I want to make a program to recognize the digit in an image. I follow the tutorial in scikit learn .
I can train and fit the svm classifier like the following.
First, I import the libraries and dataset
from sklearn import datasets, svm, metrics
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
Second, I create the SVM model and train it with the dataset.
classifier = svm.SVC(gamma = 0.001)
classifier.fit(data[:n_samples], digits.target[:n_samples])
And then, I try to read my own image and use the function predict() to recognize the digit.
Here is my image:

I reshape the image into (8, 8) and then convert it to a 1D array.
img = misc.imread("w1.jpg")
img = misc.imresize(img, (8, 8))
img = img[:, :, 0]
Finally, when I print out the prediction, it returns [1]
predicted = classifier.predict(img.reshape((1,img.shape[0]*img.shape[1] )))
print predicted
Whatever I user others images, it still returns [1]


When I print out the "default" dataset of number "9", it looks like: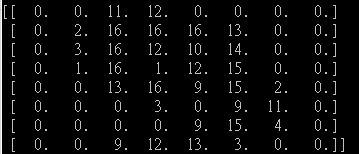
My image number "9" :
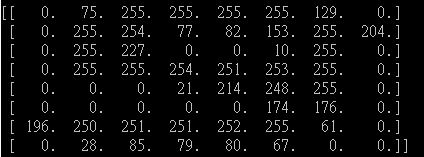
You can see the non-zero number is quite large for my image.
I dont know why. I am looking for help to solve my problem.