What is TripletHardLoss?
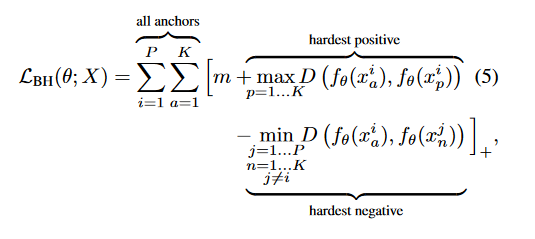
This loss follow the ordinary TripletLoss form, but using the maximum positive distance and minimum negative distance plus the margin constant within the batch when computing the loss, as we can see in the formula:
![enter image description here]()
Look into source code of tfa.losses.TripletHardLoss we can see above formula been implement exactly:
# Build pairwise binary adjacency matrix.
adjacency = tf.math.equal(labels, tf.transpose(labels))
# Invert so we can select negatives only.
adjacency_not = tf.math.logical_not(adjacency)
adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
# hard negatives: smallest D_an.
hard_negatives = _masked_minimum(pdist_matrix, adjacency_not)
batch_size = tf.size(labels)
adjacency = tf.cast(adjacency, dtype=tf.dtypes.float32)
mask_positives = tf.cast(adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
tf.ones([batch_size])
)
# hard positives: largest D_ap.
hard_positives = _masked_maximum(pdist_matrix, mask_positives)
if soft:
triplet_loss = tf.math.log1p(tf.math.exp(hard_positives - hard_negatives))
else:
triplet_loss = tf.maximum(hard_positives - hard_negatives + margin, 0.0)
# Get final mean triplet loss
triplet_loss = tf.reduce_mean(triplet_loss)
Note the soft parameter in tfa.losses.TripletHardLoss are not using following formula to calculate the ordinary TripletLoss:
![enter image description here]()
Because as we can see in above source code, it still using maximum positive distance and minimum negative distance, it determine using the soft margin or not
What is TripletSemiHardLoss?
This loss also follow the ordinary TripletLoss form, positive distances is same as in ordinary TripletLoss and negative distance using semi-hard negative:
Minimum negative distance among which are at least greater than the
positive distance plus the margin constant, if no such negative
exists, uses the largest negative distance instead.
i.e we want first find negative distance that satisfies following condition:
![enter image description here]()
p for positive and n for negative, if wan can't find the negative distance that satisfies this condition then we using largest negative distance instead.
As we can see above condition process clear in source code of tfa.losses.TripletSemiHardLoss, where negatives_outside is distance that satisfies this condition and negatives_inside is largest negative distance:
# Build pairwise binary adjacency matrix.
adjacency = tf.math.equal(labels, tf.transpose(labels))
# Invert so we can select negatives only.
adjacency_not = tf.math.logical_not(adjacency)
batch_size = tf.size(labels)
# Compute the mask.
pdist_matrix_tile = tf.tile(pdist_matrix, [batch_size, 1])
mask = tf.math.logical_and(
tf.tile(adjacency_not, [batch_size, 1]),
tf.math.greater(
pdist_matrix_tile, tf.reshape(tf.transpose(pdist_matrix), [-1, 1])
),
)
mask_final = tf.reshape(
tf.math.greater(
tf.math.reduce_sum(
tf.cast(mask, dtype=tf.dtypes.float32), 1, keepdims=True
),
0.0,
),
[batch_size, batch_size],
)
mask_final = tf.transpose(mask_final)
adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
mask = tf.cast(mask, dtype=tf.dtypes.float32)
# negatives_outside: smallest D_an where D_an > D_ap.
negatives_outside = tf.reshape(
_masked_minimum(pdist_matrix_tile, mask), [batch_size, batch_size]
)
negatives_outside = tf.transpose(negatives_outside)
# negatives_inside: largest D_an.
negatives_inside = tf.tile(
_masked_maximum(pdist_matrix, adjacency_not), [1, batch_size]
)
semi_hard_negatives = tf.where(mask_final, negatives_outside, negatives_inside)
loss_mat = tf.math.add(margin, pdist_matrix - semi_hard_negatives)
mask_positives = tf.cast(adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
tf.ones([batch_size])
)
# In lifted-struct, the authors multiply 0.5 for upper triangular
# in semihard, they take all positive pairs except the diagonal.
num_positives = tf.math.reduce_sum(mask_positives)
triplet_loss = tf.math.truediv(
tf.math.reduce_sum(
tf.math.maximum(tf.math.multiply(loss_mat, mask_positives), 0.0)
),
num_positives,
)
How to use those loss?
Both loss expect y_true to be provided as 1-D integer Tensor with shape [batch_size] of multi-class integer labels. And embeddings y_pred must be 2-D float Tensor of l2 normalized embedding vectors.
Example code to prepare the inputs and labels:
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(16)
train_dataset = train_dataset.map(_normalize_img)
# Take one batch of data
for data in train_dataset.take(1):
print("Batch of images shape:\n{}\nBatch of labels:\n{}\n".format(data[0].shape, data[1]))
Outputs:
Batch of images shape:
(16, 28, 28, 1)
Batch of labels:
[8 4 0 3 2 4 5 1 0 5 7 0 2 6 4 9]
Following this official tutorial about how to using TripletSemiHardLoss (TripletHardLoss as well) in general if you have problem when using it.
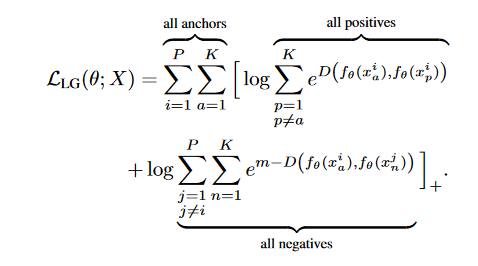
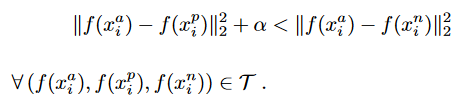
tflosses are correct? I mean they are implementingOnline Triplet Miningright? Where we don't even have to choose the triplets and losses takes care of that. Right? – Heligoland