I use Pdfplumber to extract the table on page 2, section 3 (normally). But it only works on some pdf, others do not work. For failed pdf files, it seems like Pdfplumber read the button table instead of the table I want.
How can I get the table? link of the pdf which doesn't work: pdfA
link of the pdf which works: pdfB
Here is my code:
import pdfplumber
pdf = pdfplumber.open("/Users/chueckingmok/Desktop/selenium/Shell Omala 68.pdf")
page = pdf.pages[1]
table=page.extract_table()
import pandas as pd
df = pd.DataFrame(table[1:], columns=table[0])
df
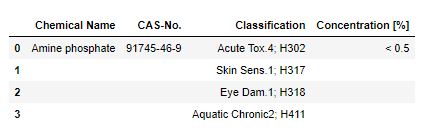
and the result is

But the table I want in page 2 is
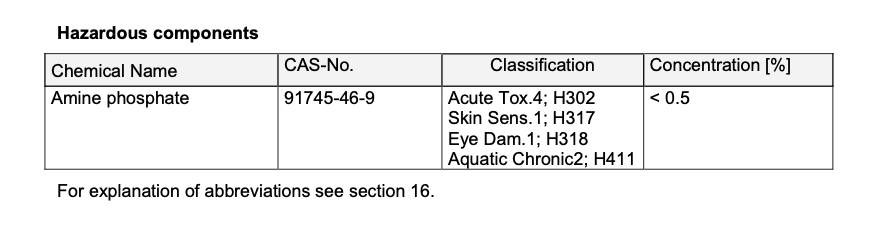
However, this code works for pdfB (which I mentioned above).
Btw, the table I want in each pdf is in section 3.
Anyone can help?
Many thanks Joan
Updated: I just found a good package to extract pdf file without any problems. the package is fitz, and it also names as PyMuPDF.
{kind=link}