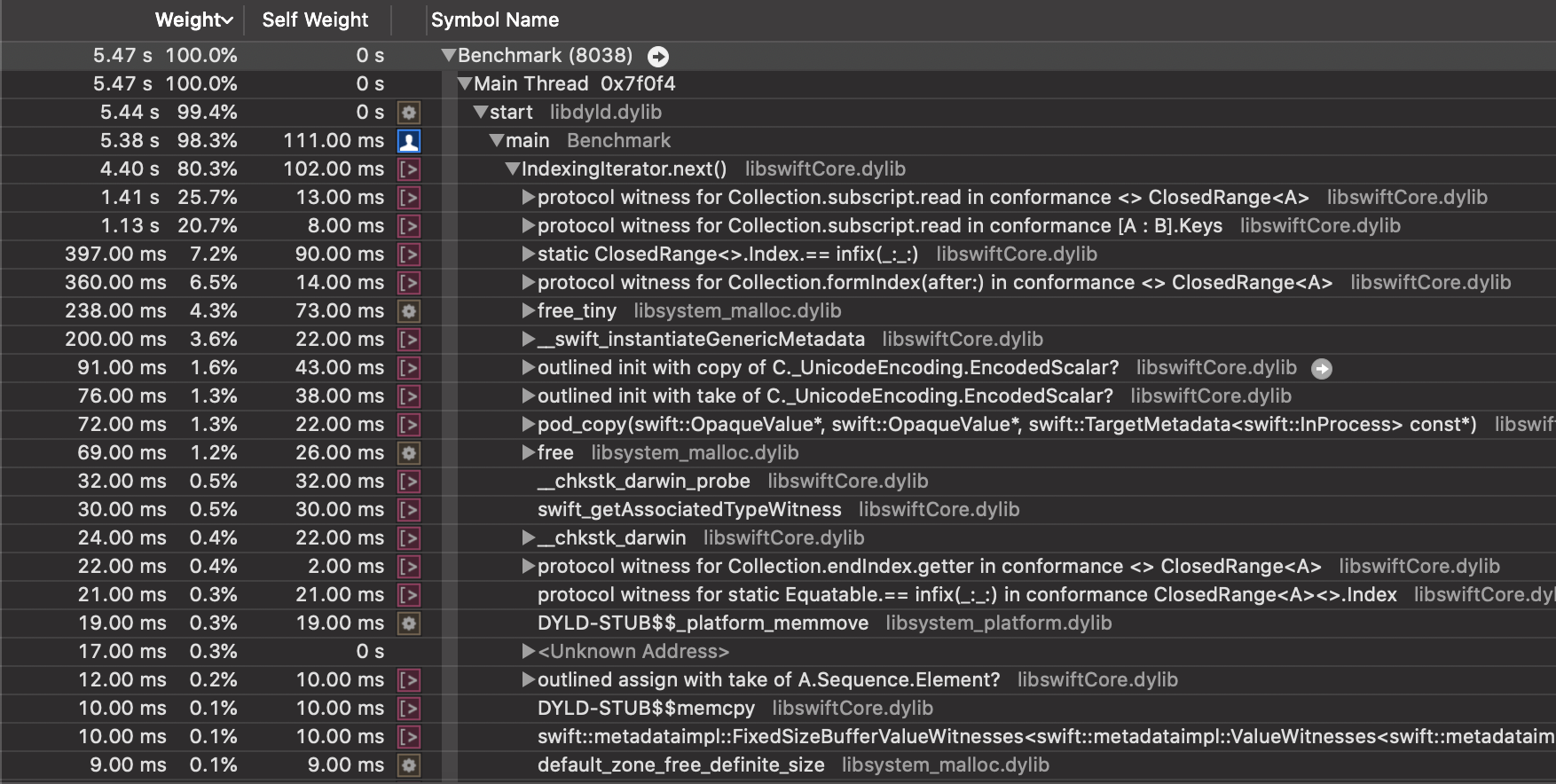
Why is for-in slower than while in swift debugging mode ? If you think, yes It was ran in no optimization.
⬇️Below code, Time is compare of for-in and while in no optimization
49999995000000 for-in -- time = 3.3352
4999999950000000 while -- time = 0.3613
⬇️but, If using optimization for speed
49999995000000 for-in -- time = 0.0037
49999995000000 while -- time = 0.0035
I wonder that "why is for-in slower than while in no optimization? and why are for-in and while so fast in optimization? "
import Foundation
func processTime(_ title: String, blockFunction: () -> ()) {
print()
let startTime = CFAbsoluteTimeGetCurrent()
blockFunction()
let processTime = CFAbsoluteTimeGetCurrent() - startTime
print(title, " -- time = \(String(format : "%.4f",processTime))")
}
processTime("for-in") {
var sum = 0
for i in 0..<10000000 {
sum += i
}
print(sum)
}
processTime("while") {
var sum = 0
var i = 0
while i<10000000 {
sum += i
i += 1
}
print(sum)
}