I have a shell script in HDFS. I have scheduled this script in oozie with the following workflow.
Workflow:
<workflow-app name="Shell_test" xmlns="uri:oozie:workflow:0.5">
<start to="shell-8f63"/>
<kill name="Kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<action name="shell-8f63">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<exec>shell.sh</exec>
<argument>${input_file}</argument>
<env-var>HADOOP_USER_NAME=${wf:user()}</env-var>
<file>/user/xxxx/shell_script/lib/shell.sh#shell.sh</file>
<file>/user/xxxx/args/${input_file}#${input_file}</file>
</shell>
<ok to="End"/>
<error to="Kill"/>
</action>
<end name="End"/>
job properties
nameNode=xxxxxxxxxxxxxxxxxxxx
jobTracker=xxxxxxxxxxxxxxxxxxxxxxxx
queueName=default
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/xxxxxxx/xxxxxx
args file
tableA
tableB
tablec
tableD
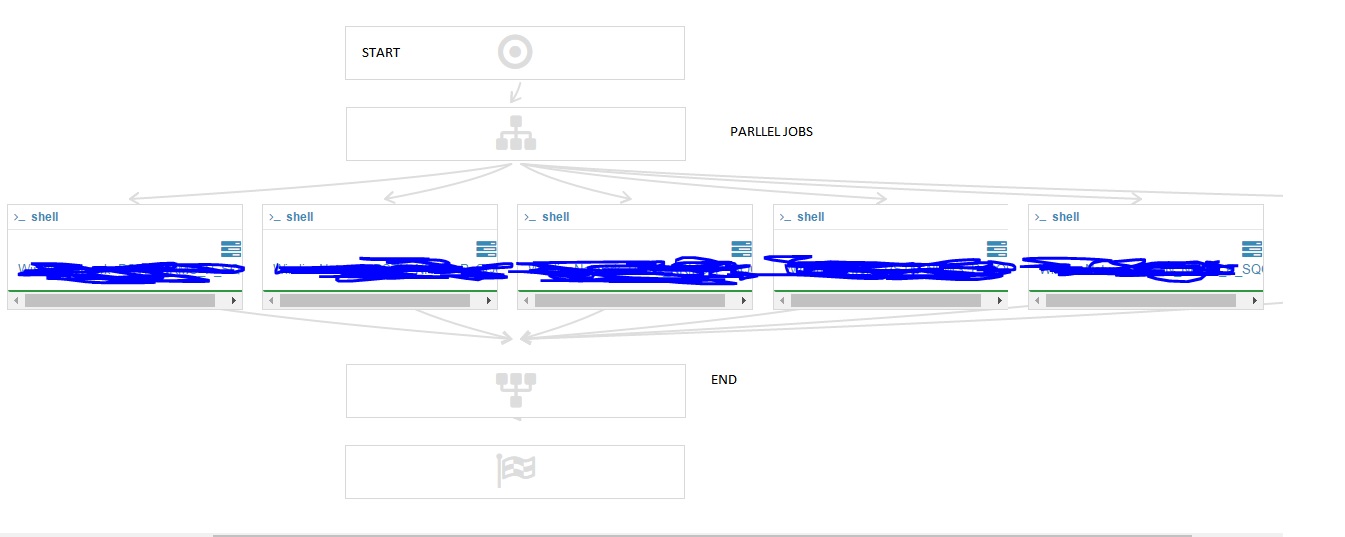
Now the shell script runs for single job name in args file. How can I schedule this shell script to run in parallel.
I want the script to run for 10 jobs at the same time.
What are the steps needed to do so. What changes should I make to the workflow.
Should I create 10 workflows for running 10 parallel jobs. Or what are the best scenarios to deal with this issue.
My shell script:
#!/bin/bash
[ $# -ne 1 ] && { echo "Usage : $0 table ";exit 1; }
table=$1
job_name=${table}
sqoop job --exec ${job_name}
My sqoop job script:
sqoop job --create ${table} -- import --connect ${domain}:${port}/${database} --username ${username} --password ${password} --query "SELECT * from ${database}.${table} WHERE \$CONDITIONS" -m 1 --hive-import --hive-database ${hivedatabase} --hive-table ${table} --as-parquetfile --incremental append --check-column id --last-value "${last_val}" --target-dir /user/xxxxx/hive/${hivedatabase}.db/${table} --outdir /home/$USER/logs/outdir
10always? Why not useforkandjoin? – Sixtyfour