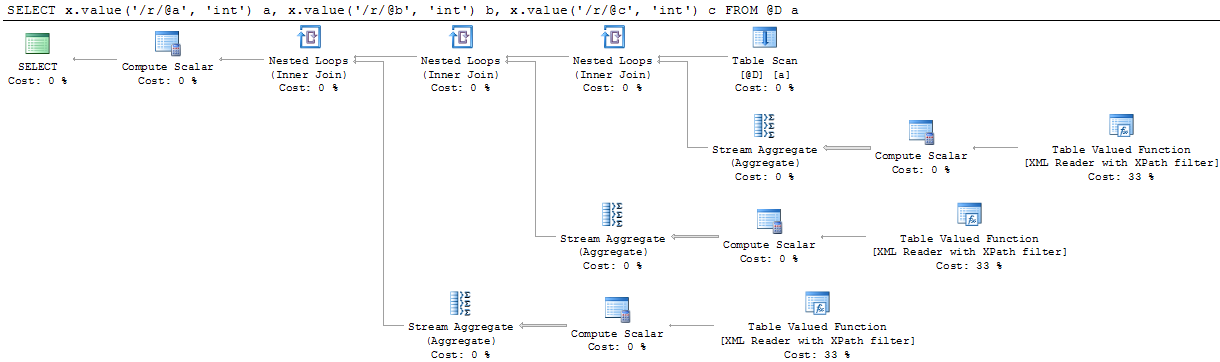
There are some mysteries in the query plan that needs to be sorted out first. What does the compute scalar do a and why is there a stream aggregate.
The table valued function returns a node table of the shredded XML, one row for each shredded row. When you use typed XML those columns are value, lvalue, lvaluebin and tid. Those columns are used in the compute scalar to calculate the actual value. The code in there looks a bit strange and I can't say that I understand why it is as it is but the gist of it is that the function xsd_cast_to_maybe_large returns the value and there is code that handles the case when the value is equal to and greater than 128 bytes.
CASE WHEN datalength(
CONVERT_IMPLICIT(sql_variant,
CONVERT_IMPLICIT(nvarchar(64),
xsd_cast_to_maybe_large(XML Reader with XPath filter.[value],
XML Reader with XPath filter.[lvalue],
XML Reader with XPath filter.[lvaluebin],
XML Reader with XPath filter.[tid],(15),(5),(0)),0),0))>=(128)
THEN CONVERT_IMPLICIT(int,CASE WHEN datalength(xsd_cast_to_maybe_large(XML Reader with XPath filter.[value],
XML Reader with XPath filter.[lvalue],
XML Reader with XPath filter.[lvaluebin],
XML Reader with XPath filter.[tid],(15),(5),(0)))<(128)
THEN NULL
ELSE xsd_cast_to_maybe_large(XML Reader with XPath filter.[value],
XML Reader with XPath filter.[lvalue],
XML Reader with XPath filter.[lvaluebin],
XML Reader with XPath filter.[tid],(15),(5),(0))
END,0)
ELSE CONVERT_IMPLICIT(int,CONVERT_IMPLICIT(sql_variant,
CONVERT_IMPLICIT(nvarchar(64),
xsd_cast_to_maybe_large(XML Reader with XPath filter.[value],
XML Reader with XPath filter.[lvalue],
XML Reader with XPath filter.[lvaluebin],
XML Reader with XPath filter.[tid],(15),(5),(0)),0),0),0)
END
The same compute scalar for non typed XML is much simpler and actually understandable.
CASE WHEN datalength(XML Reader with XPath filter.[value])>=(128)
THEN CONVERT_IMPLICIT(int,XML Reader with XPath filter.[lvalue],0)
ELSE CONVERT_IMPLICIT(int,XML Reader with XPath filter.[value],0)
END
If there are more than 128 bytes in value fetch from lvalue else fetch from value. In the case with non typed XML the returned node table only outputs the columns id, value and lvalue.
When you use typed XML the storage of the node values are optimized based on the datatype specified in the schema. Looks like it could either end up in value, lvalue or lvaluebin in the node table depending on what type of value it is and xsd_cast_to_maybe_large is there to help sort things out.
The stream aggregate does a min() over the returned values from the compute scalar. We know and SQL Server does (at least sometimes) knows that there will only ever be one row returned from the table valued function when you specify an XPath in the value() function. The parser makes sure that we build the XPath correctly but when the query optimizer looks at the estimated rows it sees 200 rows. The base estimate for the table valued function that parses XML is 10000 rows and then there is some adjustments made using the XPath used. In this case it ends up with 200 rows where there is only one. Pure speculation on my part is that the stream aggregate is there to take care of this discrepancy. It will never aggregate anything, only send the one row through that is returned but it does affect the cardinality estimate for the entire branch and makes sure the optimizer uses 1 rows as an estimate for that branch. That is of course really important when the optimizer chooses join strategies etc.
So how about 100 attributes? Yes, there will be 100 branches if you use the value function 100 times. But there are some optimizations to be done here. I created a test rig to see what shape and form of the query would be the fastest using 100 attributes over 10 rows.
The winner was to use untyped XML and not to use the nodes() function to shred on r.
select X.value('(/r/@a1)[1]', 'int') as a1,
X.value('(/r/@a2)[1]', 'int') as a2,
X.value('(/r/@a3)[1]', 'int') as a3
from @T
There is also a way to avoid the 100 branches using pivot but depending on what your actual query looks like it might not be possible. The data type coming out from the pivot must be the same. You could of course extract them as a string and convert to appropriate type in the column list. It also requires that your table has a primary/unique key.
select a1, a2, a3
from (
select T.ID, -- primary key of @T
A.X.value('local-name(.)', 'nvarchar(50)') as Name,
A.X.value('.', 'int') as Value
from @T as T
cross apply T.X.nodes('/r/@*') as A(X)
) as T
pivot(min(T.Value) for Name in (a1, a2, a3)) as P
Query plan for pivot query, 10 rows 100 attributes:
![enter image description here]()
Below is the results and the test rig I used. I tested with 100 attributes and 10 rows and all int attributes.
Result:
Test Duration (ms)
-------------------------------------------------- -------------
untyped XML value('/r[1]/@a') 195
untyped XML value('(/r/@a)[1]') 108
untyped XML value('@a') cross apply nodes('/r') 131
untyped XML value('@a') cross apply nodes('/r[1]') 127
typed XML value('/r/@a') 185
typed XML value('(/r/@a)[1]') 148
typed XML value('@a') cross apply nodes('/r') 176
untyped XML pivot 34
typed XML pivot 52
Code:
drop type dbo.TRABType
drop type dbo.TType;
drop xml schema collection dbo.RAB;
go
declare @NumAtt int = 100;
declare @Attribs nvarchar(max);
with xmlnamespaces('http://www.w3.org/2001/XMLSchema' as xsd)
select @Attribs = (
select top(@NumAtt) 'a'+cast(row_number() over(order by 1/0) as varchar(11)) as '@name',
'sqltypes:int' as '@type',
'required' as '@use'
from sys.columns
for xml path('xsd:attribute')
)
--CREATE XML SCHEMA COLLECTION RAB AS
declare @Schema nvarchar(max) =
'
<xsd:schema xmlns:schema="urn:schemas-microsoft-com:sql:SqlRowSet1" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:sqltypes="http://schemas.microsoft.com/sqlserver/2004/sqltypes" elementFormDefault="qualified">
<xsd:import namespace="http://schemas.microsoft.com/sqlserver/2004/sqltypes" schemaLocation="http://schemas.microsoft.com/sqlserver/2004/sqltypes/sqltypes.xsd" />
<xsd:element name="r" type="r"/>
<xsd:complexType name="r">[ATTRIBS]</xsd:complexType>
</xsd:schema>';
set @Schema = replace(@Schema, '[ATTRIBS]', @Attribs)
create xml schema collection RAB as @Schema
go
create type dbo.TType as table
(
ID int identity primary key,
X xml not null
);
go
create type dbo.TRABType as table
(
ID int identity primary key,
X xml(document rab) not null
);
go
declare @NumAtt int = 100;
declare @NumRows int = 10;
declare @X nvarchar(max);
declare @C nvarchar(max);
declare @M nvarchar(max);
declare @S1 nvarchar(max);
declare @S2 nvarchar(max);
declare @S3 nvarchar(max);
declare @S4 nvarchar(max);
declare @S5 nvarchar(max);
declare @S6 nvarchar(max);
declare @S7 nvarchar(max);
declare @S8 nvarchar(max);
declare @S9 nvarchar(max);
set @X = N'<r '+
(
select top(@NumAtt) 'a'+cast(row_number() over(order by 1/0) as varchar(11))+'="'+cast(row_number() over(order by 1/0) as varchar(11))+'" '
from sys.columns
for xml path('')
)+
'/>';
set @C =
stuff((
select top(@NumAtt) ',a'+cast(row_number() over(order by 1/0) as varchar(11))
from sys.columns
for xml path('')
), 1, 1, '')
set @M =
stuff((
select top(@NumAtt) ',MAX(CASE WHEN name = ''a'+cast(row_number() over(order by 1/0) as varchar(11))+''' THEN val END)'
from sys.columns
for xml path('')
), 1, 1, '')
declare @T dbo.TType;
insert into @T(X)
select top(@NumRows) @X
from sys.columns;
declare @TRAB dbo.TRABType;
insert into @TRAB(X)
select top(@NumRows) @X
from sys.columns;
-- value('/r[1]/@a')
set @S1 = N'
select T.ID'+
(
select top(@NumAtt) ', T.X.value(''/r[1]/@a'+cast(row_number() over(order by 1/0) as varchar(11))+''', ''int'')'
from sys.columns
for xml path('')
)+
' from @T as T
option (maxdop 1)';
-- value('(/r/@a)[1]')
set @S2 = N'
select T.ID'+
(
select top(@NumAtt) ', T.X.value(''(/r/@a'+cast(row_number() over(order by 1/0) as varchar(11))+')[1]'', ''int'')'
from sys.columns
for xml path('')
)+
' from @T as T
option (maxdop 1)';
-- value('@a') cross apply nodes('/r')
set @S3 = N'
select T.ID'+
(
select top(@NumAtt) ', T2.X.value(''@a'+cast(row_number() over(order by 1/0) as varchar(11))+''', ''int'')'
from sys.columns
for xml path('')
)+
' from @T as T
cross apply T.X.nodes(''/r'') as T2(X)
option (maxdop 1)';
-- value('@a') cross apply nodes('/r[1]')
set @S4 = N'
select T.ID'+
(
select top(@NumAtt) ', T2.X.value(''@a'+cast(row_number() over(order by 1/0) as varchar(11))+''', ''int'')'
from sys.columns
for xml path('')
)+
' from @T as T
cross apply T.X.nodes(''/r[1]'') as T2(X)
option (maxdop 1)';
-- value('/r/@a') typed XML
set @S5 = N'
select T.ID'+
(
select top(@NumAtt) ', T.X.value(''/r/@a'+cast(row_number() over(order by 1/0) as varchar(11))+''', ''int'')'
from sys.columns
for xml path('')
)+
' from @TRAB as T
option (maxdop 1)';
-- value('(/r/@a)[1]')
set @S6 = N'
select T.ID'+
(
select top(@NumAtt) ', T.X.value(''(/r/@a'+cast(row_number() over(order by 1/0) as varchar(11))+')[1]'', ''int'')'
from sys.columns
for xml path('')
)+
' from @TRAB as T
option (maxdop 1)';
-- value('@a') cross apply nodes('/r') typed XML
set @S7 = N'
select T.ID'+
(
select top(@NumAtt) ', T2.X.value(''@a'+cast(row_number() over(order by 1/0) as varchar(11))+''', ''int'')'
from sys.columns
for xml path('')
)+
' from @TRAB as T
cross apply T.X.nodes(''/r'') as T2(X)
option (maxdop 1)';
-- pivot
set @S8 = N'
select ID, '+@C+'
from (
select T.ID,
A.X.value(''local-name(.)'', ''nvarchar(50)'') as Name,
A.X.value(''.'', ''int'') as Value
from @T as T
cross apply T.X.nodes(''/r/@*'') as A(X)
) as T
pivot(min(T.Value) for Name in ('+@C+')) as P
option (maxdop 1)';
-- typed pivot
set @S9 = N'
select ID, '+@C+'
from (
select T.ID,
A.X.value(''local-name(.)'', ''nvarchar(50)'') as Name,
cast(cast(A.X.query(''string(.)'') as varchar(11)) as int) as Value
from @TRAB as T
cross apply T.X.nodes(''/r/@*'') as A(X)
) as T
pivot(min(T.Value) for Name in ('+@C+')) as P
option (maxdop 1)';
exec sp_executesql @S1, N'@T dbo.TType readonly', @T;
exec sp_executesql @S2, N'@T dbo.TType readonly', @T;
exec sp_executesql @S3, N'@T dbo.TType readonly', @T;
exec sp_executesql @S4, N'@T dbo.TType readonly', @T;
exec sp_executesql @S5, N'@TRAB dbo.TRABType readonly', @TRAB;
exec sp_executesql @S6, N'@TRAB dbo.TRABType readonly', @TRAB;
exec sp_executesql @S7, N'@TRAB dbo.TRABType readonly', @TRAB;
exec sp_executesql @S8, N'@T dbo.TType readonly', @T;
exec sp_executesql @S9, N'@TRAB dbo.TRABType readonly', @TRAB;

SELECT r.value('@a','int'),r.value('@b','int'),r.value('@c','int') FROM @D CROSS APPLY x.nodes('/r') as ca(r)but the plan looks much the same shape (with the TVF nodes given a much higher estimated subtree cost) – Proselytism