Take this very simple example HTML:
<html>
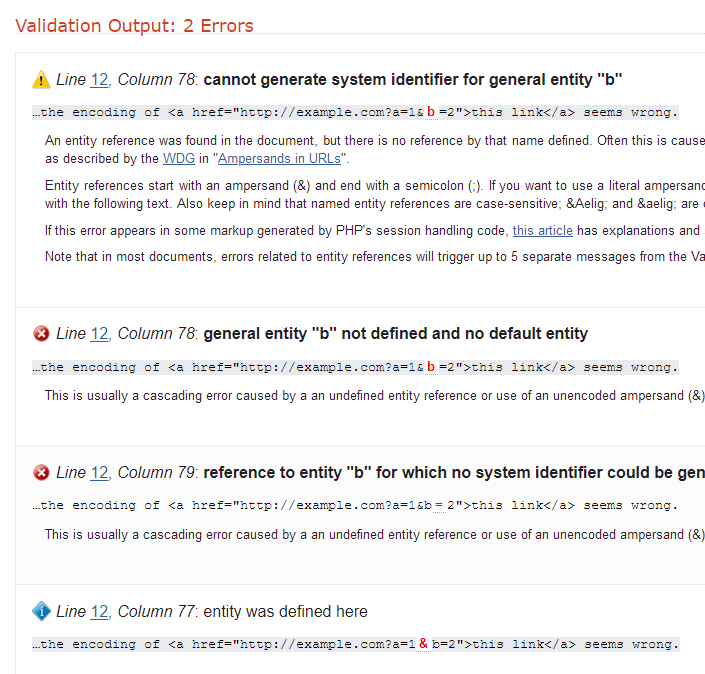
<body>This is okay & fine, but the encoding of <a href="http://example.com?a=1&b=2">this link</a> seems wrong.</body>
<html>
On examining document.body.innerHTML (e.g. in the browser's JS console, in JS itself, etc.), this is the value I see:
This is okay & fine, but the encoding of <a href="http://example.com?a=1&b=2">this link</a> seems wrong.
This behaviour is the same across browsers but I can't understand it, it seems wrong.
Specifically, the link in the orginal document is to http://example.com?a=1&b=2, whereas if the value of innerHTML is treated as HTML then it links to http://example.com?a=1&b=2 which is NOT the same (e.g. If I created a new document, which actually had innerHTML as its inner HTML, and I clicked on the link then the browser would be sent to a materially different URL as far as I can see).
(EDIT #3: I'm wrong about the above. Firstly, yes, those two URLs are different; but secondly, the innerHTML which I thought was wrong is right, and it correctly represents the first URL, not the second! See the end of my own answer below.)
This is different from the issue discussed in question innerHTML gives me & as & !. In my case (which is the opposite to the case in that question) the original HTML is correct and it looks to me as if it is the innerHTML which is wrong (i.e. because it is HTML which does not represent what the original HTML represented).
(EDIT #2: I was wrong about this, too: it's not really different. But I think it is not widely known that & is the correct way to represent & inside an href, not just within body text. Once you realise that, then you can see that these are the same issue really.)
Can anyone explain this?
(EDIT #1+4: This only occurred to me a bit late, after writing my original question, but: "is & actually correct within the href text, and & technically incorrect?" As I said when I first wrote those words, that "seems very unlikely! I've certainly never seen HTML written that way." But however 'unlikely', or not, that is the case, and is the main part of what I wasn't understanding!)
Also related and would be useful, can anyone explain how to cleanly get HTML which does correctly represent the target of document links? You definitely can't just un-encode all HTML character references within innerHTML, because (as shown in the example I've used, and also as discussed in innerHTML gives me & as & !) the ones in the main run of text should be encoded, and just un-encoding everything would make these wrong.
I originally thought this was not a duplicate of innerHTML gives me & as & ! (as discussed above; and in a way it still isn't, if it's agreed that it's not as obvious or widely known that the same issues apply inside href as in body text). It's still definitely not a duplicate of A href in innerHTML (which somehwat unclearly asks about how to set innerHTML using JS).
innerHTMLlook indocument.getElementsByTagName("a")[0].href(== "example.com/?a=1&b=2"). This is specifically for the first<a>tag - modify as needed. – BucherinnerHTMLfrom an HTML editing component to use as a template elsewhere, so I think it would be hard to stick those back in the right place. But still that's a useful alternative to know about - thanks! – IodisminnerTextwill not encode the text, and get the literal text within the html (also will strip any kind of other content when you have nested elements inside a non-aelement. – Lunette