Another way to construct a context-free grammar for a given regular expression is:
- Construct a finite state machine which accepts the same language as the regular expression.
- Create a grammar whose terminals are those in the alphabet of the regular expression, whose non-terminals are (or correspond 1:1 to) the states in the state machine, and which has a rule of the form
X -> t Y for every state-machine transition from state X to state Y on terminal symbol t. If your CFG notation allows it, each final state F gets a rule of the form F -> epsilon. If your CFG notation doesn't allow such rules, then for each transition from state X to final state F on terminal t, produce the rule X -> t (in addition to the rule X -> t F already described). The result is a regular grammar, a context-free grammar that obeys the additional constraint that each right-hand side has at most one non-terminal.
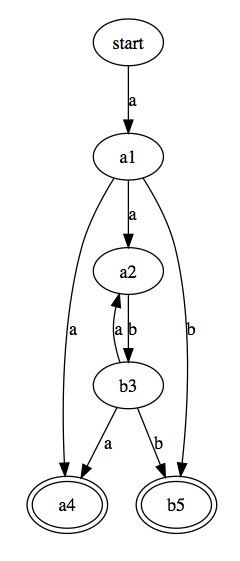
For the example given, assume we construct the following FSA (of the many that accept the same language as the regular expression):
![FSA for language <code>a(ab)*(a|b)</code>]()
From this, it is straightforward to derive the following regular grammar:
S -> a A1
A1 -> a A2
A2 -> b B3
B3 -> a A2
B3 -> a A4
B3 -> b B5
A1 -> a A4
A1 -> b B5
A4 -> epsilon
B5 -> epsilon
epsilon ->
Or, if we don't want rules with an empty right-hand side, drop the last three rules of that grammar and add:
A1 -> a
A1 -> b
B3 -> a
B3 -> b
Compared with other approaches, this method has the disadvantage that the resulting grammar is more verbose than it needs to be, and the advantage that the derivation can be entirely mechanical, which means it's easier to get right without having to think hard.