There's also a classical set of Prolog benchmarks that can be used for comparing Prolog implementations. Some Prolog systems include them (e.g. SWI-Prolog). They are also included in the Logtalk distribution, which allows running them with the supported backends:
https://github.com/LogtalkDotOrg/logtalk3/tree/master/examples/bench
In the current Logtalk git version, you can start it with the backend you want to benchmark and use the queries:
?- {bench(loader)}.
...
?- run.
These will run each benchmark 1000 times are reported the total time. Use run/1 for a different number of repetitions. For example, in my macOS system using SWI-Prolog 8.3.15 I get:
?- run.
boyer: 20.897818 seconds
chat_parser: 7.962188999999999 seconds
crypt: 0.14653999999999812 seconds
derive: 0.004462999999997663 seconds
divide10: 0.002300000000001745 seconds
log10: 0.0011489999999980682 seconds
meta_qsort: 0.2729539999999986 seconds
mu: 0.04534600000000211 seconds
nreverse: 0.016964000000001533 seconds
ops8: 0.0016230000000021505 seconds
poly_10: 1.9540520000000008 seconds
prover: 0.05286200000000463 seconds
qsort: 0.030829000000004214 seconds
queens_8: 2.2245050000000077 seconds
query: 0.11675499999999772 seconds
reducer: 0.00044199999999960937 seconds
sendmore: 3.048624999999994 seconds
serialise: 0.0003770000000073992 seconds
simple_analyzer: 0.8428750000000065 seconds
tak: 5.495768999999996 seconds
times10: 0.0019139999999993051 seconds
unify: 0.11229400000000567 seconds
zebra: 1.595203000000005 seconds
browse: 31.000829000000003 seconds
fast_mu: 0.04102400000000728 seconds
flatten: 0.028527999999994336 seconds
nand: 0.9632950000000022 seconds
perfect: 0.36678499999999303 seconds
true.
For SICStus Prolog 4.6.0 I get:
| ?- run.
boyer: 3.638 seconds
chat_parser: 0.7650000000000006 seconds
crypt: 0.029000000000000803 seconds
derive: 0.0009999999999994458 seconds
divide10: 0.001000000000000334 seconds
log10: 0.0009999999999994458 seconds
meta_qsort: 0.025000000000000355 seconds
mu: 0.004999999999999893 seconds
nreverse: 0.0019999999999997797 seconds
ops8: 0.001000000000000334 seconds
poly_10: 0.20500000000000007 seconds
prover: 0.005999999999999339 seconds
qsort: 0.0030000000000001137 seconds
queens_8: 0.2549999999999999 seconds
query: 0.024999999999999467 seconds
reducer: 0.001000000000000334 seconds
sendmore: 0.6079999999999997 seconds
serialise: 0.0019999999999997797 seconds
simple_analyzer: 0.09299999999999997 seconds
tak: 0.5869999999999997 seconds
times10: 0.001000000000000334 seconds
unify: 0.013000000000000789 seconds
zebra: 0.33999999999999986 seconds
browse: 4.137 seconds
fast_mu: 0.0070000000000014495 seconds
nand: 0.1280000000000001 seconds
perfect: 0.07199999999999918 seconds
yes
For GNU Prolog 1.4.5, I use the sample embedding script in logtalk3/scripts/embedding/gprolog to create an executable that includes the bench example fully compiled:
| ?- run.
boyer: 9.3459999999999983 seconds
chat_parser: 1.9610000000000003 seconds
crypt: 0.048000000000000043 seconds
derive: 0.0020000000000006679 seconds
divide10: 0.00099999999999944578 seconds
log10: 0.00099999999999944578 seconds
meta_qsort: 0.099000000000000199 seconds
mu: 0.012999999999999901 seconds
nreverse: 0.0060000000000002274 seconds
ops8: 0.00099999999999944578 seconds
poly_10: 0.72000000000000064 seconds
prover: 0.016000000000000014 seconds
qsort: 0.0080000000000008953 seconds
queens_8: 0.68599999999999994 seconds
query: 0.041999999999999815 seconds
reducer: 0.0 seconds
sendmore: 1.1070000000000011 seconds
serialise: 0.0060000000000002274 seconds
simple_analyzer: 0.25 seconds
tak: 1.3899999999999988 seconds
times10: 0.0010000000000012221 seconds
unify: 0.089999999999999858 seconds
zebra: 0.63499999999999979 seconds
browse: 10.923999999999999 seconds
fast_mu: 0.015000000000000568 seconds
(27352 ms) yes
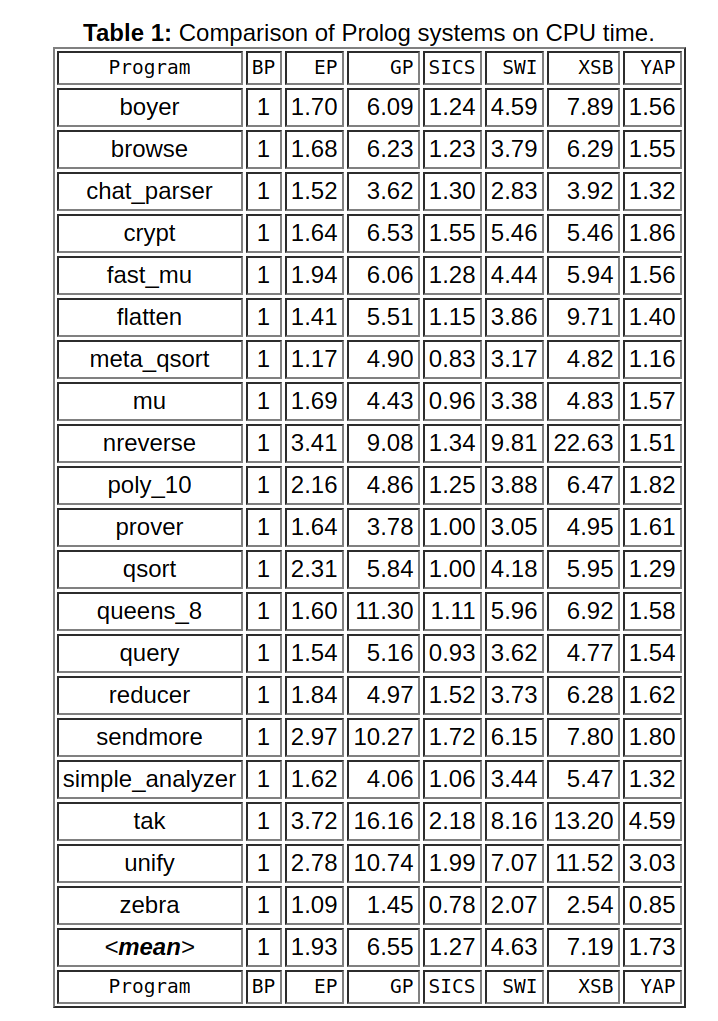
I suggest you try these benchmarks, running them on your computer, with the Prolog systems that you want to compare. In doing that, remember that this is a limited set of benchmarks, not necessarily reflecting the actual relative performance in non-trivial applications.
Ratios:
SICStus/SWI GNU/SWI
boyer 17.4% 44.7%
browse 13.3% 35.2%
chat_parser 9.6% 24.6%
crypt 19.8% 32.8%
derive 22.4% 44.8%
divide10 43.5% 43.5%
fast_mu 17.1% 36.6%
flatten - -
log10 87.0% 87.0%
meta_qsort 9.2% 36.3%
mu 11.0% 28.7%
nand 13.3% -
nreverse 11.8% 35.4%
ops8 61.6% 61.6%
perfect 19.6% -
poly_10 10.5% 36.8%
prover 11.4% 30.3%
qsort 9.7% 25.9%
queens_8 11.5% 30.8%
query 21.4% 36.0%
reducer 226.2% 0.0%
sendmore 19.9% 36.3%
serialise 530.5% 1591.5%
simple_analyzer 11.0% 29.7%
tak 10.7% 25.3%
times10 52.2% 52.2%
unify 11.6% 80.1%
zebra 21.3% 39.8%
P.S. Be sure to use Logtalk 3.43.0 or later as it includes portability fixes for the bench example, including for GNU Prolog, and a set of basic unit tests.
occurs checknot being active. If you can show a specific case where theoccurs checkis needed for a real world problem you need then I would reconsider. I do like many of your questions but this one could lead others to believe that theoccurs checkis always needed. – Xenonrecuris just a syntactic choice (something about being more explicit) In Kotlin or Kawa a function just refers to itself. The difficulties of proper tail call optimization didn't stop the users of Clojure, BTW. – Quickman