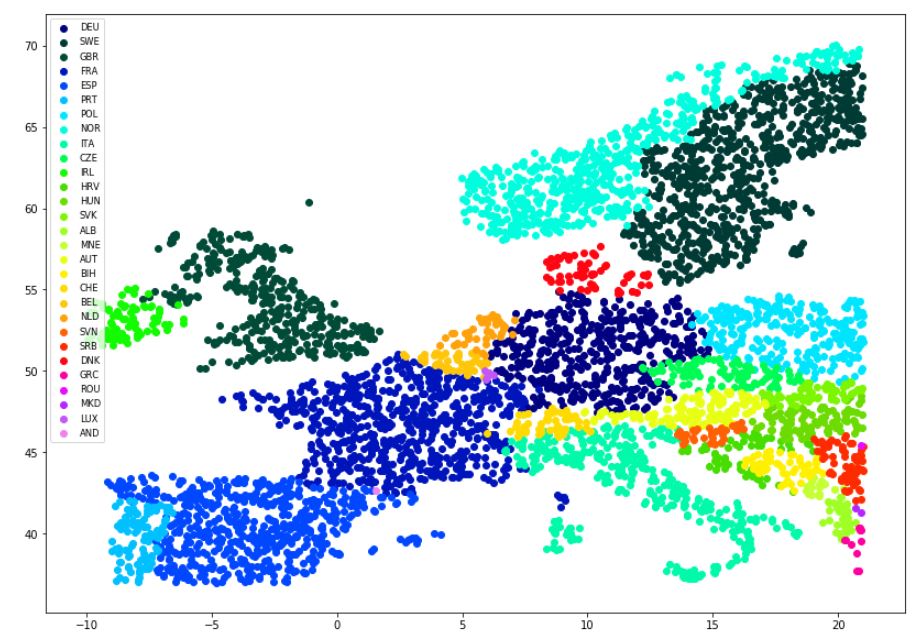
Had to do a similar thing, but wanted to be really uniformly spread in Europe in this case.
import shapefile
from shapely.geometry import Point, shape
import numpy as np
from collections import Counter
shp = shapefile.Reader('shapefiles/TM_WORLD_BORDERS-0.3.shp')
# Adjust for your case:
EU3 = ['ARM', 'BIH', 'BIH', 'CYP', 'DNK', 'IRL', 'AUT', 'EST', 'CZE', 'FIN'
, 'FRA', 'DEU', 'GRC', 'HRV', 'HUN', 'ISL', 'ITA', 'LTU', 'LVA', 'BLR'
, 'MLT', 'BEL', 'AND', 'GIB', 'LUX', 'MCO', 'NLD', 'NOR', 'POL', 'PRT'
, 'ROU', 'MDA', 'ESP', 'CHE', 'GBR', 'SRB', 'SWE', 'ALB', 'MKD', 'MNE'
, 'SVK', 'SVN'] # 'TUR'
EU = [(boundary, record) for boundary, record in
zip(shp.shapes(), shp.records()) if record[2] in EU3]
# Adjust the borders
count = Counter() # small optimisation to check for big shapes first
def sample(shapes, min_x=-11, max_x=26, min_y=37, max_y=71):
while True:
point = (np.random.uniform(min_x, max_X), np.random.uniform(min_y, max_y))
for boundary, record in sorted(shapes, key=lambda x: -count[x[1][2]]):
if Point(point).within(shape(boundary)):
count[record[2]] += 1
return point
This gives you the samples you want. Below a plot of a 5000 point sample from Europe. To obtain one sample use
sample(EU)
![Showcase]()