in my database, the graph looks somehow like this:
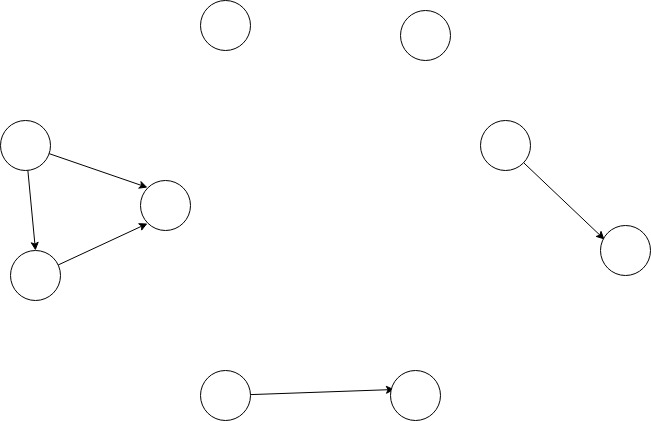
I want to find the top 3 biggest cluster in my data. A cluster is a collection of nodes connected to each other, the direction of the connection is not important. As can be seen from the picture, the expected result should have 3 clusters with size 3 2 2 respectively.
Here is what I came up with so far:
MATCH (n)
RETURN n, size((n)-[*]-()) AS cluster_size
ORDER BY cluster_size DESC
LIMIT 100
However, it has 2 problems:
- I think the query is wrong because the size() function does not return the number of nodes in a cluster as I want, but the number of sub-graph matching the pattern instead.
- The
LIMITclause limits the number of nodes to return, not taking the top result. That's why I put 100 there.
What should I do now? I'm stuck :( Thank you for your help.
UPDATE
Thanks to Bruno Peres' answer, I'm able to try algo.unionFind query in Neo4j Graph Algorithm. I can find the size of my connected components using this query:
CALL algo.unionFind.stream()
YIELD nodeId,setId
RETURN setId,count(*) as size_of_component
ORDER BY size_of_component DESC LIMIT 20;
And here is the result:
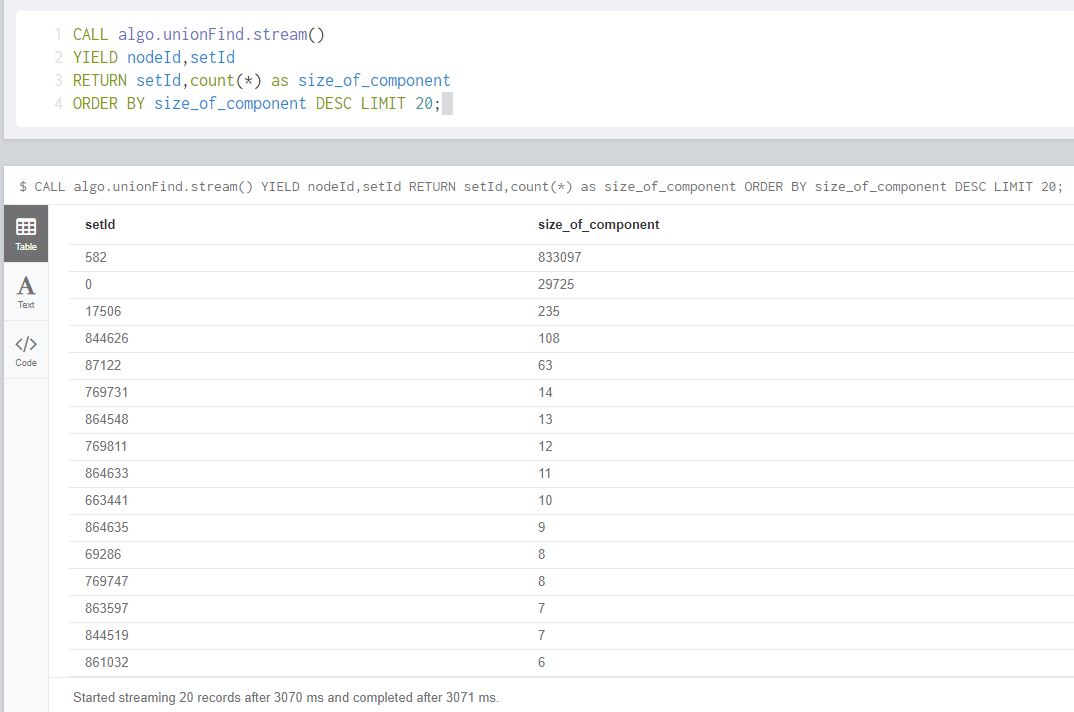
But that's all I know. I cannot get any information about the nodes in each component to visualize them. The collect(nodeId) takes forever because the top 2 components are too large. And I know it doesn't make sense to visualize those large components, but how about the third one? 235 nodes are fine to render.