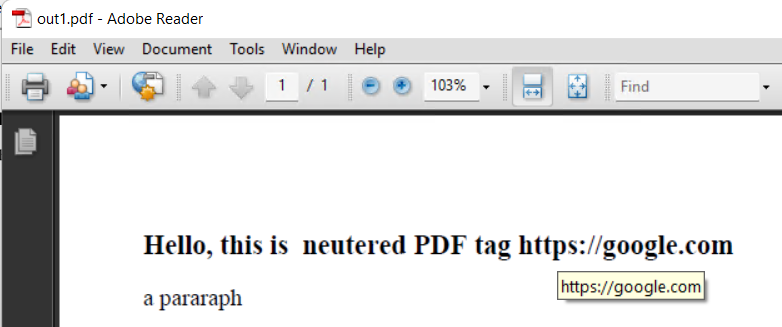
I'm downloading some newspapers as pdf (for posterity). One title is a pain, it includes URI links in the pdf itself, if you accidentally click these it opens a browser tab to a page that 500s. It's not so bad on a desktop computer, but a pain in the butt if someone is reading it with a tablet. Each issues has approximately 200 of these links.
For a different title, it was as simple as using QPDF, like so:
qpdf --qdf --object-streams=disable file temp-file
This puts the temp version into postscript mode or something, and I was able to nuke the links with something like this:
s/obj\n<<\n( \/A <<\n \/S \/URI.+?)>>\nendobj/"obj\n<<\n" . " " x length($1). ">>\nendobj"/sge
This still works. However, a 15 meg original pdf is now becoming a 108meg "fixed" pdf. I can accept some bloat, but 720% is a bit absurd (I think it was more like 10% on the other title). Whenever I google for how to do this, I get results for Acrobat Reader and how you can click around in 20 menus to do such... does no one that uses Adobe products ever want to automate this stuff? There are between 180 and 300 links in a typical issue, spread across 45-150 pages (Sunday editions).
Are there any tools that can do this? Are there any clever arguments to qpdf that will make this more reasonable?
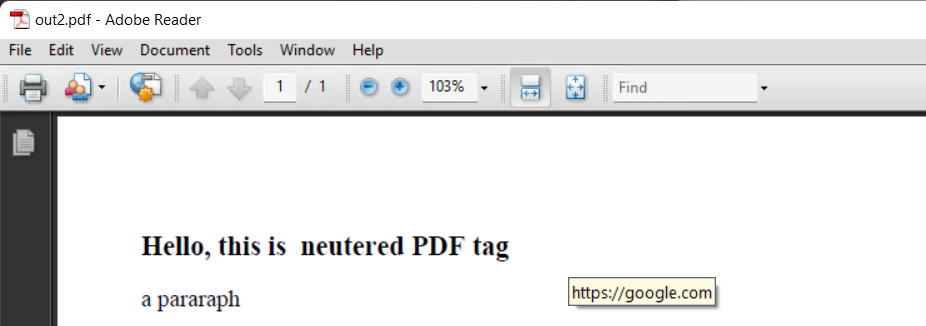
PS Yes I know it's hacky as hell to just overwrite the URIs with spaces, but I've never managed to figure out how to remove the objects entirely since their references also have to be removed.
-output-jsonand-jat the moment, which I forgot to mention in my answer - that would be an alternative method. – Synaesthesia