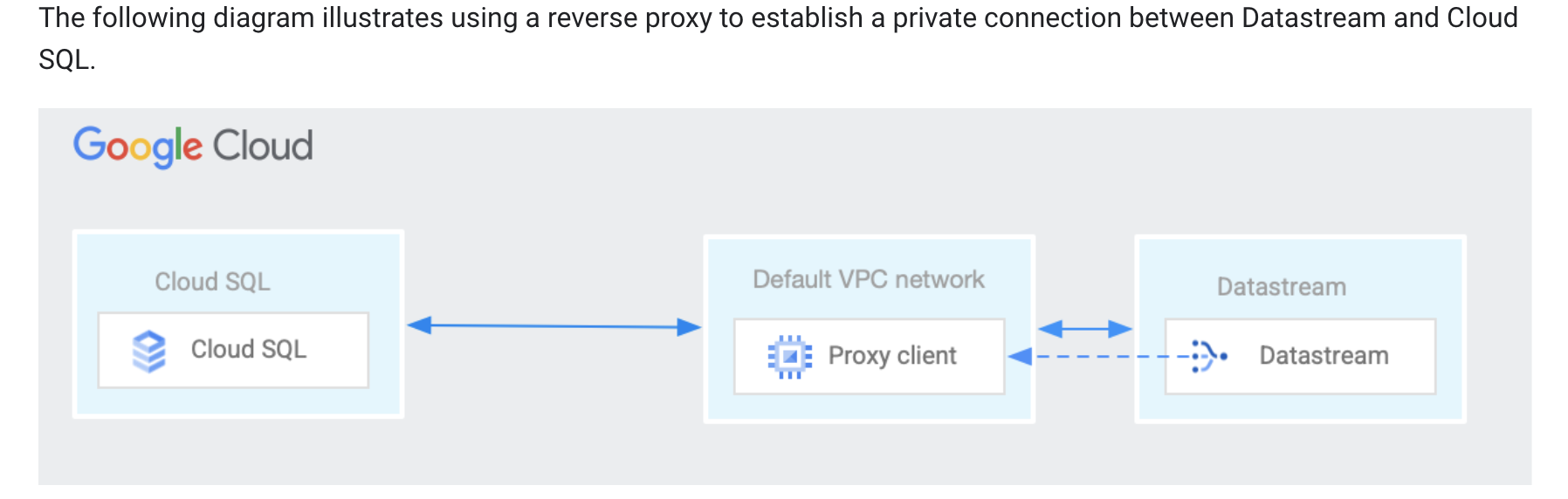
My goal should be quite straight forward: I have a PostgreSQL running in Cloud SQL, and want to use Datastream to transfer data to Big Query, within the same project, preferably through private IP connectivity.
I have set up the database with private IP, created a private connectivity in Datastream with an available IP range on the database's VPC, and set up a connection profile towards the private IP with the correct credentials.
All I get for now is a timeout when I test the connection, being a bit hard to debug.
I have also tried enabling firewall rules to accept the traffic, with the same result. (Is it necessary to create firewall rules in this case?)
At first I thought the reverse proxy would only be needed when connecting from outside the GCP project or from other networks. Do I really need it in this case as well? Shouldn't they be accessible when they are within the same GCP project?
The amount of work and config needed to make this work leads me to believe that I am doing something the wrong way or not following best practice here. As this is assumably a central part of Datastream/GCP functionality, I assume there is a simpler and more easy to maintain way? I am setting up several databases to transfer analytics data to Big Query, so minimizing the overhead for each of them is a big advantage.
What would be the preferred way to acheive this?
Side question: Apart from Datastream, is there another preferred way / best practice to transfer data to Big Query from Cloud SQL? In the Cloud SQL config I see the option "Enable private path: Allows other Google Cloud services like BigQuery to access data and make queries over Private IP" but I can't find much documentation on what this is and how to use it.