I've already read Can Pandas read and modify a single Excel file worksheet (tab) without modifying the rest of the file? but here my question is specific to the layout mentioned hereafter.
How to open an Excel file with Pandas, do some modifications, and save it back:
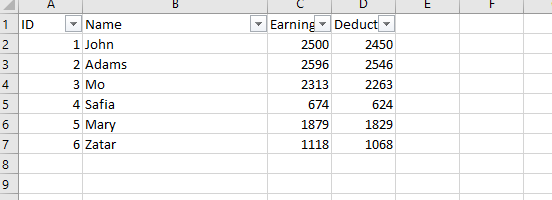
(1) without removing that there is a
Filteron the first row![enter image description here]()
(2) without modifying the "displayed column width" of the columns as displayed in Excel
(3) without removing the formulas which might be present on some cells

?
Here is what I tried, it's a short example (in reality I do more processing with Pandas):
import pandas as pd
df = pd.read_excel('in.xlsx')
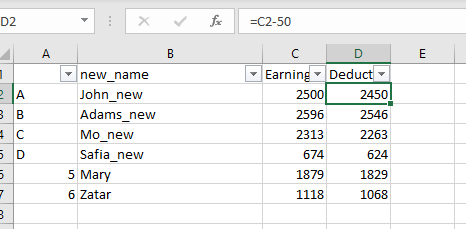
df['AB'] = df['A'].astype(str) + ' ' + df['B'].astype(str) # create a new column from 2 others
del df['Date'] # delete columns
del df['Time']
df.to_excel('out.xlsx', index=False)
With this code, the Filter of the first row is removed and the displayed column width are set to a default, which is not very handy (because we would have to manually set the correct width for all columns).