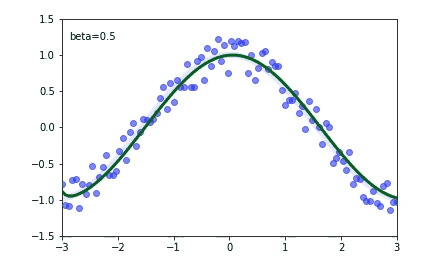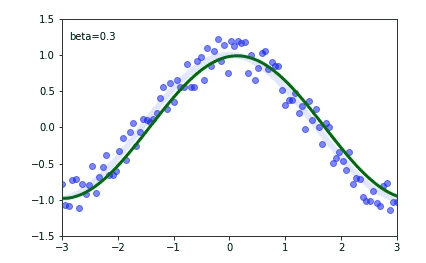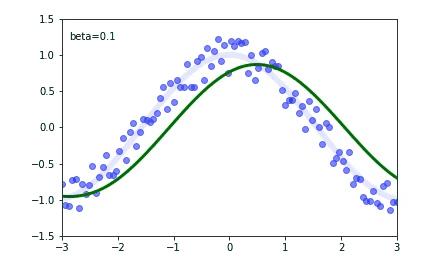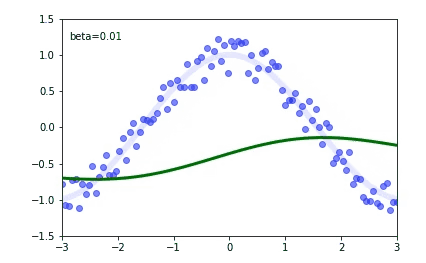
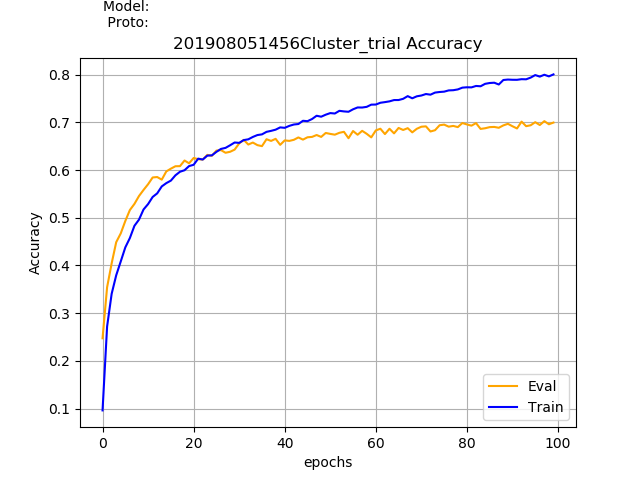
I'm using PyTorch to implement a classification network for skeleton-based action recognition. The model consists of three convolutional layers and two fully connected layers. This base model gave me an accuracy of around 70% in the NTU-RGB+D dataset. I wanted to learn more about batch normalization, so I added a batch normalization for all the layers except for the last one. To my surprise, the evaluation accuracy dropped to 60% rather than increasing But the training accuracy has increased from 80% to 90%. Can anyone say what am I doing wrong? or Adding batch normalization need not increase the accuracy?
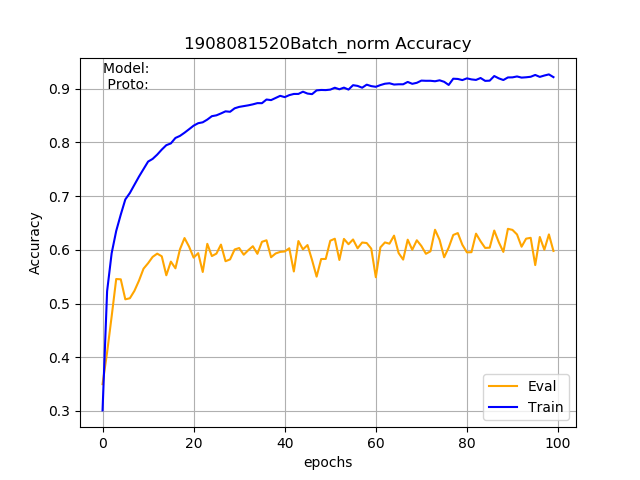
The model with batch normalization
class BaseModelV0p2(nn.Module):
def __init__(self, num_person, num_joint, num_class, num_coords):
super().__init__()
self.name = 'BaseModelV0p2'
self.num_person = num_person
self.num_joint = num_joint
self.num_class = num_class
self.channels = num_coords
self.out_channel = [32, 64, 128]
self.loss = loss
self.metric = metric
self.bn_momentum = 0.01
self.bn_cv1 = nn.BatchNorm2d(self.out_channel[0], momentum=self.bn_momentum)
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=self.channels, out_channels=self.out_channel[0],
kernel_size=3, stride=1, padding=1),
self.bn_cv1,
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.bn_cv2 = nn.BatchNorm2d(self.out_channel[1], momentum=self.bn_momentum)
self.conv2 = nn.Sequential(nn.Conv2d(in_channels=self.out_channel[0], out_channels=self.out_channel[1],
kernel_size=3, stride=1, padding=1),
self.bn_cv2,
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.bn_cv3 = nn.BatchNorm2d(self.out_channel[2], momentum=self.bn_momentum)
self.conv3 = nn.Sequential(nn.Conv2d(in_channels=self.out_channel[1], out_channels=self.out_channel[2],
kernel_size=3, stride=1, padding=1),
self.bn_cv3,
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.bn_fc1 = nn.BatchNorm1d(256 * 2, momentum=self.bn_momentum)
self.fc1 = nn.Sequential(nn.Linear(self.out_channel[2]*8*3, 256*2),
self.bn_fc1,
nn.ReLU(),
nn.Dropout2d(p=0.5)) # TO check
self.fc2 = nn.Sequential(nn.Linear(256*2, self.num_class))
def forward(self, input):
list_bn_layers = [self.bn_fc1, self.bn_cv3, self.bn_cv2, self.bn_cv1]
# set the momentum of the batch norm layers to given momentum value during trianing and 0 during evaluation
# ref: https://discuss.pytorch.org/t/model-eval-gives-incorrect-loss-for-model-with-batchnorm-layers/7561
# ref: https://github.com/pytorch/pytorch/issues/4741
for bn_layer in list_bn_layers:
if self.training:
bn_layer.momentum = self.bn_momentum
else:
bn_layer.momentum = 0
logits = []
for i in range(self.num_person):
out = self.conv1(input[:, :, :, :, i])
out = self.conv2(out)
out = self.conv3(out)
logits.append(out)
out = torch.max(logits[0], logits[1])
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
t = out
assert not ((t != t).any()) # find out nan in tensor
assert not (t.abs().sum() == 0) # find out 0 tensor
return out