Here is a one-line solution with the openturns library, assuming your data is a numpy array named sample.
import openturns as ot
ot.NormalFactory().build(sample.reshape(-1, 1)).computeQuantile(0.95)
Let us unpack this. NormalFactory is a class designed to fit the parameters of a Normal distribution (mu and sigma) on a given sample: NormalFactory() creates an instance of this class.
The method build does the actual fitting and returns an object of the class Normal which represents the normal distribution with parameters mu and sigma estimated from the sample.
The sample reshape is there to make sure that OpenTURNS understands that the input sample is a collection of one-dimension points, not a single multi-dimensional point.
The class Normal then provides the method computeQuantile to compute any quantile of the distribution (the 95-th percentile in this example).
This solution does not compute the exact tolerance bound because it uses a quantile from a Normal distribution instead of a Student t-distribution. Effectively, that means that it ignores the estimation error on mu and sigma. In practice, this is only an issue for really small sample sizes.
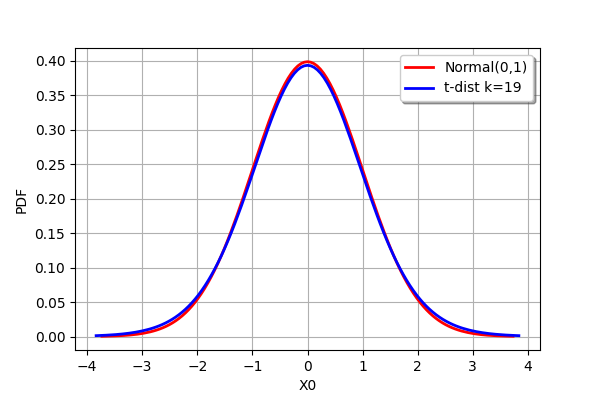
To illustrate this, here is a comparison between the PDF of the standard normal N(0,1) distribution and the PDF of the Student t-distribution with 19 degrees of freedom (this means a sample size of 20). They can barely be distinguished.
deg_freedom = 19
graph = ot.Normal().drawPDF()
student = ot.Student(deg_freedom).drawPDF().getDrawable(0)
student.setColor('blue')
graph.add(student)
graph.setLegends(['Normal(0,1)', 't-dist k={}'.format(deg_freedom)])
graph
![Compare Normal and Student t distributions]()