My goal is to collect logs from Java (Spring Boot) applications running on Bare Kubernetes. These logs are then translated into ES and visualized in Kibana.
For these purposes I deployed Fleunt Bit 1.8.9 via Kubernetes 1.22. Since I use Containerd instead for Docker, then my Fluent Bit configuration is as follow (Please note that I have only specified one log-file):
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE filter-kubernetes.conf
@INCLUDE output-elasticsearch.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Read_from_head true
Parser cri
filter-kubernetes.conf: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
output-elasticsearch.conf: |
[OUTPUT]
Name es
Match kube.*
Host ${FLUENT_ELASTICSEARCH_HOST}
Port ${FLUENT_ELASTICSEARCH_PORT}
Index kube-code_index
Type kube-code_type
parsers.conf: |
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
With this configuration in Kibana, the Java stack trace messages are displayed unstructured:
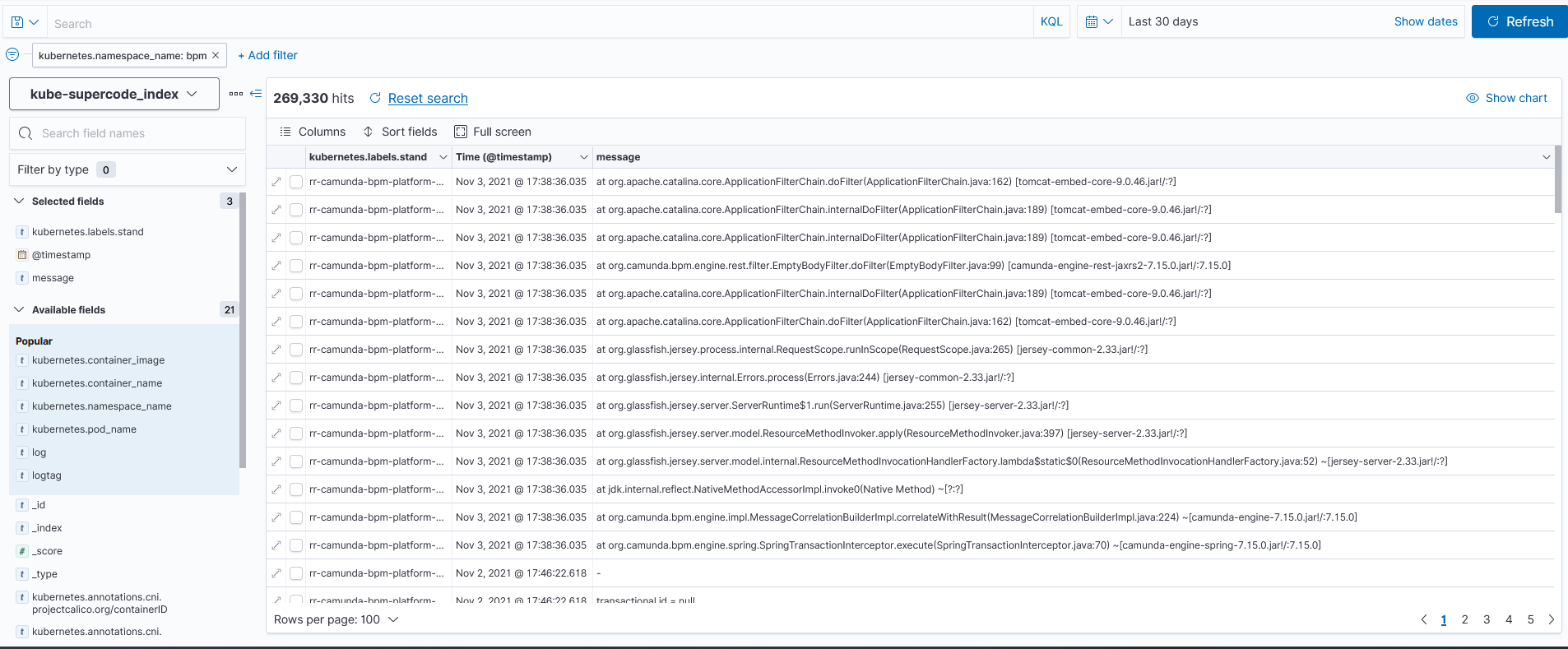
But I need the Java stack trace to be structured like in the screenshot below:
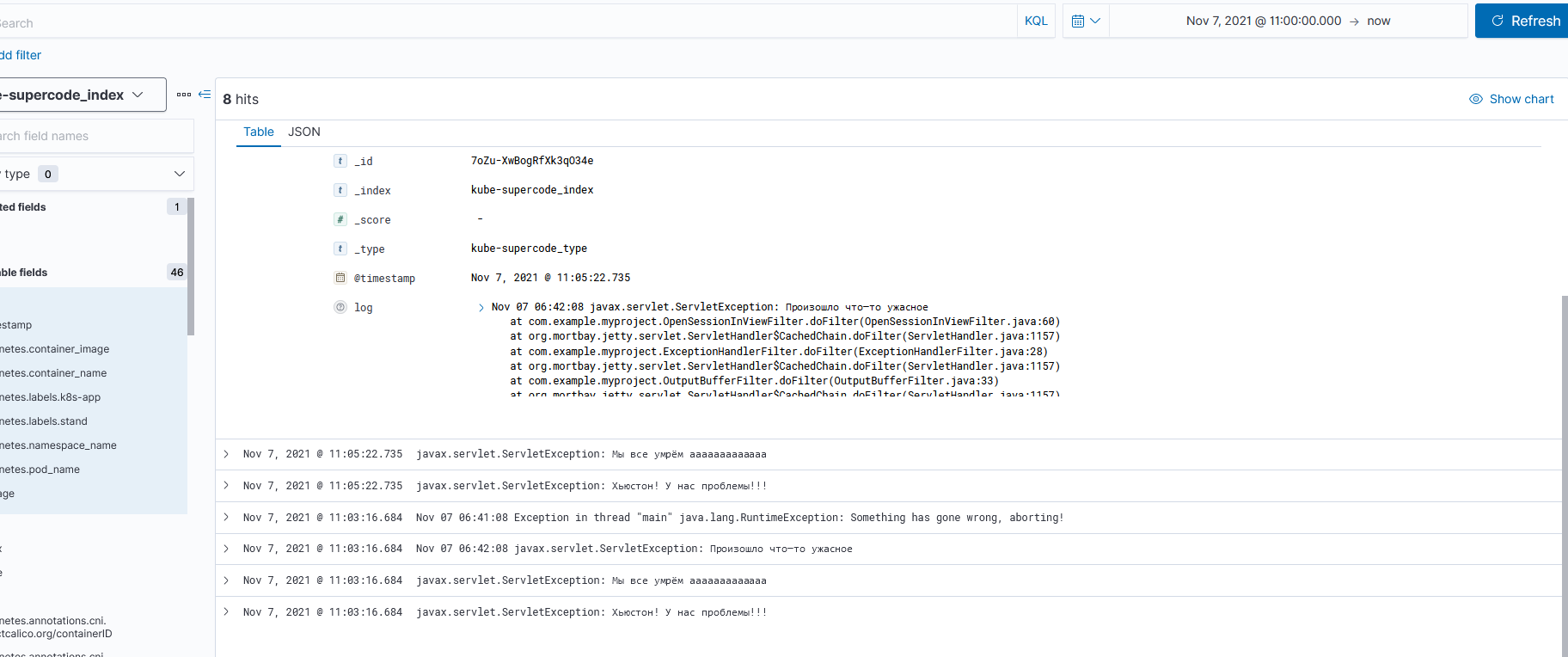
I tried a configuration like this:
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Read_from_head true
Multiline.parser cri, multiline-regex-cri
And:
parsers.conf: |
[PARSER]
# http://rubular.com/r/tjUt3Awgg4
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[MULTILINE_PARSER]
name multiline-regex-cri
type regex
flush_timeout 1000
#
# Regex rules for multiline parsing
# ---------------------------------
#
# configuration hints:
#
# - first state always has the name: start_state
# - every field in the rule must be inside double quotes
#
# rules | state name | regex pattern | next state
# ------|---------------|--------------------------------------------
rule "start_state" "/(\D+ \d+ \d+\:\d+\:\d+)(.*)/" "cont"
rule "cont" "/^\s+at.*/" "cont"
But all the same, the logs are not structured:
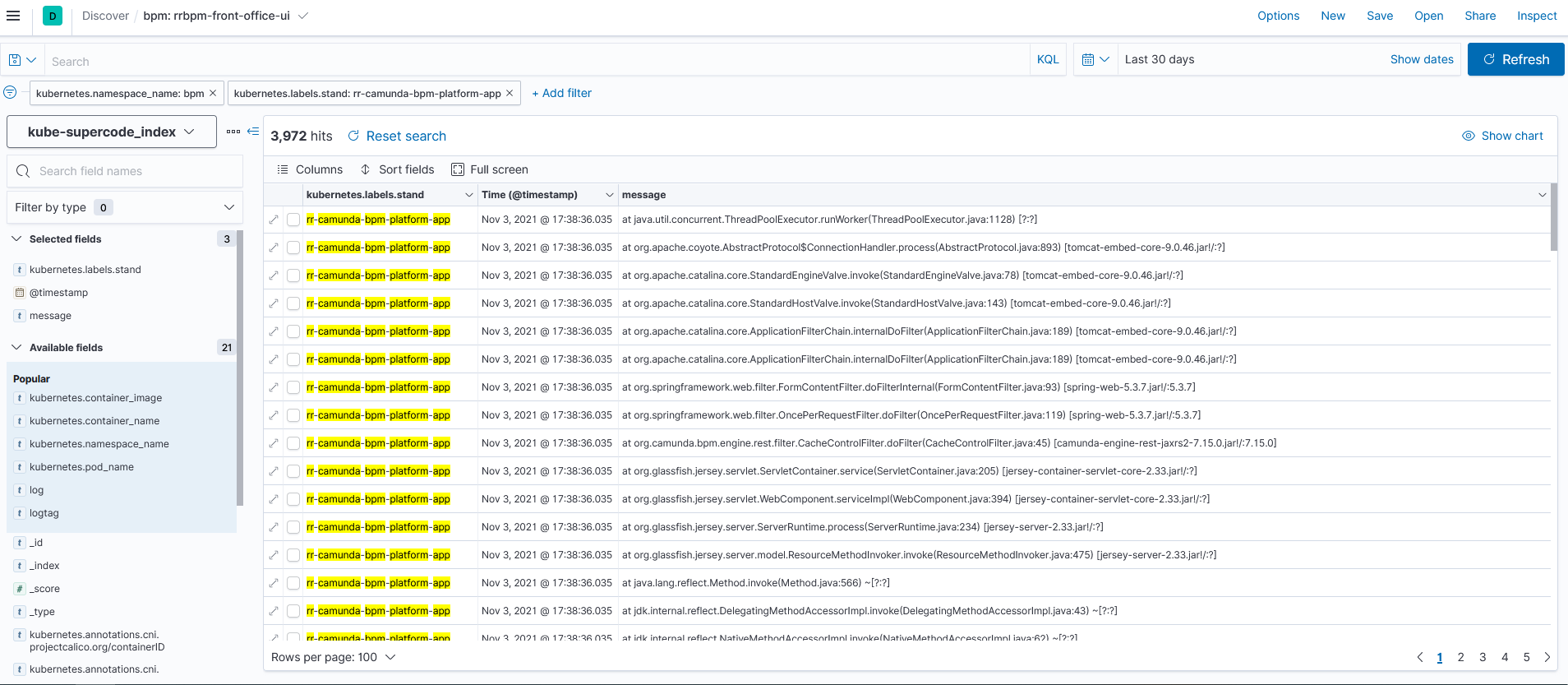
Please help me structure the logs.