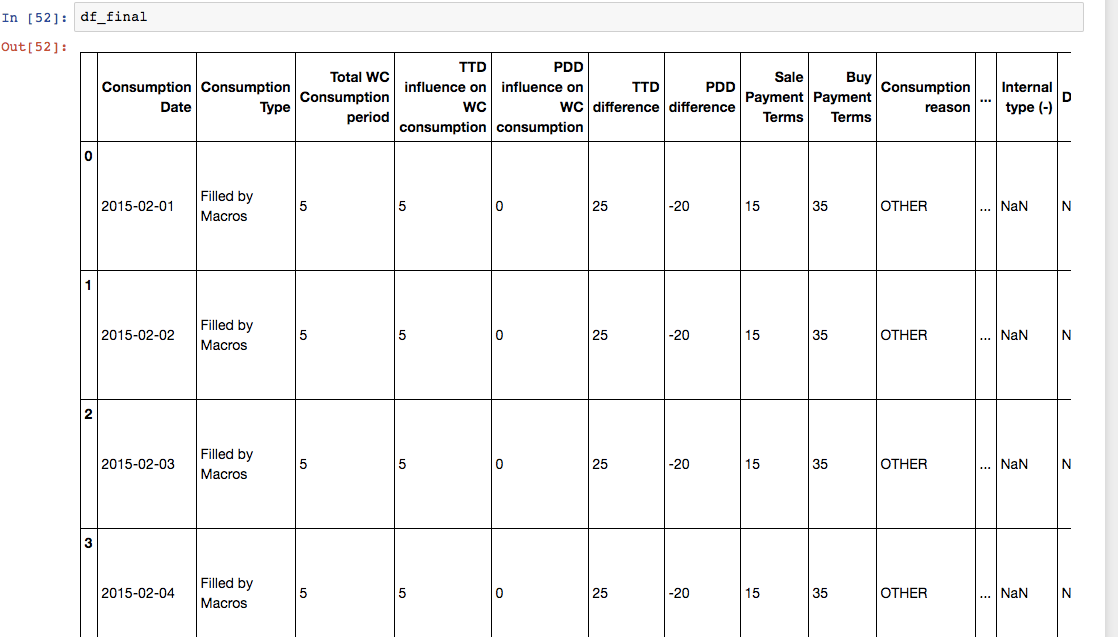
Is there another way to get to the desired output. It seems pandas do not deal very well with loops. In VBA excel the same loop takes around 3/4 minutes...i am trying to change a process which is currently in excel to python, however, if there's no way to make this work i guess i will stick to the old ways...