Narcolessico 's answer worked for me, but it took me some time to completely understand the approach. I will add to the answer provided above.
NOTE: I am using Java (Apache HttpClient) to perform the HTTP GET requests to the Confluence server.
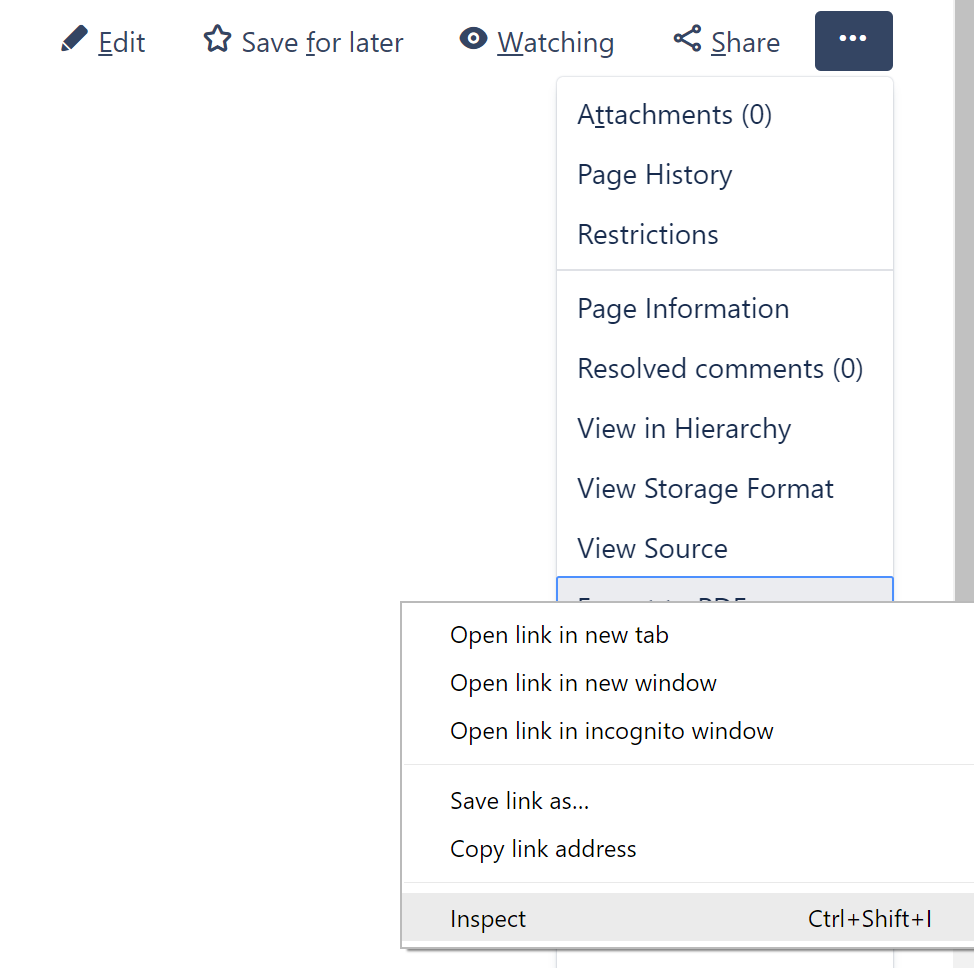
- I used Chrome to navigate to the Confluence page I wanted to export to PDF. I expanded the tools menu, right-clicked on 'Export to PDF', and then clicked on 'Inspect'. This will reveal the underlying HTML element for this menu option containing the link used to launch the PDF export operation.
inspect element to find url
- The element inspection revealed the relative link to the PDF export action as follows.
html source
- From Java, if you perform a HTTP GET to https://your-confluence-server-hostname/the-relative-link-from-step-2, you will need to disable redirect handling. This is where Narcolessico's answer confused me as I was getting different responses from cURL vs. Java. When I realized that the cURL operation was returning a 302 response and that the Apache Http client was auto handling it, I found a means to disable that auto redirect handling so that I can capture the Location header information.
The code to disable the auto redirect handling is as follows.
final HttpClient client = HttpClientBuilder
.create()
.setSSLContext(sslContext)
.disableRedirectHandling() // disable the auto handling here
.build();
final String urlToGetLocation = "https://<your-confluence-server-hostname><the-relative-link-from-step-2>"
final HttpGet request = new HttpGet(urlToGetLocation);
// You'll need to provide Basic Auth credentials. This is a base-64 encoded
// username:password string, else the Location header returned will be a
// redirect to the login page.
request.setHeader(HttpHeaders.AUTHORIZATION, authorizationHeaderValue);
request.setHeader(HttpHeaders.CONTENT_TYPE, "application/json");
final HttpResponse response = client.execute(request);
final HttpEntity payload = response.getEntity();
NOTE: I am also overriding the SSL context to do nothing. That is another issue you may need to contend with if Confluence is using HTTPs.
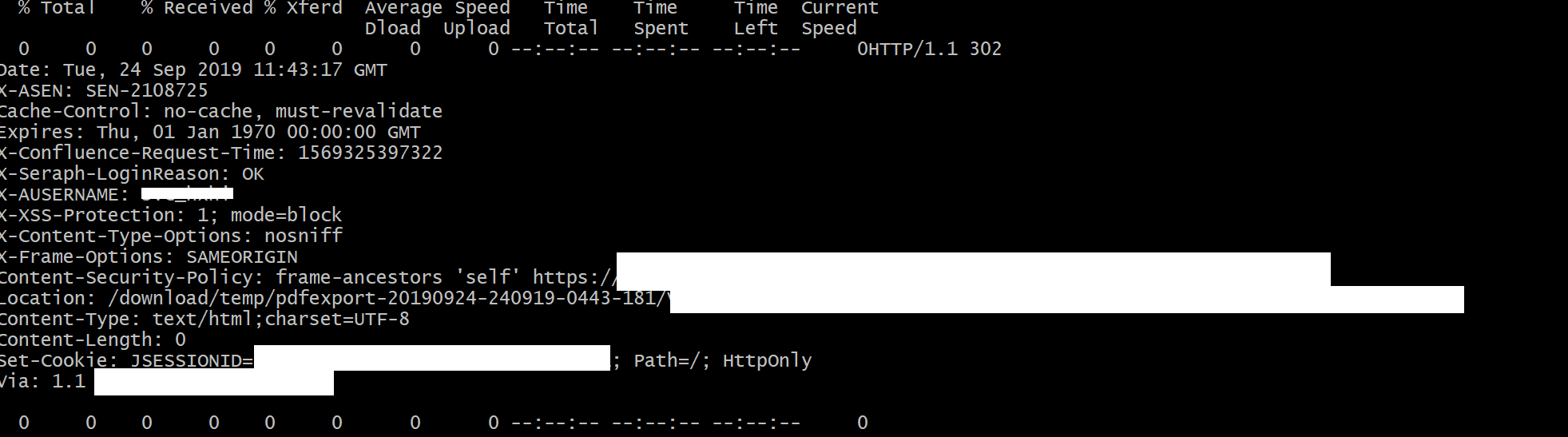
On a side note, if you were to perform a CURL GET for the above stated url, you get a response as follows.
redacted cURL output
The above GET request and resulting 302 response, will reveal the location of the PDF document that you can then download. The 302 response headers will contain the following.
final Header[] headers = response.getHeaders(HttpHeaders.LOCATION);
final String location = headers[0].getValue();
This is a url in the form of the following.
/download/temp/pdfexport-20190924-240919-0526-189/a-filename-for-pdf.pdf?contentType=application/pdf
- The Location header above contain the url to the exported/generated PDF. You can then make a subsequent HTTP GET to that url to download the generated PDF document.
if you're using the Apache Http client, you'll need to use auto redirect handling for this subsequent GET request.
All credit to Narcolessico for this answer. I simply wanted to add the details I had to sort out to get it to work from Java.
{kind=link}
{kind=link}
{kind=link}