Density between 0 and 1
If the integers with which you express the fractions are in the range 0~M, then the density of fractions between the values 0 (inclusive) and 1 (exclusive) is:
M: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0~(1): 1 2 4 6 10 12 18 22 28 32 42 46 58 64 72 80 96 102 120 128 140 150 172 180 200 212 230 242 270 278 308 ...
This is sequence A002088 on OEIS. If you scroll down to the formula section, you'll find information about how to approximate it, e.g.:
Φ(n) = (3 ÷ π2) × n2 + O[n × (ln n)2/3 × (ln ln n)4/3]
(Unfortunately, no more detail is given about the constants involved in the O[x] part. See discussion about the quality of the approximation below.)
Distribution across range
The interval from 0 to 1 contains half of the total number of unique fractions that can be expressed with numbers up to M; e.g. this is the distribution when M = 15 (i.e. 4-bit integers):
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
72 36 12 6 4 2 2 2 1 1 1 1 1 1 1 1
for a total of 144 unique fractions. If you look at the sequence for different values of M, you'll see that the steps in this sequence converge:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1: 1 1
2: 2 1 1
3: 4 2 1 1
4: 6 3 1 1 1
5: 10 5 2 1 1 1
6: 12 6 2 1 1 1 1
7: 18 9 3 2 1 1 1 1
8: 22 11 4 2 1 1 1 1 1
9: 28 14 5 2 2 1 1 1 1 1
10: 32 16 5 3 2 1 1 1 1 1 1
11: 42 21 7 4 2 2 1 1 1 1 1 1
12: 46 23 8 4 2 2 1 1 1 1 1 1 1
13: 58 29 10 5 3 2 2 1 1 1 1 1 1 1
14: 64 32 11 5 4 2 2 1 1 1 1 1 1 1 1
15: 72 36 12 6 4 2 2 2 1 1 1 1 1 1 1 1
Not only is the density between 0 and 1 half of the total number of fractions, but the density between 1 and 2 is a quarter, and the density between 2 and 3 is close to a twelfth, and so on.
As the value of M increases, the distribution of fractions across the ranges 0-1, 1-2, 2-3 ... converges to:
1/2, 1/4, 1/12, 1/24, 1/40, 1/60, 1/84, 1/112, 1/144, 1/180, 1/220, 1/264 ...
This sequence can be calculated by starting with 1/2 and then:
0-1: 1/2 x 1/1 = 1/2
1-2: 1/2 x 1/2 = 1/4
2-3: 1/4 x 1/3 = 1/12
3-4: 1/12 x 2/4 = 1/24
4-5: 1/24 x 3/5 = 1/40
5-6: 1/40 x 4/6 = 1/60
6-7: 1/60 x 5/7 = 1/84
7-8: 1/84 x 6/8 = 1/112
8-9: 1/112 x 7/9 = 1/144 ...
You can of course calculate any of these values directly, without needing the steps inbetween:
0-1: 1/2
6-7: 1/2 x 1/6 x 1/7 = 1/84
(Also note that the second half of the distribution sequence consists of 1's; these are all the integers divided by 1.)
Approximating the density in given interval
Using the formulas provided on the OEIS page, you can calculate or approximate the density in the interval 0-1, and multiplied by 2 this is the total number of unique values that can be expressed as fractions.
Given two values s and t, you can then calculate and sum the densities in the intervals s ~ s+1, s+1 ~ s+2, ... t-1 ~ t, or use an interpolation to get a faster but less precise approximate value.
Example
Let's assume that we're using 10-bit integers, capable of expressing values from 0 to 1023. Using this table linked from the OEIS page, we find that the density between 0~1 is 318452, and the total number of fractions is 636904.
If we wanted to find the density in the interval s~t = 100~105:
100~101: 1/2 x 1/100 x 1/101 = 1/20200 ; 636904/20200 = 31.53
101~102: 1/2 x 1/101 x 1/102 = 1/20604 ; 636904/20604 = 30.91
102~103: 1/2 x 1/102 x 1/103 = 1/21012 ; 636904/21012 = 30.31
103~104: 1/2 x 1/103 x 1/104 = 1/21424 ; 636904/21424 = 29.73
104~105: 1/2 x 1/104 x 1/105 = 1/21840 ; 636904/21840 = 29.16
Rounding these values gives the sum:
32 + 31 + 30 + 30 + 29 = 152
A brute force algorithm gives this result:
32 + 32 + 30 + 28 + 28 = 150
So we're off by 1.33% for this low value of M and small interval with just 5 values. If we had used linear interpolation between the first and last value:
100~101: 31.53
104~105: 29.16
average: 30.345
total: 151.725 -> 152
we'd have arrived at the same value. For larger intervals, the sum of all the densities will probably be closer to the real value, because rounding errors will cancel each other out, but the results of linear interpolation will probably become less accurate. For ever larger values of M, the calculated densities should converge with the actual values.
Quality of approximation of Φ(n)
Using this simplified formula:
Φ(n) = (3 ÷ π2) × n2
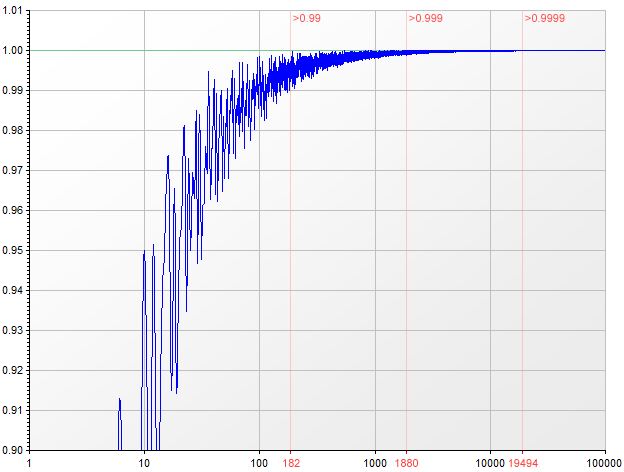
the results are almost always smaller than the actual values, but they are within 1% for n ≥ 182, within 0.1% for n ≥ 1880 and within 0.01% for n ≥ 19494. I would suggest hard-coding the lower range (the first 50,000 values can be found here), and then using the simplified formula from the point where the approximation is good enough.
![approximation of Phi(n)]()
Here's a simple code example with the first 182 values of Φ(n) hard-coded. The approximation of the distribution sequence seems to add an error of a similar magnitude as the approximation of Φ(n), so it should be possible to get a decent approximation. The code simply iterates over every integer in the interval s~t and sums the fractions. To speed up the code and still get a good result, you should probably calculate the fractions at several points in the interval, and then use some sort of non-linear interpolation.
function fractions01(M) {
var phi = [0,1,2,4,6,10,12,18,22,28,32,42,46,58,64,72,80,96,102,120,128,140,150,172,180,200,212,230,242,270,278,308,
324,344,360,384,396,432,450,474,490,530,542,584,604,628,650,696,712,754,774,806,830,882,900,940,964,1000,
1028,1086,1102,1162,1192,1228,1260,1308,1328,1394,1426,1470,1494,1564,1588,1660,1696,1736,1772,1832,1856,
1934,1966,2020,2060,2142,2166,2230,2272,2328,2368,2456,2480,2552,2596,2656,2702,2774,2806,2902,2944,3004,
3044,3144,3176,3278,3326,3374,3426,3532,3568,3676,3716,3788,3836,3948,3984,4072,4128,4200,4258,4354,4386,
4496,4556,4636,4696,4796,4832,4958,5022,5106,5154,5284,5324,5432,5498,5570,5634,5770,5814,5952,6000,6092,
6162,6282,6330,6442,6514,6598,6670,6818,6858,7008,7080,7176,7236,7356,7404,7560,7638,7742,7806,7938,7992,
8154,8234,8314,8396,8562,8610,8766,8830,8938,9022,9194,9250,9370,9450,9566,9654,9832,9880,10060];
if (M < 182) return phi[M];
return Math.round(M * M * 0.30396355092701331433 + M / 4); // experimental; see below
}
function fractions(M, s, t) {
var half = fractions01(M);
var frac = (s == 0) ? half : 0;
for (var i = (s == 0) ? 1 : s; i < t && i <= M; i++) {
if (2 * i < M) {
var f = Math.round(half / (i * (i + 1)));
frac += (f < 2) ? 2 : f;
}
else ++frac;
}
return frac;
}
var M = 1023, s = 100, t = 105;
document.write(fractions(M, s, t));
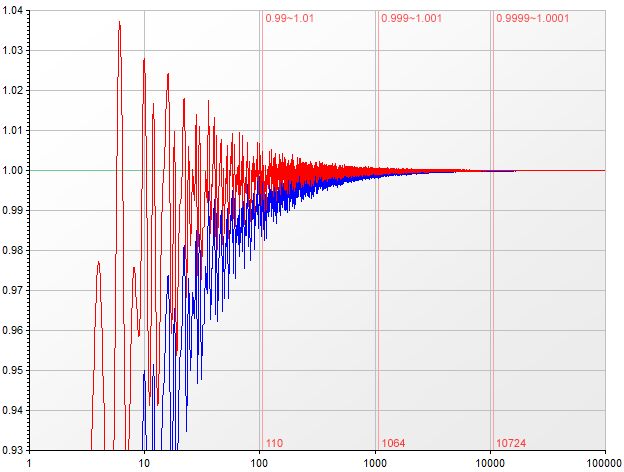
Comparing the approximation of Φ(n) with the list of the 50,000 first values suggests that adding M÷4 is a workable substitute for the second part of the formula; I have not tested this for larger values of n, so use with caution.
![Improved approximation of Phi(n)]()
Blue: simplified formula. Red: improved simplified formula.
Quality of approximation of distribution
Comparing the results for M=1023 with those of a brute-force algorithm, the errors are small in real terms, never more than -7 or +6, and above the interval 205~206 they are limited to -1 ~ +1. However, a large part of the range (57~1024) has fewer than 100 fractions per integer, and in the interval 171~1024 there are only 10 fractions or fewer per integer. This means that small errors and rounding errors of -1 or +1 can have a large impact on the result, e.g.:
interval: 241 ~ 250
fractions/integer: 6
approximation: 5
total: 50 (instead of 60)
To improve the results for intervals with few fractions per integer, I would suggest combining the method described above with a seperate approach for the last part of the range:
Alternative method for last part of range
As already mentioned, and implemented in the code example, the second half of the range, M÷2 ~ M, has 1 fraction per integer. Also, the interval M÷3 ~ M÷2 has 2; the interval M÷4 ~ M÷3 has 4. This is of course the Φ(n) sequence again:
M/2 ~ M : 1
M/3 ~ M/2: 2
M/4 ~ M/3: 4
M/5 ~ M/4: 6
M/6 ~ M/5: 10
M/7 ~ M/6: 12
M/8 ~ M/7: 18
M/9 ~ M/8: 22
M/10 ~ M/9: 28
M/11 ~ M/10: 32
M/12 ~ M/11: 42
M/13 ~ M/12: 46
M/14 ~ M/13: 58
M/15 ~ M/14: 64
M/16 ~ M/15: 72
M/17 ~ M/16: 80
M/18 ~ M/17: 96
M/19 ~ M/18: 102 ...
Between these intervals, one integer can have a different number of fractions, depending on the exact value of M, e.g.:
interval fractions
202 ~ 203 10
203 ~ 204 10
204 ~ 205 9
205 ~ 206 6
206 ~ 207 6
The interval 204 ~ 205 lies on the edge between intervals, because M ÷ 5 = 204.6; it has 6 + 3 = 9 fractions because M modulo 5 is 3. If M had been 1022 or 1024 instead of 1023, it would have 8 or 10 fractions. (This example is straightforward because 5 is a prime; see below.)
Again, I would suggest using the hard-coded values for Φ(n) to calculate the number of fractions for the last part of the range. If you use the first 17 values as listed above, this covers the part of the range with fewer than 100 fractions per integer, so that would reduce the impact of rounding errors below 1%. The first 56 values would give you 0.1%, the first 182 values 0.01%.
Together with the values of Φ(n), you could hard-code the number of fractions of the edge intervals for each modulo value, e.g.:
modulo: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
M/ 2 1 2
M/ 3 2 3 4
M/ 4 4 5 5 6
M/ 5 6 7 8 9 10
M/ 6 10 11 11 11 11 12
M/ 7 12 13 14 15 16 17 18
M/ 8 18 19 19 20 20 21 21 22
M/ 9 22 23 24 24 25 26 26 27 28
M/10 28 29 29 30 30 30 30 31 31 32
M/11 32 33 34 35 36 37 38 39 40 41 42
M/12 42 43 43 43 43 44 44 45 45 45 45 46
M/13 46 47 48 49 50 51 52 53 54 55 56 57 58
M/14 58 59 59 60 60 61 61 61 61 62 62 63 63 64
M/15 64 65 66 66 67 67 67 68 69 69 69 70 70 71 72
M/16 72 73 73 74 74 75 75 76 76 77 77 78 78 79 79 80
M/17 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96
M/18 96 97 97 97 97 98 98 99 99 99 99 100 100 101 101 101 101 102
a >= s*banda <= t*blines. – Yanyanatonfloatordoubleinto your solution. There are probably numbers which can be precisely encoded as fraction but neither asfloatnor asdouble. Example: 1 / 10 => fraction(1, 10) but 0.1 yields a binary with infinite number of digits. (I remember this as our math prof. used this example for illustration and I've seen it later again and again.) – Kaleena(0,1)- yes, ignore the end points, just remember to add them back in at the end. Now, on a piece of paper draw the number line from0..1, give yourself plenty of space. On the next line down write in the location of1/2, on the next line down, the locations of1/3and2/3. On the next line down the locations of1/4,2/4,3/4. Continue as long as you wish. A pattern emerges, leading to a counting problem. But this is, as advised, a mathematical question first and foremost. – TurleyLong,M = MAX_LONG) so I need to find that value only once. – Plumage