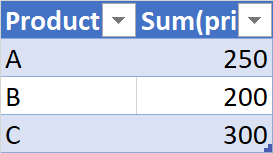
I have a case where I may have null values in the column that needs to be summed up in a group.
If I encounter a null in a group, I want the sum of that group to be null. But PySpark by default seems to ignore the null rows and sum-up the rest of the non-null values.
For example:
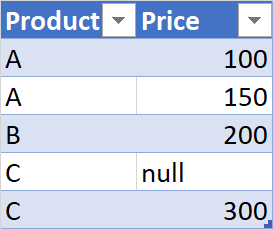
dataframe = dataframe.groupBy('dataframe.product', 'dataframe.price') \
.agg(f.sum('price'))
Expected output is:
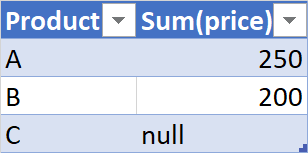
But I am getting: