I have a 2D-distribution of points (roughly speaking, two np.arrays, x and y) as shown in the figure attached.
How can I select the points of the distribution that are part of the n-th quantile of such distribution?
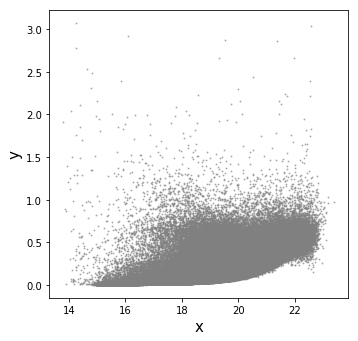
I have a 2D-distribution of points (roughly speaking, two np.arrays, x and y) as shown in the figure attached.
How can I select the points of the distribution that are part of the n-th quantile of such distribution?
I finally came out with a solution, which doesn't look like the most elegant possible, but it worked reasonably well:
To estimate quantiles of a 2 dimensional distribution one can use the scipy function binned_statistics which allows to bin the data in
one of the and calculate some statistics in the other.
Here is the documentation of such function:
https://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.stats.binned_statistic.html
Which syntax is:
scipy.stats.binned_statistic(x, values, statistic='mean', bins=10, range=None)
First, one might chose the number of bins to use, for example Nbins=100.
Next, one might define an user function to be put as input
(here is an example on how to do so:
How to make user defined functions for binned_statistic), which is my case is an function that estimates the n-th percentile of the data in that bin (I called it myperc). Finally a function is defined such as it takes x, y, Nbins and nth (the percentile desired) and returns the binned_statistics gives 3 outputs: statistic (value of the desired statistics in that bin),bin_edges,binnumber (in which bin your data-point is), but also the values of x in center of the bin (bin_center)
def quantile2d(x,y,Nbins,nth):
from numpy import percentile
from scipy.stats import binned_statistic
def myperc(x,n=nth):
return(percentile(x,n))
t=binned_statistic(x,y,statistic=myperc,bins=Nbins)
v=[]
for i in range(len(t[0])): v.append((t[1][i+1]+t[1][i])/2.)
v=np.array(v)
return(t,v)
So v and t.statistic will give x and y values for a curve defining the desired percentile respectively.
Nbins=100
nth=30.
t,v=me.quantile2d(x,y,Nbins,nth)
ii=[]
for i in range(Nbins):
ii=ii+np.argwhere(((t.binnumber==i) & (y<t.statistic[i]))).flatten().tolist()
ii=np.array(ii,dtype=int)
Finally, this gives the following plot:
plt.plot(x,y,'o',color='gray',ms=1,zorder=1)
plt.plot(v,t.statistic,'r-',zorder=3)
plt.plot(x[ii],y[ii],'o',color='blue',ms=1,zorder=2)
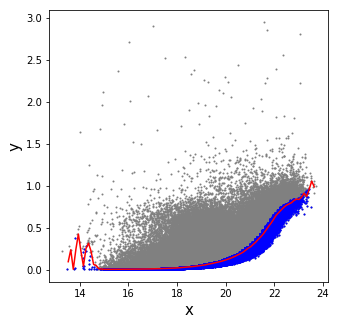
in which the line for the 30-th percentile is shown in red, and the data under this percentile is shown in blue.
© 2022 - 2024 — McMap. All rights reserved.