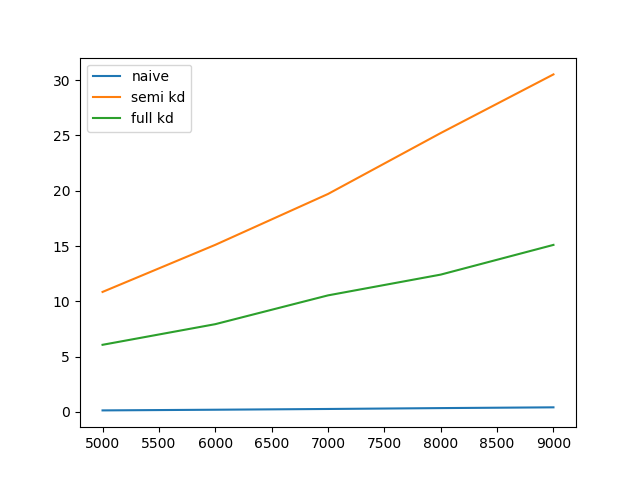
I've quickly checked the performance of building a tree and querying it versus just calculating all the euclidean distances. If I query this tree for all other points within a radius, shouldn't it vastly outperform the brute force approach?
Does anyone know why my test code yields these different results? Am I using it wrong? Is the test case unfit for kd-trees?
PS: This is a reduced proof-of-concept version of the code I used. The full code where I also store and transform the results can be found here, but it yields the same results.
Imports
import numpy as np
from time import time
from scipy.spatial import KDTree as kd
from functools import reduce
import matplotlib.pyplot as plt
Implementations
def euclid(c, cs, r):
return ((cs[:,0] - c[0]) ** 2 + (cs[:,1] - c[1]) ** 2 + (cs[:,2] - c[2]) ** 2) < r ** 2
def find_nn_naive(cells, radius):
for i in range(len(cells)):
cell = cells[i]
cands = euclid(cell, cells, radius)
def find_nn_kd_seminaive(cells, radius):
tree = kd(cells)
for i in range(len(cells)):
res = tree.query_ball_point(cells[i], radius)
def find_nn_kd_by_tree(cells, radius):
tree = kd(cells)
res = tree.query_ball_tree(tree, radius)
Test setup
min_iter = 5000
max_iter = 10000
step_iter = 1000
rng = range(min_iter, max_iter, step_iter)
elapsed_naive = np.zeros(len(rng))
elapsed_kd_sn = np.zeros(len(rng))
elapsed_kd_tr = np.zeros(len(rng))
ei = 0
for i in rng:
random_cells = np.random.rand(i, 3) * 400.
t = time()
r1 = find_nn_naive(random_cells, 50.)
elapsed_naive[ei] = time() - t
t = time()
r2 = find_nn_kd_seminaive(random_cells, 50.)
elapsed_kd_sn[ei] = time() - t
t = time()
r3 = find_nn_kd_by_tree(random_cells, 50.)
elapsed_kd_tr[ei] = time() - t
ei += 1
Plot
plt.plot(rng, elapsed_naive, label='naive')
plt.plot(rng, elapsed_kd_sn, label='semi kd')
plt.plot(rng, elapsed_kd_tr, label='full kd')
plt.legend()
plt.show(block=True)
scipy.spatial.cKDTreeis substantially faster than the pure python implementation.cKDTreehas exactly the same methods, etc, so you just need to change your import statement. Do your timing results hold in that case, too? Also, could you profile your functions to check whether most of the time is spent building the tree or querying it? The query times can often be improved by specifying a more suitableleafsizeparameter. – Densify