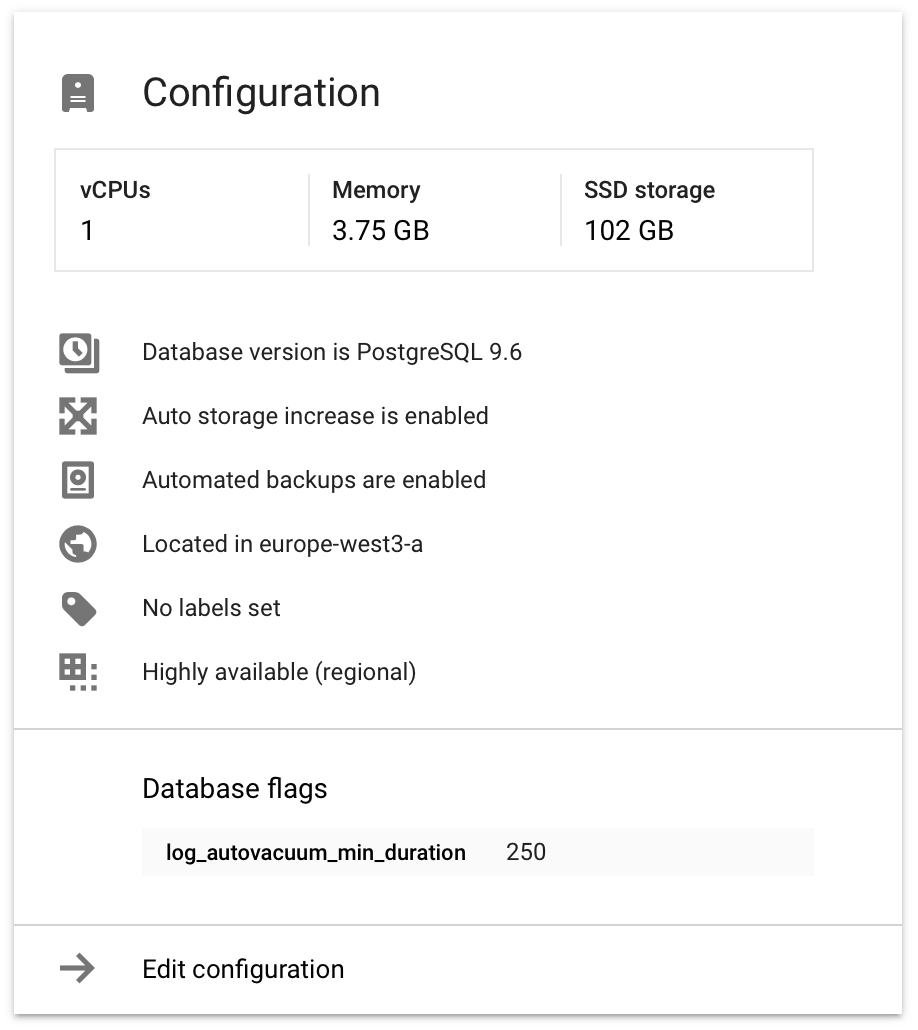
Our Postgres DB (hosted on Google Cloud SQL with 1 CPU, 3.7 GB of RAM, see below) consists mostly of one big ~90GB table with about ~60 million rows. The usage pattern consists almost exclusively of appends and a few indexed reads near the end of the table. From time to time a few users get deleted, deleting a small percentage of rows scattered across the table.
This all works fine, but every few months an autovacuum gets triggered on that table, which significantly impacts our service's performance for ~8 hours:
- Storage usage increases by ~1GB for the duration of the autovacuum (several hours), then slowly returns to the previous value (might eventually drop below it, due to the autovacuum freeing pages)
- Database CPU utilization jumps from <10% to ~20%
- Disk Read/Write Ops increases from near zero to ~50/second
- Database Memory increases slightly, but stays below 2GB
- Transaction/sec and ingress/egress bytes are also fairly unaffected, as would be expected
This has the effect of increasing our service's 95th latency percentile from ~100ms to ~0.5-1s during the autovacuum, which in turn triggers our monitoring. The service serves around ten requests per second, with each request consisting of a few simple DB reads/writes that normally have a latency of 2-3ms each.
Here are some monitoring screenshots illustrating the issue:
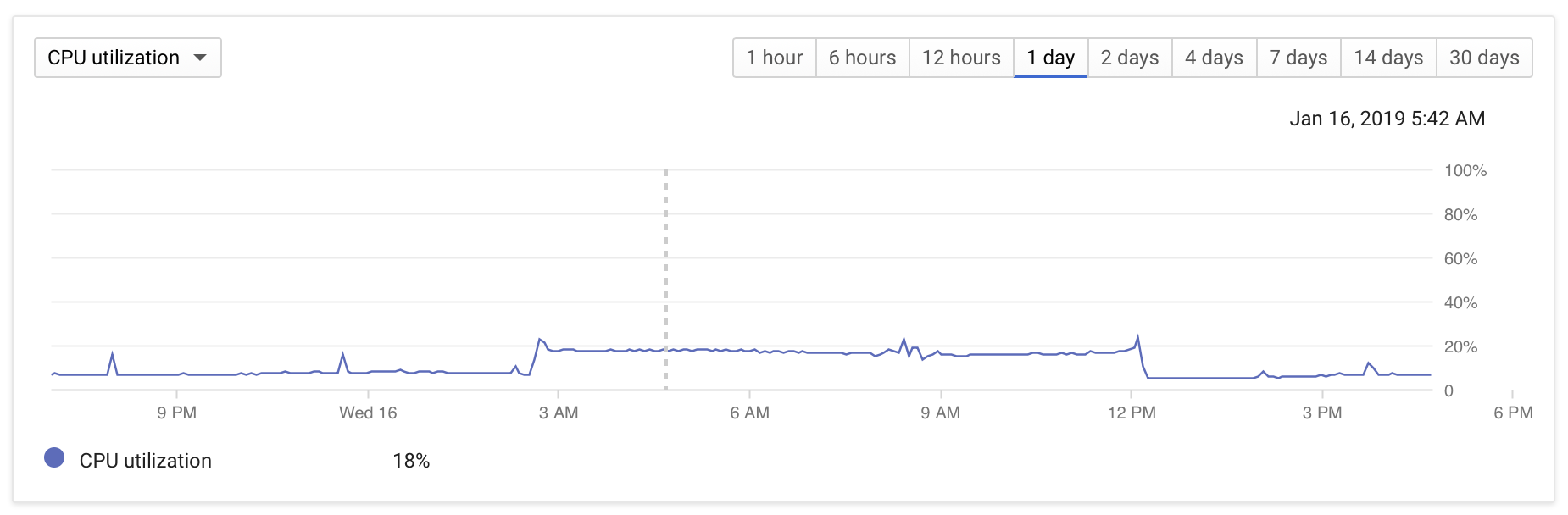
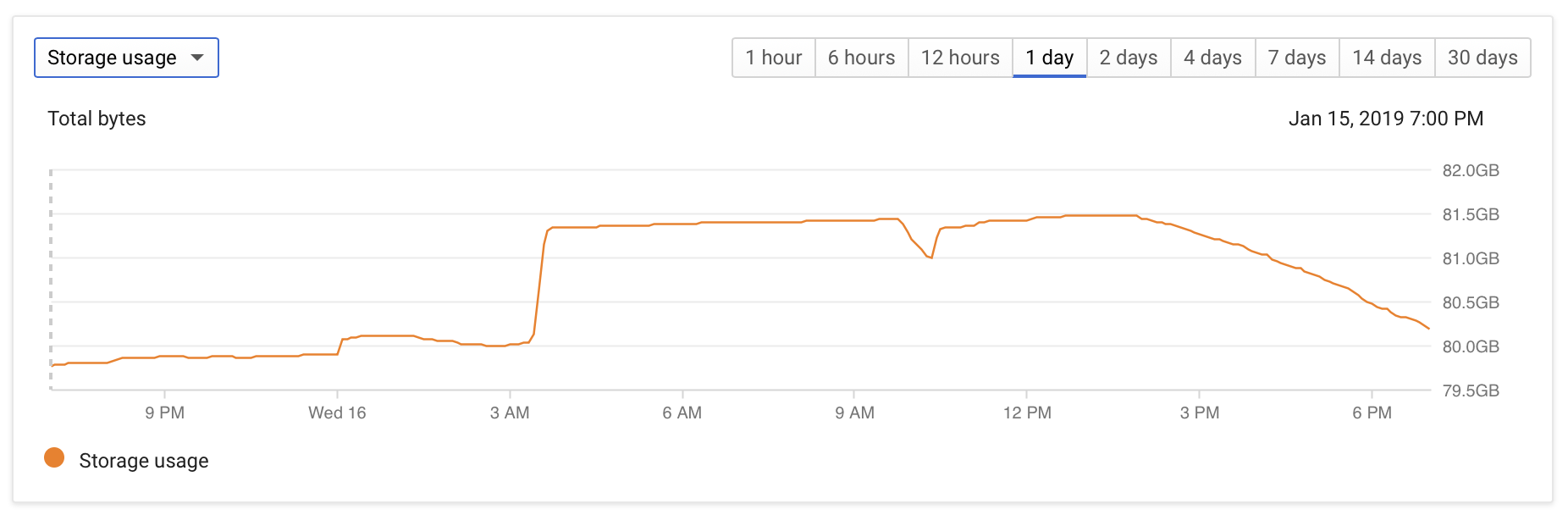
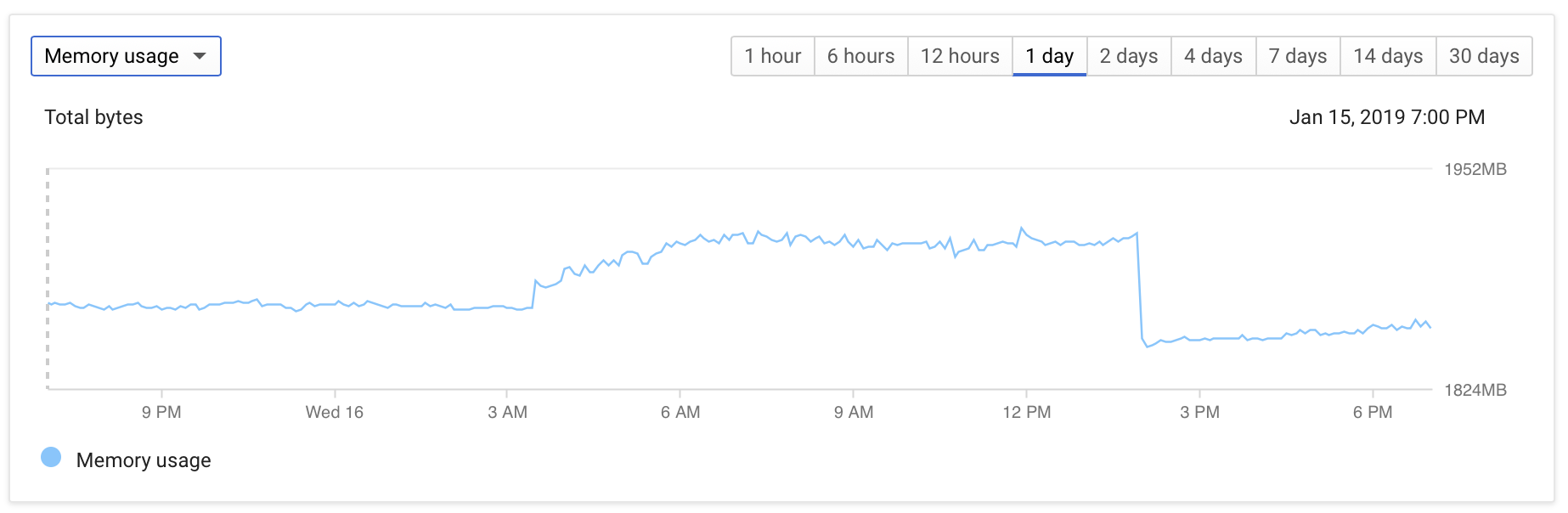
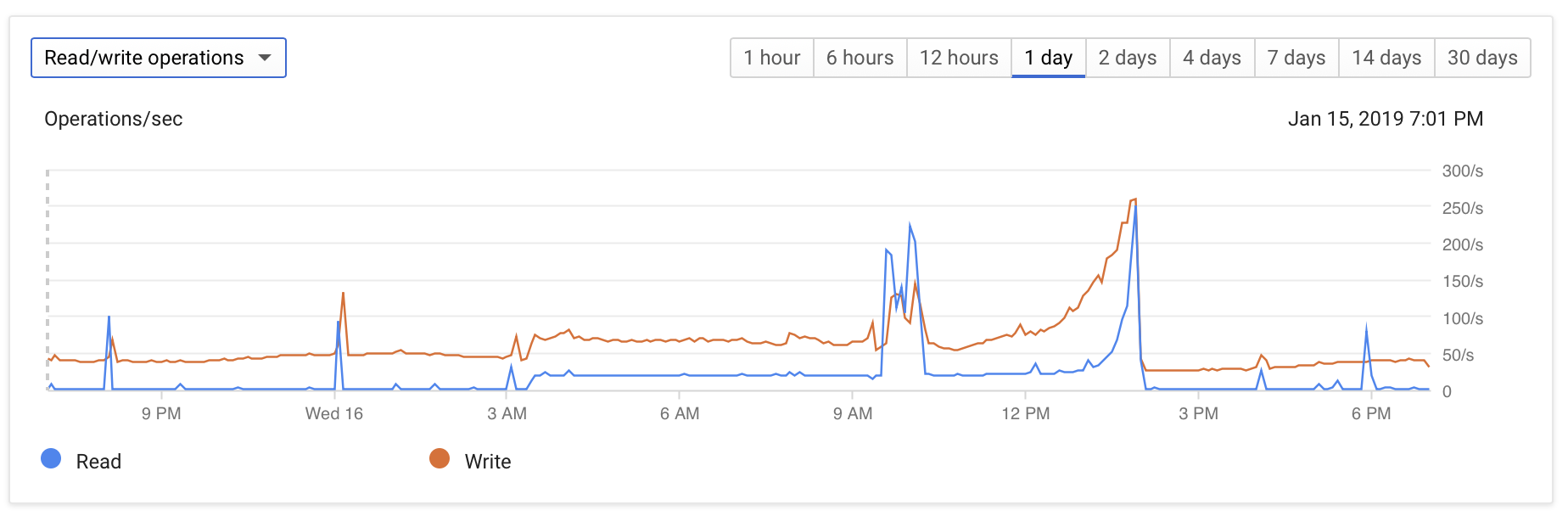
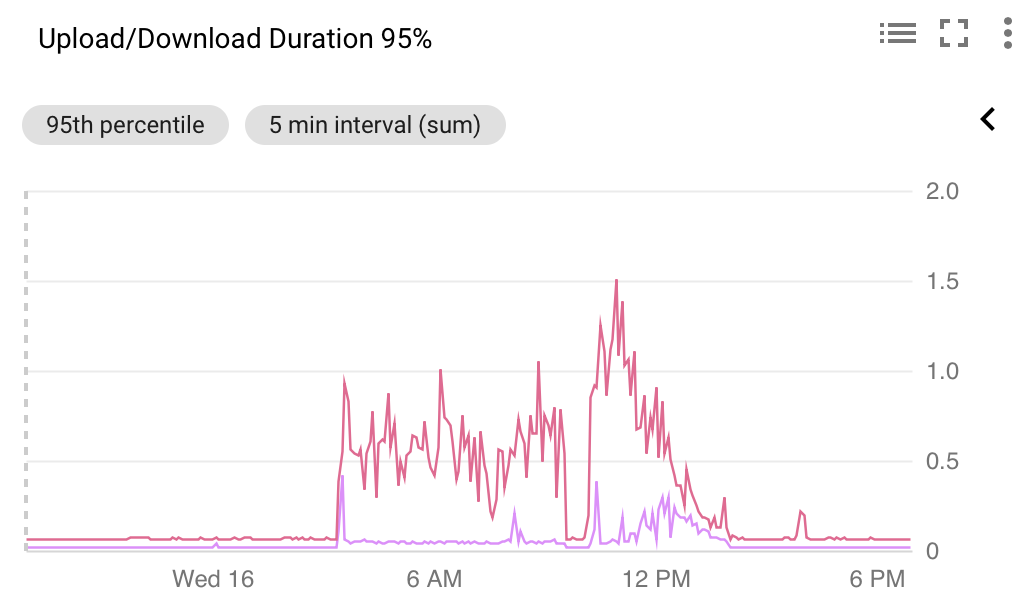
The DB configuration is fairly vanilla:
The log entry documenting this autovacuum process reads as follows:
system usage: CPU 470.10s/358.74u sec elapsed 38004.58 sec
avg read rate: 2.491 MB/s, avg write rate: 2.247 MB/s
buffer usage: 8480213 hits, 12117505 misses, 10930449 dirtied
tuples: 5959839 removed, 57732135 remain, 4574 are dead but not yet removable
pages: 0 removed, 6482261 remain, 0 skipped due to pins, 0 skipped frozen
automatic vacuum of table "XXX": index scans: 1
Any suggestions what we could tune to reduce the impact of future autovacuums on our service? Or are we doing something wrong?
autovacuum_vacuum_cost_delayand decreasingautovacuum_vacuum_cost_limithelped improve service performance, but of course makes theautovacuumtake longer (but that's fine). My suspicion is that Google's ~3k IOPS and 50 MB/s throughput limits (see cloud.google.com/compute/docs/disks/performance) for a 100 GB persistent disk are at fault here. – Hardtack