I am trying to understand if I have an issue with my AWS Elasticsearch garbage collection time but all the memory-related issues that I find are relating to memory pressure which seems OKish.
So while I run a load test on the environment, I observe a constant rise in all GC collection time metrics, for example:
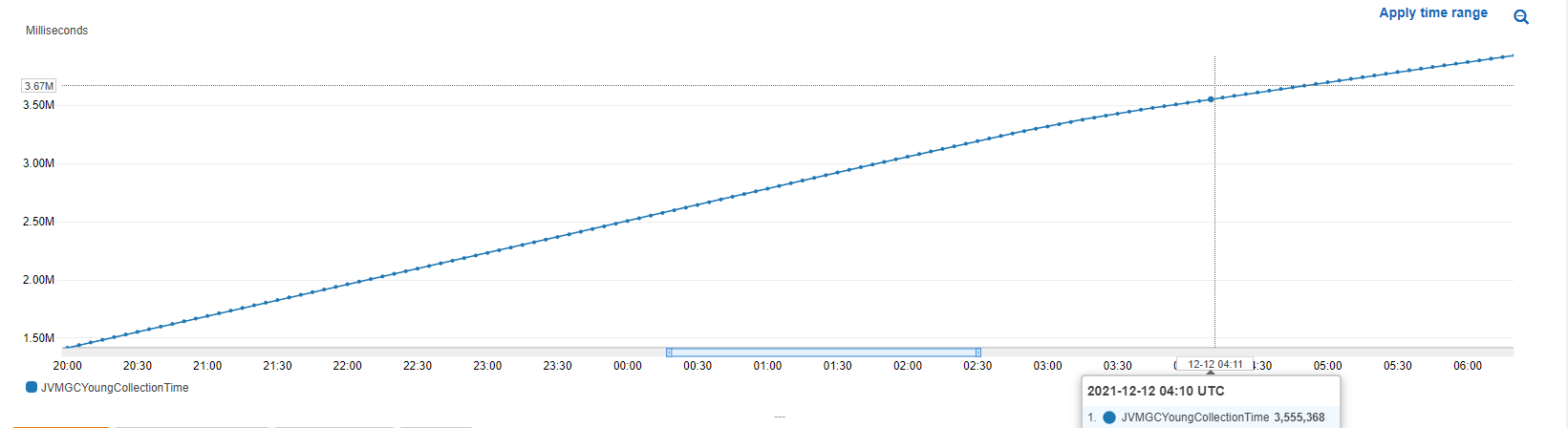
But when looking at memory pressure, I see that I am not passing the 75% mark (but getting near..) which, according to documentation, will trigger a concurrent mark & sweep.

So I fear that once I add more load or run a longer test, I might start seeing real issues which will have an impact on my environment. So, do I have an issue here? how should I approach rising GC time when I cant take memory dumps and see what's going on?
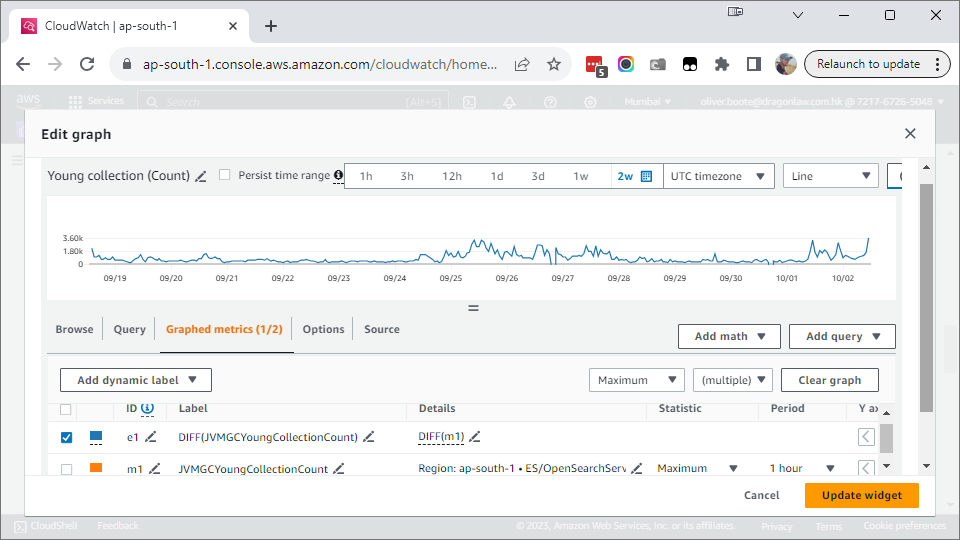{kind=link}
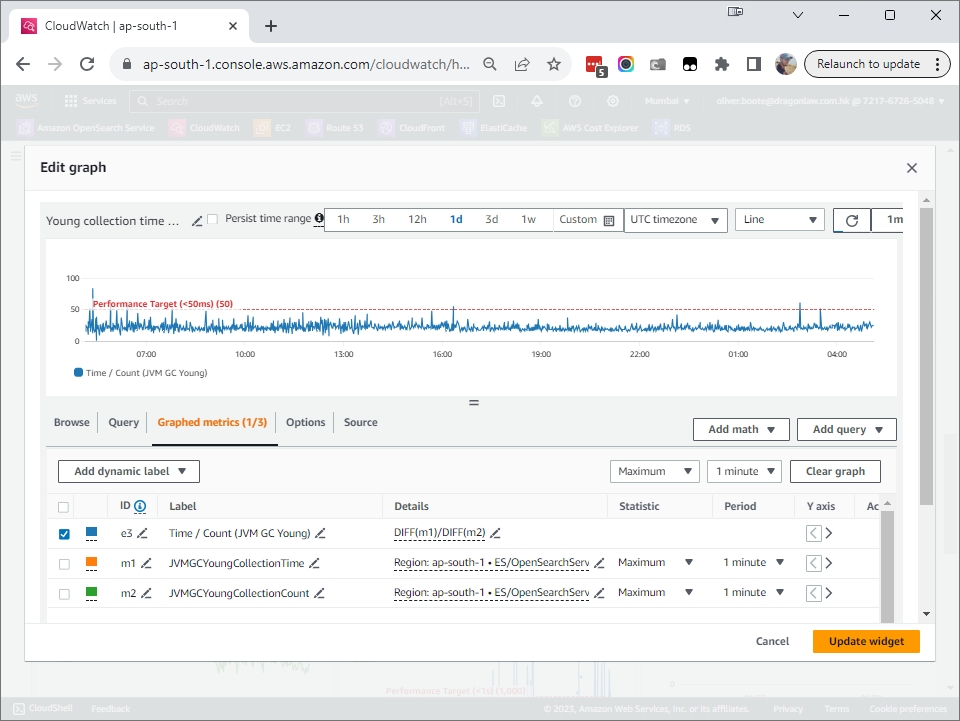{kind=link}