I've been trying to write a general compute shader Gaussian blur implemenation.
It basically works, however it contains artifacts which change every frame even when the scene is static. I've spent the past few hours trying to debug this. I've gone as far as ensuring bounds aren't exceeded, unrolling all the loops, replacing uniforms with constants, yet the artifacts persist.
I've tested the original code with artifacts on 3 different machines/GPUs (2 nvidia, 1 intel) and they all produce the same results. Simulating the unrolled/constant version of the codes execution with workgroups executed forwards and backwards with plain C++ code doesn't produce these errors.
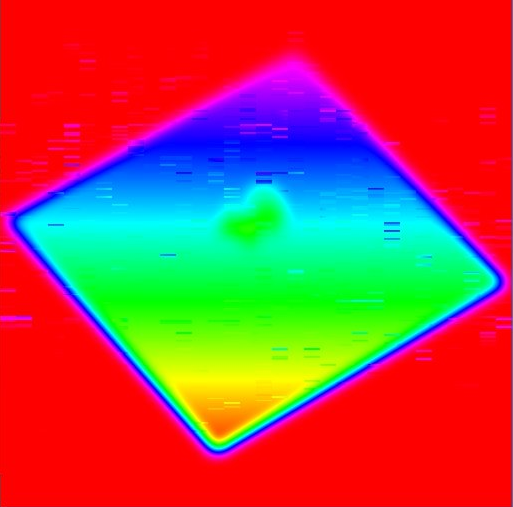
By allocating a shared array of [96][96] instead of [16][48] I can eliminate most of the artifacts.
This got me to the point of thinking I was missing a logic error, therefore I managed to produce a very simple shader which still produces the error on a smaller scale, I'd appreciate it if someone could point out the cause. I've checked alot of documentation and can't find anything incorrect.
A shared array of 16x48 floats is allocated, this is 3072 bytes, roughly 10% of the minimum shared memory limit.
The shader is launched in 16x16 workgroups, so each thread will write to 3 unique locations, and read back from a single unique location
The texture is then renderer as HSV whereby vals between 0-1 will map to hue 0-360 (red-cyan-red), and out of bounds values will be red.
#version 430
//Execute in 16x16 sized thread blocks
layout(local_size_x=16,local_size_y=16) in;
uniform layout (r32f) restrict writeonly image2D _imageOut;
shared float hoz[16][48];
void main ()
{
//Init shared memory with a big out of bounds value we can identify
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y] = 20000.0f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+16] = 20000.0f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+32] = 20000.0f;
//Sync shared memory
memoryBarrierShared();
//Write the values we want to actually read back
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y] = 0.5f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+16] = 0.5f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+32] = 0.5f;
//Sync shared memory
memoryBarrierShared();
//i=0,8,16 work
//i=1-7,9-5,17 don't work (haven't bothered testing further
const int i = 17;
imageStore(_imageOut, ivec2(gl_GlobalInvocationID.xy), vec4(hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+i]));
//Sync shared memory (can't hurt)
memoryBarrierShared();
}
Launching this shader with launch dimensions greater than 8x8 produces artifacts in the affected area of the image.
glDispatchCompute(9, 9, 0);
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
I had to breakpoint and step frames to capture this, took around 14 frames

glDispatchCompute(512/16, 512/16, 0);//Full image is 512x512
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
Again I had to breakpoint and step frames to capture this, when running at 60FPS (vsync) artifacts appeared more frequently/simultaneously.
