Despite having searched for two day in related questions, I have not really found an answer to this Problem yet...
In the following code, I generate n normally distributed random variables, which are then represented in a histogram:
import numpy as np
import matplotlib.pyplot as plt
n = 10000 # number of generated random variables
x = np.random.normal(0,1,n) # generate n random variables
# plot this in a non-normalized histogram:
plt.hist(x, bins='auto', normed=False)
# get the arrays containing the bin counts and the bin edges:
histo, bin_edges = np.histogram(x, bins='auto', normed=False)
number_of_bins = len(bin_edges)-1
After that, a curve fitting function and its parameters are found. It is normally distributed with the parameters a1 and b1, and scaled with scaling_factor to meet the fact that the sample is unnormalized. It indeed fits the histogram quite well:
import scipy as sp
a1, b1 = sp.stats.norm.fit(x)
scaling_factor = n*(x.max()-x.min())/number_of_bins
plt.plot(x_achse,scaling_factor*sp.stats.norm.pdf(x_achse,a1,b1),'b')
Here's the plot of the histogram with the fitting function in red.
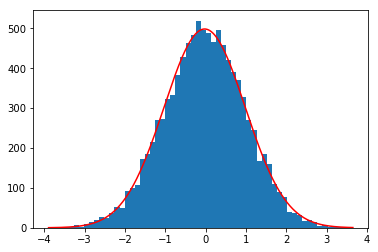{kind=link}
After that, I want to test how well this function fits the histogram using the chi-squared test. This test uses the observed values and the expected values in those points. To calculate the expected values, I first calculate the location of the middle of each bin, this information is contained in the array x_middle. I then calculate the value of the fitting function at the middle point of each bin, which gives the expected_value array:
observed_values = histo
bin_width = bin_edges[1] - bin_edges[0]
# array containing the middle point of each bin:
x_middle = np.linspace( bin_edges[0] + 0.5*bin_width,
bin_edges[0] + (0.5 + number_of_bins)*bin_width,
num = number_of_bins)
expected_values = scaling_factor*sp.stats.norm.pdf(x_middle,a1,b1)
Plugging this into the chisquare function of Scipy, I get p-values of approximately e-5 to e-15 order of magnitude, which tells me the fitting function does not describe the histogram:
print(sp.stats.chisquare(observed_values,expected_values,ddof=2))
But this is not true, the function fits the histogram very well!
Does anybody know where I made a mistake?
Thanks a lot!! Charles
p.s.: I set the number of delta degrees of freedom to 2, because the 2 parameters a1 and b1 are estimated from the sample. I tried using other ddof, but the results were still as poor!