I have been trying to implement a simple linear regression model using neural networks in Keras in hopes to understand how do we work in Keras library. Unfortunately, I am ending up with a very bad model. Here is the implementation:
from pylab import *
from keras.models import Sequential
from keras.layers import Dense
#Generate dummy data
data = data = linspace(1,2,100).reshape(-1,1)
y = data*5
#Define the model
def baseline_model():
model = Sequential()
model.add(Dense(1, activation = 'linear', input_dim = 1))
model.compile(optimizer = 'rmsprop', loss = 'mean_squared_error', metrics = ['accuracy'])
return model
#Use the model
regr = baseline_model()
regr.fit(data,y,epochs =200,batch_size = 32)
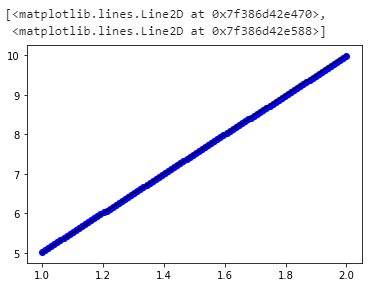
plot(data, regr.predict(data), 'b', data,y, 'k.')
The generated plot is as follows:
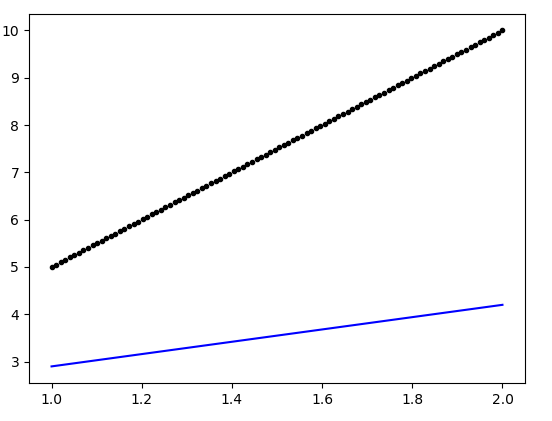
Can somebody point out the flaw in the above definition of the model (which could ensure a better fit)?
{kind=link}
{kind=link}
{kind=link}
{kind=link}