A few issues:
while (fscanf(dict, "%s", word) != EOF) is wrong. You want: while (fscanf(dict, "%s", word) == 1)- Faster to store the given word into the table as uppercase. (i.e.) We do
toupper only once for each word.
- The
check function will be faster because it can [then] use strcmp instead of strcasecmp [which is slower]
- If we can add fields to the
node struct, we can have it hold a hash value. This can speed up the check function (see NODEHASH in code below).
- Doing a
malloc for each node is slow/wasteful. A pooled/arena/slab allocator can be faster (see FASTALLOC in code below). Again, if we can add a field to the node struct.
There are some other bugs that are documented in the code below (see the "NOTE" comments). I've used cpp conditionals to denote old vs. new code:
#if 0
// old code
#else
// new code
#endif
#if 1
// new code
#endif
Here is the refactored code. I've compiled it but not tested it:
// Implements a dictionary's functionality
#include <ctype.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <strings.h>
//#include "dictionary.h"
// NOTE/BUG: dictionary.h was _not_ posted, so we have to guess
#define LENGTH 20
#ifndef NODEHASH
#define NODEHASH 1
#endif
#ifndef FASTALLOC
#define FASTALLOC 1
#endif
// Represents a node in a hash table
typedef struct node {
char word[LENGTH + 1];
struct node *next;
#if NODEHASH
unsigned int hash;
#endif
#if FASTALLOC
int alloc;
#endif
} node;
//Prototypes
unsigned int hash(const char *word);
// TODO: Choose number of buckets in hash table
// odd prime number bigger than word count, because math
// NOTE/BUG: this doesn't work too well for C (may be okay in C++) when used
// as dimension for table below
// NOTE/BUG: enum may be faster in calculations
#if 0
const unsigned int N = 187751;
#else
enum {
N = 187751
};
#endif
// Hash table
node *table[N]; // may need to use calloc
//word count
int word_count = 0;
// Returns true if word is in dictionary, else false
bool
check(const char *word)
{
// TODO
// debug
// int hashcode = hash(word);
// printf("bucket: %i, word: %s\n", hash(word), table[hash(word)]->word);
#if 1
unsigned int hval = hash(word);
#endif
// iterate through bucket
for (node *tmp = table[hval]; tmp != NULL; tmp = tmp->next) {
#if NODEHASH
// check hash value first -- limits number of str*cmp calls
if (tmp->hash != hval)
continue;
#endif
// compare strings
// NOTE/BUG: strcasecmp is _slow_ and if we _store_ uppercase we don't need it
#if 0
if (strcasecmp(tmp->word, word) == 0) {
return true;
}
#else
if (strcmp(tmp->word, word) == 0)
return true;
#endif
}
return false;
}
// Hashes word to a number
unsigned int
hash(const char *word)
{
// TODO: Improve this hash function
// Used Data Structures youtube course of Dr. Rob Edwards from San Diego State University mostly
int hash = 0;
/* int w = 0; //convert to upper case while (word[w] != '\0') { word[w] = toupper(word[w]); w++; } */
// NOTE/BUG: _without_ optimization this is O(n^2) instead of O(n) because it
// calls strlen on _each_ loop iteration
#if 0
for (int i = 0; i <= strlen(word); i++) {
hash = (31 * hash + toupper(word[i])) % N; // 31 because math
// check hash size
/* if (hash >= N) { printf("incorrect hash!"); } */
}
#else
for (int chr = *word++; chr != 0; chr = *word++)
hash = (31 * hash + chr) % N; // 31 because math
#endif
return hash;
}
#if FASTALLOC
node *freelist = NULL;
int freecount = 0;
// adjust this value to suit
#define ARENASIZE 1000
// newnode -- allocate from pool
node *
newnode(void)
{
node *cur;
while (1) {
// get node from free list cache
cur = freelist;
// use the cached node if possible
if (cur != NULL) {
freelist = cur->next;
break;
}
// allocate a new arena
freelist = malloc(sizeof(node) * ARENASIZE);
// out of memory
if (freelist == NULL)
break;
// link all nodes in the arena
node *prev = NULL;
for (cur = freelist; cur < &freelist[ARENASIZE]; ++cur) {
cur->alloc = 0;
cur->next = prev;
prev = cur;
}
// mark the arena head
freelist->alloc = 1;
}
return cur;
}
#endif
// Loads dictionary into memory, returning true if successful, else false
bool
load(const char *dictionary)
{
// TODO
// open dictionary file
FILE *dict = fopen(dictionary, "r");
if (dict == NULL) {
// printf("Could not open file.\n");
return false;
}
// create temp string for word
// NOTE/BUG: no need to malloc this (and it is slightly slower)
#if 0
char *word = malloc(LENGTH + 1);
if (word == NULL) {
return false;
}
#else
char word[LENGTH + 1];
#endif
// read words from dictionary and write to hash table
// NOTE/BUG: this scanf is wrong (and may loop too much)
#if 0
while (fscanf(dict, "%s", word) != EOF) {
#else
while (fscanf(dict, "%s", word) == 1) {
#endif
// node *tmp_word = NULL;
#if FASTALLOC
node *n = newnode();
#else
node *n = malloc(sizeof(node));
#endif
if (n == NULL)
return false;
// NOTE/FIX: convert to uppercase _once_
int idx;
for (idx = 0; word[idx] != 0; ++idx)
n->word[idx] = toupper(word[idx] & 0xFF);
n->word[idx] = 0;
// run hash to find the bucket in table
// NOTE/BUG: pos should be unsigned
#if 0
int pos = hash(word);
#else
unsigned int pos = hash(n->word);
#endif
#if 0
strcpy(n->word, word); // write word to temp node
#endif
#if NODEHASH
n->hash = pos;
#endif
// NOTE/BUG: no need to check table[pos]
#if 0
// check if node is first in bucket
// (may need to use calloc to create a table)
if (table[pos] == NULL)
{
n->next = NULL;
}
// if not the first, write node to the head
else
{
n->next = table[pos]; // reference first node
}
#else
n->next = table[pos];
#endif
table[pos] = n; // write node to table
word_count++; // count new word
}
fclose(dict);
#if 0
free(word);
#endif
// debug
/* int j = 0; while (j <= 11) { for (node *tmp = table[j]; tmp != NULL; tmp = tmp->next) //делаем ноду; пока не дойдем до последней; переходим к следующей { printf("%s\n", tmp->word); //забираем значение ноды
} printf("Bucket number: %i\n", j); j++; } */
// printf("word count:%i\n", word_count);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int
size(void)
{
return word_count;
}
// Unloads dictionary from memory, returning true if successful, else false
#if ! FASTALLOC
bool
unload(void)
{
// TODO
// NOTE/BUG: this goes one beyond the table end (i.e. want: i < N)
#if 0
for (int i = 0; i <= N; i++) {
while (table[i] != NULL) {
node *tmp = table[i]->next; // делаем ноду и переходим на следующую ячейку
free(table[i]); // освобождаем текущую
table[i] = tmp; // начинаем list со второй ячейки
}
}
#else
for (int i = 0; i < N; ++i) {
node *cur = table[i];
if (cur == NULL)
continue;
node *next;
for (; cur != NULL; cur = next) {
next = cur->next;
free(cur);
}
#endif
return true;
}
#endif
// Unloads dictionary from memory, returning true if successful, else false
#if FASTALLOC
bool
unload(void)
{
node *cur;
node *next;
// remove all nodes from the table
for (int i = 0; i < N; ++i) {
cur = table[i];
if (cur == NULL)
continue;
// put all nodes in hash table back on [cached] free list
for (; cur != NULL; cur = next) {
next = cur->next;
cur->next = freelist;
freelist = cur;
}
table[i] = NULL;
}
cur = freelist;
freelist = NULL;
// trim free list to allocation/arena heads
for (; cur != NULL; cur = next) {
next = cur->next;
if (cur->alloc) {
cur->next = freelist;
freelist = cur;
}
}
// free the allocated nodes
cur = freelist;
freelist = NULL;
for (; cur != NULL; cur = next) {
next = cur->next;
free(cur);
}
return true;
}
#endif
Here's a cleaned up version of the above (I ran it through unifdef):
// Implements a dictionary's functionality
#include <ctype.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <strings.h>
//#include "dictionary.h"
// NOTE/BUG: dictionary.h was _not_ posted, so we have to guess
#define LENGTH 20
// Represents a node in a hash table
typedef struct node {
char word[LENGTH + 1];
struct node *next;
unsigned int hash;
int alloc;
} node;
//Prototypes
unsigned int hash(const char *word);
// TODO: Choose number of buckets in hash table
// odd prime number bigger than word count, because math
enum {
N = 187751
};
// Hash table
node *table[N]; // may need to use calloc
//word count
int word_count = 0;
// Returns true if word is in dictionary, else false
bool
check(const char *word)
{
// TODO
// debug
// int hashcode = hash(word);
// printf("bucket: %i, word: %s\n", hash(word), table[hash(word)]->word);
unsigned int hval = hash(word);
// iterate through bucket
for (node *tmp = table[hval]; tmp != NULL; tmp = tmp->next) {
// check hash value first -- limits number of str*cmp calls
if (tmp->hash != hval)
continue;
// compare strings
if (strcmp(tmp->word, word) == 0)
return true;
}
return false;
}
// Hashes word to a number
unsigned int
hash(const char *word)
{
// TODO: Improve this hash function
// Used Data Structures youtube course of Dr. Rob Edwards from San Diego State University mostly
int hash = 0;
/* int w = 0; //convert to upper case while (word[w] != '\0') { word[w] = toupper(word[w]); w++; } */
for (int chr = *word++; chr != 0; chr = *word++)
hash = (31 * hash + chr) % N; // 31 because math
return hash;
}
node *freelist = NULL;
int freecount = 0;
// adjust this value to suit
#define ARENASIZE 1000
// newnode -- allocate from pool
node *
newnode(void)
{
node *cur;
while (1) {
// get node from free list cache
cur = freelist;
// use the cached node if possible
if (cur != NULL) {
freelist = cur->next;
break;
}
// allocate a new arena
freelist = malloc(sizeof(node) * ARENASIZE);
// out of memory
if (freelist == NULL)
break;
// link all nodes in the arena
node *prev = NULL;
for (cur = freelist; cur < &freelist[ARENASIZE]; ++cur) {
cur->alloc = 0;
cur->next = prev;
prev = cur;
}
// mark the arena head
freelist->alloc = 1;
}
return cur;
}
// Loads dictionary into memory, returning true if successful, else false
bool
load(const char *dictionary)
{
// TODO
// open dictionary file
FILE *dict = fopen(dictionary, "r");
if (dict == NULL) {
// printf("Could not open file.\n");
return false;
}
// create temp string for word
// NOTE/BUG: no need to malloc this (and it is slightly slower)
char word[LENGTH + 1];
// read words from dictionary and write to hash table
// NOTE/BUG: this scanf is wrong (and may loop too much)
while (fscanf(dict, "%s", word) == 1) {
// node *tmp_word = NULL;
node *n = newnode();
if (n == NULL)
return false;
// NOTE/FIX: convert to uppercase _once_
int idx;
for (idx = 0; word[idx] != 0; ++idx)
n->word[idx] = toupper(word[idx] & 0xFF);
n->word[idx] = 0;
// run hash to find the bucket in table
// NOTE/BUG: pos should be unsigned
unsigned int pos = hash(n->word);
n->hash = pos;
// NOTE/BUG: no need to check table[pos]
n->next = table[pos];
table[pos] = n; // write node to table
word_count++; // count new word
}
fclose(dict);
// debug
/* int j = 0; while (j <= 11) { for (node *tmp = table[j]; tmp != NULL; tmp = tmp->next) //делаем ноду; пока не дойдем до последней; переходим к следующей { printf("%s\n", tmp->word); //забираем значение ноды
} printf("Bucket number: %i\n", j); j++; } */
// printf("word count:%i\n", word_count);
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int
size(void)
{
return word_count;
}
// Unloads dictionary from memory, returning true if successful, else false
bool
unload(void)
{
node *cur;
node *next;
// remove all nodes from the table
for (int i = 0; i < N; ++i) {
cur = table[i];
if (cur == NULL)
continue;
// put all nodes in hash table back on [cached] free list
for (; cur != NULL; cur = next) {
next = cur->next;
cur->next = freelist;
freelist = cur;
}
table[i] = NULL;
}
cur = freelist;
freelist = NULL;
// trim free list to allocation/arena heads
for (; cur != NULL; cur = next) {
next = cur->next;
if (cur->alloc) {
cur->next = freelist;
freelist = cur;
}
}
// free the allocated nodes
cur = freelist;
freelist = NULL;
for (; cur != NULL; cur = next) {
next = cur->next;
free(cur);
}
return true;
}
UPDATE #2:
I've already submitted my version. Just trying to understand the subject better. –
meotet
Okay, because of that, I've produced a final version that is my best effort for speed. I did more refactoring than I would if you were still working on it.
Things to note ...
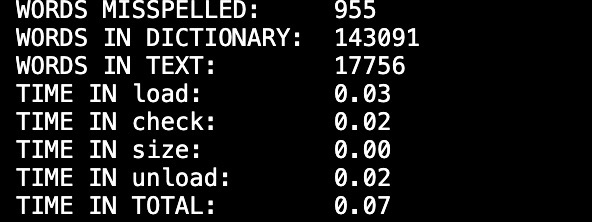
Doing a single malloc for each node is wasteful. malloc is relatively slow. Note that in your benchmark timings, it was largely the load phase that was slower than the staff implementation.
Also, there is a hidden struct that malloc places in the memory immediately before the pointer it returns that it uses for keeping track of the allocations. This struct takes up space and for small allocations like the node struct, the extra memory overhead can be significant.
Better to call malloc and allocate a large number of node structs in a contiguous chunk or array. Further allocations can come from within that chunk.
This is similar to "slab allocation", "object pools", or "memory pools":
https://en.wikipedia.org/wiki/Slab_allocation
https://en.wikipedia.org/wiki/Object_pool_pattern
https://en.wikipedia.org/wiki/Memory_pool
In the code below, nodes are allocated in chunks of 1000. This reduces the number of malloc calls from 100,000 to approximately 100. This version has improved speed over my last allocator because it uses an extra "segment" (aka "arena") struct to control allocations. It no longer needs to prelink each node struct into a "freelist" or keep track of whether a node is the first node in a given piece of memory received from malloc.
No need to do toupper/tolower when reading the dictionary. Because the dictionary is guaranteed to be all lowercase and have only one word per line, it is faster to use fgets to read the dictionary. We can read the dictionary word directly into the word field of a given node struct [if we do the node allocation before doing the fgets].
When computing the hash, we don't need to do % N on each iteration. Due to the nature of modular arithmetic, we can do the remainder operation once at the end.
We can also store the hash value into the node struct. Then, in check we can compare the hash values and skip some [expensive] strcmp calls. In your code, because N is so large, most hash buckets only have one or two entries, so this speedup may have little effect [and may be slightly slower].
In check, it's better to copy the argument word into a temporary buffer, lowercasing as we go once. Then, we can use the faster strcmp instead of the slower strcasecmp. This works regardless of whether we store the hash value in the node struct or not. Again, because of the large N value, this speedup may be of limited effect.
Anyway, here is the refactored code:
// fix2.c -- Implements a dictionary's functionality
#include <ctype.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <strings.h>
#include "dictionary.h"
#if _USE_ZPRT_
#define dbgprt(_fmt...) printf(_fmt)
#else
#define dbgprt(_fmt...) do { } while (0)
#endif
#ifndef NODEHASH
#define NODEHASH 1
#endif
#ifndef FASTNODE
#define FASTNODE 1
#endif
// Represents a node in a hash table
typedef struct node {
char word[LENGTH + 1 + 1];
struct node *next;
#if NODEHASH
unsigned int hash;
#endif
} node;
//Prototypes
unsigned int hash(const char *word);
// TODO: Choose number of buckets in hash table
// odd prime number bigger than word count, because math
#ifndef N
#define N 187751
#endif
// Hash table
node *table[N]; // may need to use calloc
// word count
int word_count = 0;
// 31 because math
// modulus only really needed to clip hash to table index
// so do it _once_ by caller of hash/hash2
#if 0
#define HASH \
hash = (31 * hash + chr) % N
#else
#define HASH \
hash = (31 * hash) + chr
#endif
// Hashes word to a number and copies lowercase chars to output buffer
unsigned int
hash2(char *dest,const char *word)
{
unsigned int hash = 0;
for (int chr = *word++; chr != 0; chr = *word++) {
chr = tolower((unsigned char) chr);
HASH;
*dest++ = chr;
}
*dest = 0;
return hash;
}
// Returns true if word is in dictionary, else false
bool
check(const char *word)
{
char tmp[LENGTH + 10];
unsigned int hval = hash2(tmp,word);
unsigned int hidx = hval % N;
// iterate through bucket
for (node *cur = table[hidx]; cur != NULL; cur = cur->next) {
// check hash value first -- limits number of str*cmp calls
#if NODEHASH
if (cur->hash != hval)
continue;
#endif
if (strcmp(cur->word, tmp) == 0)
return true;
}
return false;
}
// Hashes word to a number
unsigned int
hash(const char *word)
{
unsigned int hash = 0;
for (int chr = *word++; chr != 0; chr = *word++)
HASH;
return hash;
}
// adjust this value to suit
#ifndef ARENASIZE
#define ARENASIZE 1000
#endif
typedef struct seg seg_t;
struct seg {
seg_t *seg_next; // next segment
int seg_count; // number of used nodes in this segment
node seg_node[ARENASIZE]; // nodes in this segment
};
node *nodelist; // list of freed nodes
seg_t *seglist; // head of linked list of segments
// newnode -- allocate from pool
node *
newnode(void)
{
seg_t *seg;
node *cur;
while (1) {
// get node from free node cache
// use the cached node if possible
// this only happens if freenode were called [which it isn't]
cur = nodelist;
if (cur != NULL) {
nodelist = cur->next;
break;
}
// try to allocate from current segment
seg = seglist;
if (seg != NULL) {
if (seg->seg_count < ARENASIZE) {
cur = &seg->seg_node[seg->seg_count++];
break;
}
}
// allocate a new segment
seg = malloc(sizeof(*seg));
// out of memory
if (seg == NULL)
break;
// mark segment as completely unused
seg->seg_count = 0;
// attach to segment list
seg->seg_next = seglist;
seglist = seg;
}
return cur;
}
// freenode -- free a node
void
freenode(node *cur)
{
#if FASTNODE
cur->next = nodelist;
nodelist = cur;
#else
free(cur);
#endif
}
// segunload -- release all segments
void
segunload(void)
{
seg_t *seg;
seg_t *next;
seg = seglist;
seglist = NULL;
for (; seg != NULL; seg = next) {
next = seg->seg_next;
free(seg);
}
}
// Unloads dictionary from memory, returning true if successful, else false
bool
unload(void)
{
node *cur;
// remove all nodes from the table
for (int i = 0; i < N; ++i) {
cur = table[i];
// put all nodes in hash table back on [cached] free list
// NOTE: not really necessary
#if FASTNODE
word_count = 0;
cur = NULL;
#else
node *next;
for (; cur != NULL; cur = next, --word_count) {
next = cur->next;
freenode(cur);
}
#endif
table[i] = cur;
}
segunload();
return true;
}
// Loads dictionary into memory, returning true if successful, else false
bool
load(const char *dictionary)
{
// open dictionary file
FILE *dict = fopen(dictionary, "r");
if (dict == NULL)
return false;
// read words from dictionary and write to hash table
while (1) {
#if FASTNODE
node *n = newnode();
#else
node *n = malloc(sizeof(*n));
#endif
if (n == NULL)
return false;
char *word = n->word;
if (fgets(word,sizeof(n->word),dict) == NULL) {
freenode(n);
break;
}
// strip newline
#if 0
word += strlen(word);
if (--word >= n->word) {
if (*word == '\n');
*word = 0;
}
#else
word = strchr(word,'\n');
if (word != NULL)
*word = 0;
#endif
// run hash to find the bucket in table
unsigned int pos = hash(n->word);
#if NODEHASH
n->hash = pos;
#endif
// put node in hash table
pos %= N;
n->next = table[pos];
table[pos] = n;
word_count++;
}
fclose(dict);
// DEBUG: show the bucket counts
#if _USE_ZPRT_
node *cur;
int mincount = 0;
int maxcount = 0;
int buckcount = 0;
int totcount = 0;
for (int i = 0; i < N; ++i) {
cur = table[i];
if (cur == NULL)
continue;
int count = 0;
for (; cur != NULL; cur = cur->next)
++count;
printf("load: BUCKET/%d count=%d\n",i,count);
if (i == 0) {
mincount = count;
maxcount = count;
}
if (count < mincount)
mincount = count;
if (count > maxcount)
maxcount = count;
totcount += count;
++buckcount;
}
printf("load: TOTAL buckcnt=%d/%d mincount=%d maxcount=%d avgcount=%d/%d\n",
buckcount,N,mincount,maxcount,totcount / buckcount,totcount / N);
#endif
return true;
}
// Returns number of words in dictionary if loaded, else 0 if not yet loaded
unsigned int
size(void)
{
return word_count;
}


while (fscanf(dict, "%s", word) != EOF)is wrong. You want:while (fscanf(dict, "%s", word) == 1)– Triton