This seems relatively straight forward, but I have yet to find a duplicate that answers my question, or a method with the needed functionality.
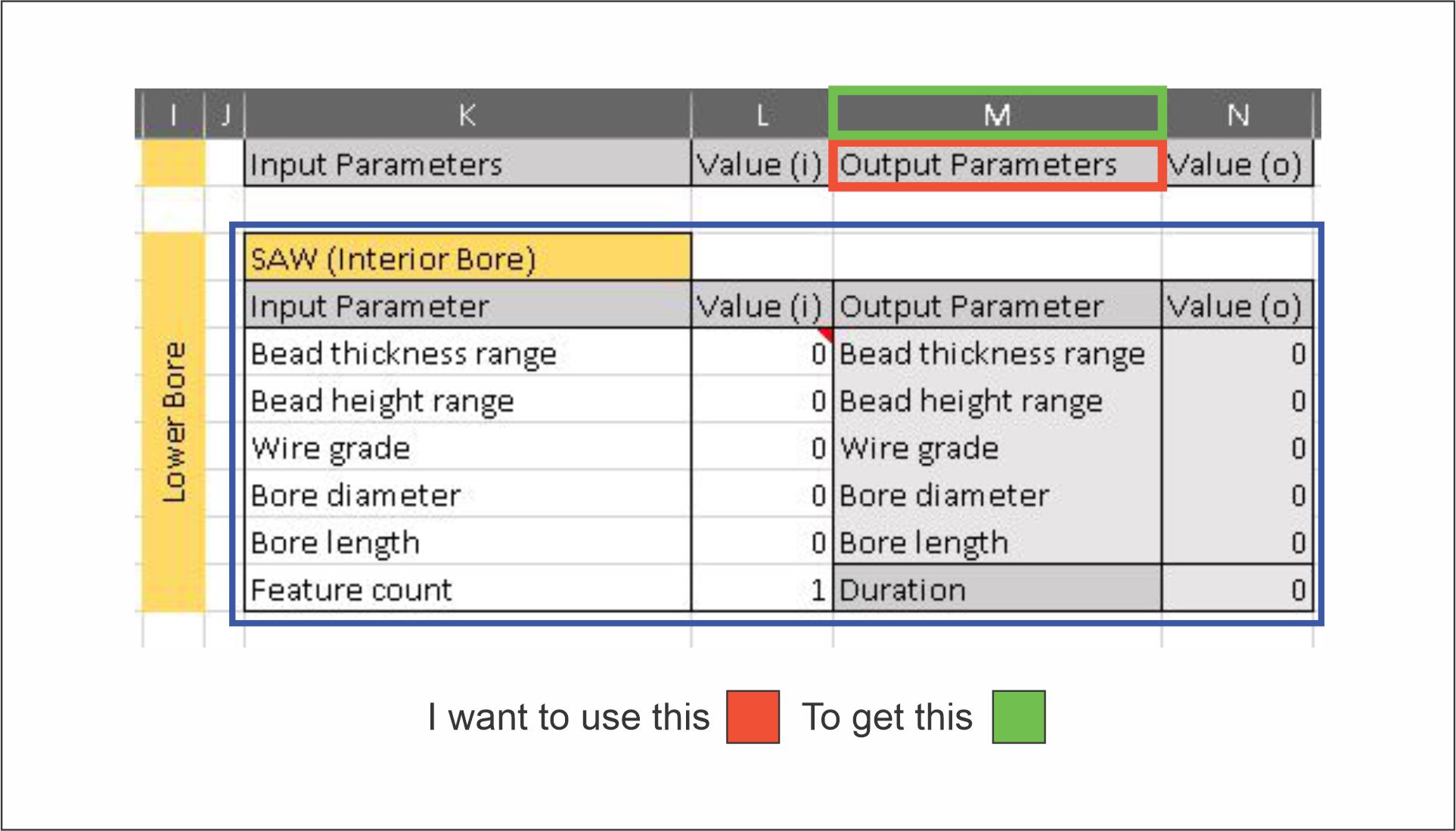
I have an Excel spreadsheet where each column that contains data has a unique header. I would like to use pandas to get the letter key of the column by passing this header string into a function.
For example, if I pass "Output Parameters" to the function, I would like to return "M":
The closest thing that I have found is the xlsxwriter.utility.xl_col_to_name(index) method outlined in the second answer in Convert spreadsheet number to column letter
This is very similar to what I am trying to do, however the column numbers within my sheets will not remain constant (unlike the headers, which will). This being said, a method that can return the column number based on the header would also work, as I would then be able to apply the above.
Does pandas or xlsxwriter have a method that can handle the above case?
usecolsto select the columns andskiprowsto omit some rows, would you want to return the oiriginal column letters? Or just treat the first column in the dataframe as column "A" – Halfbackusecols=["B:E"], xlsxwriter will identify the first col as"A"as it would be if the dataframe were written to a new spreadsheet. – Halfbackusecols=D:Gparams would let you load in just those cols. If you then saved the df, or usedxlsxwriter.utility.xl_col_to_nameon the dataframe, it would return as a sheet with cols A:D. I was trying to clarify if you needed to identify the columns from the original spreadsheet. – Halfbackxlsxwriterutility function is doing it taking a column index number retrieved from the dataframe and converting it to a column name form: github.com/jmcnamara/XlsxWriter/blob/… – Halfback