I already did the implementation of the CNN part and everything seems to be working just fine. Afterwards started to implement the LSTM part and, If I understood it right, the output shape should be (batch_size, 256) (because it's bidirectional, 1 layer and 128 units). Guess everything is alright either.
But what I am trying to figure out is how to implement that attention layer. To my understanding, is basically a weight tensor that will be multiplied by the LSTM output, then applies the softmax function and feed it to the final linear layer. My questions are:
Did I understand it right? Is that simple?
What is the size of the weight tensor?
(128), (256), (2, 128)or something else?How to do the tensor multiplication properly? At my first try I created the weight tensor as a torch Linear with equal values for in_features and out_features (256). After that I applied
torch.multo the input (LSTM output) and the weights. Is that right?
Model Architecture Fig 1
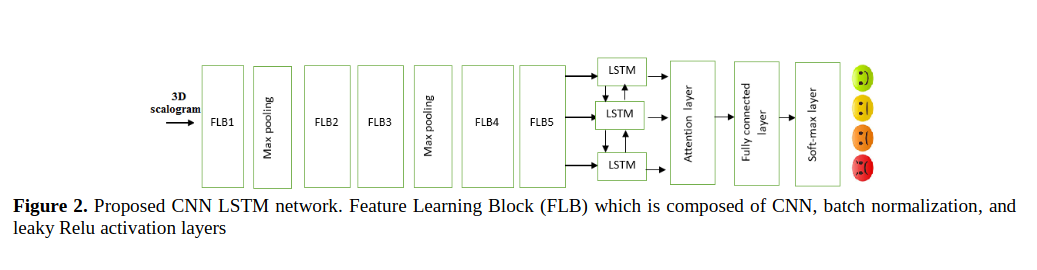
Model Architecture Fig 2
Attention Layer Info Fig 1
{kind=link}
{kind=link}
{kind=link}
Here is the code snippet of the Attention Layer I tried to implement:
class Attention_Layer(nn.Module):
def __init__(self, n_feats: int) -> None:
super().__init__()
self.w = nn.Linear(
in_features=n_feats,
out_features=n_feats
)
def forward(self, X: torch.Tensor) -> torch.Tensor:
w = self.w(X)
output = F.softmax(torch.mul(X, w), dim=1)
return output
And the code snippet of the full model architecture:
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.in_channels = 5
self.linear_input_features = 1103872
self.cnn = nn.Sequential(
FLB(
input_channels=self.in_channels,
output_channels=64,
kernel_size=(2, 2)
),
nn.MaxPool2d(kernel_size=(2, 2)),
FLB(
input_channels=64,
output_channels=128,
kernel_size=(2, 2)
),
FLB(
input_channels=128,
output_channels=256,
kernel_size=(2, 2)
),
nn.MaxPool2d(kernel_size=(2, 2)),
FLB(
input_channels=256,
output_channels=512,
kernel_size=(2, 2)
),
FLB(
input_channels=512,
output_channels=512,
kernel_size=(2, 2)
),
nn.Flatten(),
nn.Linear(
in_features=self.linear_input_features,
out_features=128
)
)
self.lstm = nn.Sequential(
nn.LSTM(
input_size=128,
hidden_size=128,
num_layers=1,
batch_first=True,
bidirectional=True
),
Extract_LSTM_Output()
)
self.model = nn.Sequential(
self.cnn,
self.lstm,
Attention_Layer(256),
nn.Linear(
in_features=256,
out_features=3
)
)
self.model.apply(weight_init)
def forward(self, X: torch.Tensor) -> torch.Tensor:
return self.model(X)