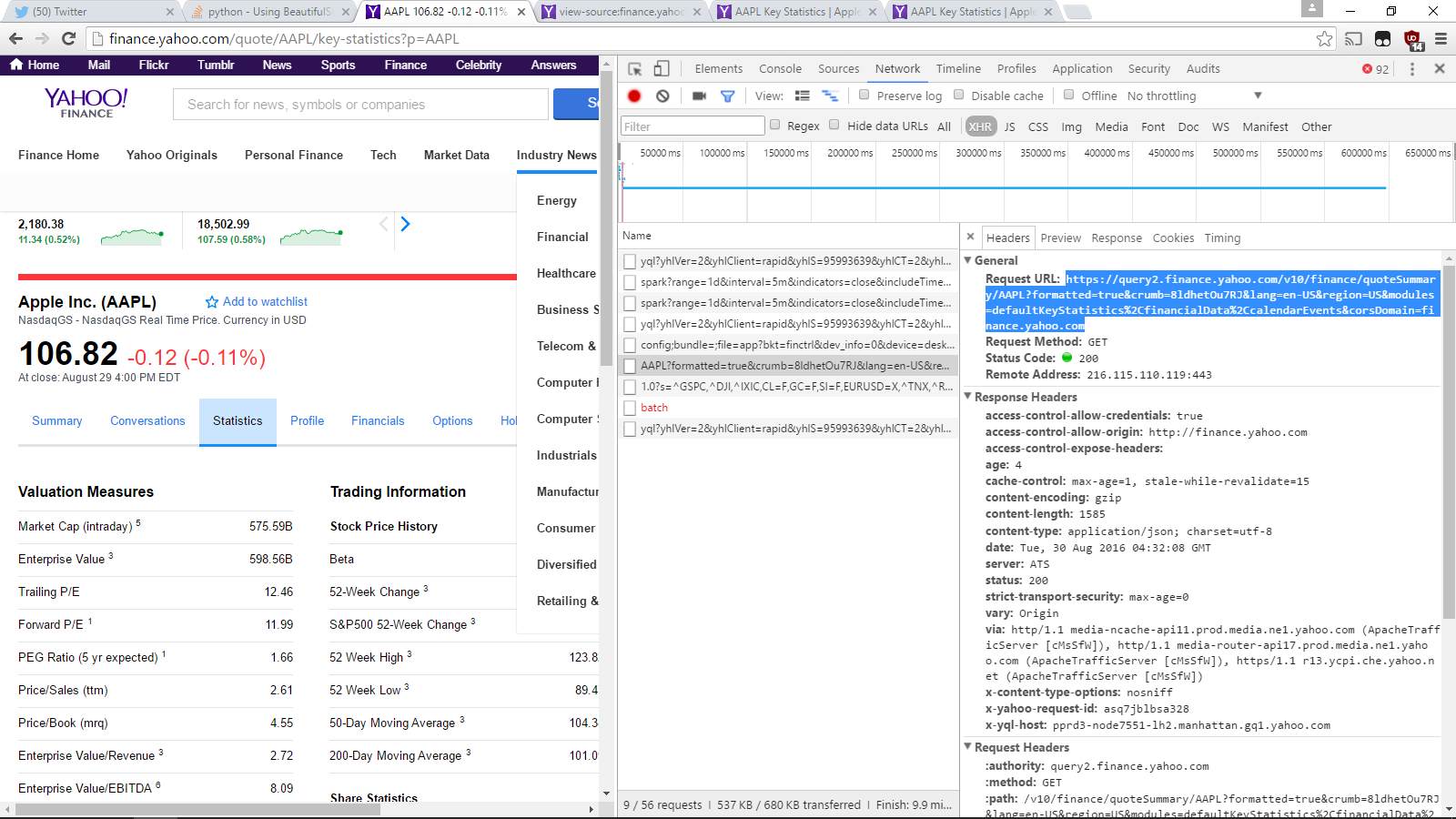
Well, the reason the list that find_all returns is empty is because that data is generated with a separate call that isn't completed by just sending a GET request to that URL. If you look through the Network tab on Chrome/Firefox and filter by XHR, by examining the requests and responses of each network action, you can find what you URL you ought to be sending the GET request too.
In this case, it's https://query2.finance.yahoo.com/v10/finance/quoteSummary/AAPL?formatted=true&crumb=8ldhetOu7RJ&lang=en-US®ion=US&modules=defaultKeyStatistics%2CfinancialData%2CcalendarEvents&corsDomain=finance.yahoo.com, as we can see here:
![enter image description here]()
So, how do we recreate this? Simple! :
from bs4 import BeautifulSoup
import requests
r = requests.get('https://query2.finance.yahoo.com/v10/finance/quoteSummary/AAPL?formatted=true&crumb=8ldhetOu7RJ&lang=en-US®ion=US&modules=defaultKeyStatistics%2CfinancialData%2CcalendarEvents&corsDomain=finance.yahoo.com')
data = r.json()
This will return the JSON response as a dict. From there, navigate through the dict until you find the data you're after:
financial_data = data['quoteSummary']['result'][0]['defaultKeyStatistics']
enterprise_value_dict = financial_data['enterpriseValue']
print(enterprise_value_dict)
>>> {'fmt': '598.56B', 'raw': 598563094528, 'longFmt': '598,563,094,528'}
print(enterprise_value_dict['fmt'])
>>> '598.56B'