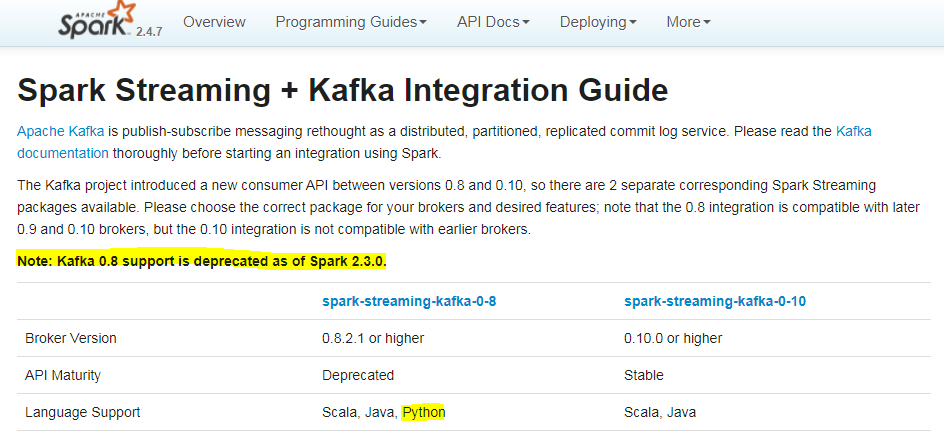
Kafka with spark-streaming throws an error:
from pyspark.streaming.kafka import KafkaUtils ImportError: No module named kafka
I have already setup a kafka broker and a working spark environment with one master and one worker.
import os
os.environ['PYSPARK_PYTHON'] = '/usr/bin/python2.7'
import findspark
findspark.init('/usr/spark/spark-3.0.0-preview2-bin-hadoop2.7')
import pyspark
import sys
from pyspark import SparkConf,SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
if __name__=="__main__":
sc = SparkContext(appName="SparkStreamAISfromKAFKA")
sc.setLogLevel("WARN")
ssc = StreamingContext(sc,1)
kvs = KafkaUtils.createStream(ssc,"my-kafka-broker","raw-event-streaming-consumer",{'enriched_ais_messages':1})
lines = kvs.map(lambda x: x[1])
lines.count().map(lambda x: 'Messages AIS: %s' % x).pprint()
ssc.start()
ssc.awaitTermination()
I assume for the error that something is missing related to kafka ans specifically with the versions. Can anyone help with this?
spark-version: version 3.0.0-preview2
I execute with:
/usr/spark/spark-3.0.0-preview2-bin-hadoop2.7/bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.1 --jars spark-streaming-kafka-0-10_2.11 spark_streamer.py spark://mysparkip:7077