Objective: group pandas dataframe using a custom WMAPE (Weighted Mean Absolute Percent Error) function on multiple forecast columns and one actual data column, without for-loop. I know a for-loop & merges of output dataframes will do the trick. I want to do this efficiently.
Have: WMAPE function, successful use of WMAPE function on one forecast column of dataframe. One column of actual data, variable number of forecast columns.
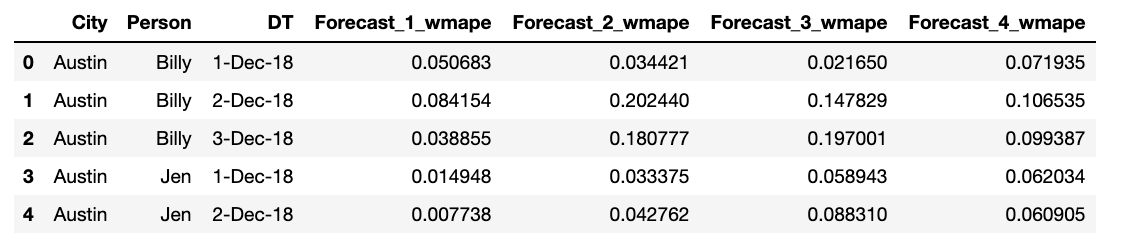
Input Data: Pandas DataFrame with several categorical columns (City, Person, DT, HOUR), one actual data column (Actual), and four forecast columns (Forecast_1 ... Forecast_4). See link for csv: https://www.dropbox.com/s/tidf9lj80a1dtd8/data_small_2.csv?dl=1
Need: WMAPE function applied during groupby on multiple columns with a list of forecast columns fed into groupby line.
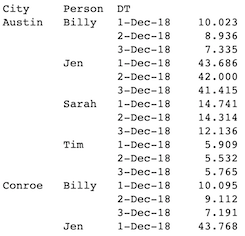
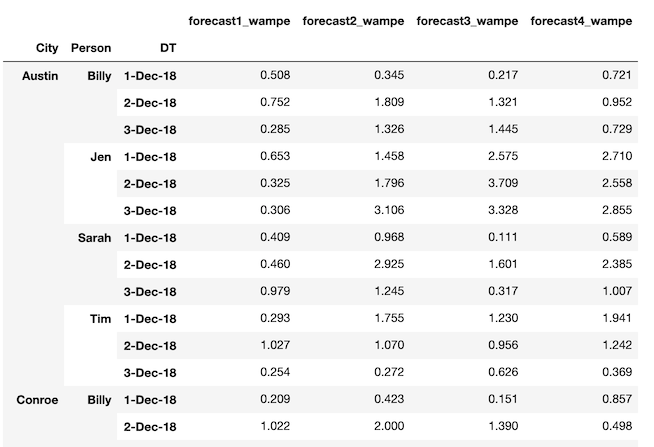
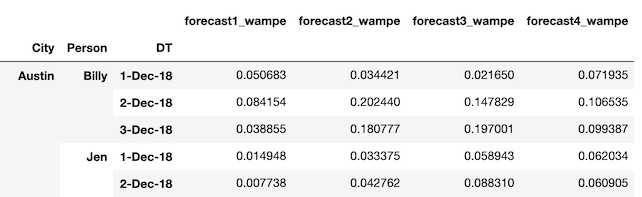
Output Desired: An output dataframe with categorical groups columns and all columns of WMAPE. Labeling is preferred but not needed (output image below).
Successful Code so far: Two WMAPE functions: one to take two series in & output a single float value (wmape), and one structured for use in a groupby (wmape_gr):
def wmape(actual, forecast):
# we take two series and calculate an output a wmape from it
# make a series called mape
se_mape = abs(actual-forecast)/actual
# get a float of the sum of the actual
ft_actual_sum = actual.sum()
# get a series of the multiple of the actual & the mape
se_actual_prod_mape = actual * se_mape
# summate the prod of the actual and the mape
ft_actual_prod_mape_sum = se_actual_prod_mape.sum()
# float: wmape of forecast
ft_wmape_forecast = ft_actual_prod_mape_sum / ft_actual_sum
# return a float
return ft_wmape_forecast
def wmape_gr(df_in, st_actual, st_forecast):
# we take two series and calculate an output a wmape from it
# make a series called mape
se_mape = abs(df_in[st_actual] - df_in[st_forecast]) / df_in[st_actual]
# get a float of the sum of the actual
ft_actual_sum = df_in[st_actual].sum()
# get a series of the multiple of the actual & the mape
se_actual_prod_mape = df_in[st_actual] * se_mape
# summate the prod of the actual and the mape
ft_actual_prod_mape_sum = se_actual_prod_mape.sum()
# float: wmape of forecast
ft_wmape_forecast = ft_actual_prod_mape_sum / ft_actual_sum
# return a float
return ft_wmape_forecast
# read in data directly from Dropbox
df = pd.read_csv('https://www.dropbox.com/s/tidf9lj80a1dtd8/data_small_2.csv?dl=1',sep=",",header=0)
# grouping with 3 columns. wmape_gr uses the Actual column, and Forecast_1 as inputs
df_gr = df.groupby(['City','Person','DT']).apply(wmape_gr,'Actual','Forecast_1')
Output Looks Like (first two rows):

Desired output would have all forecasts in one shot (dummy data for Forecast_2 ... Forecast_4). I can already do this with a for-loop. I just want to do it within the groupby. I want to call a wmape function four times. I would appreciate any assistance.