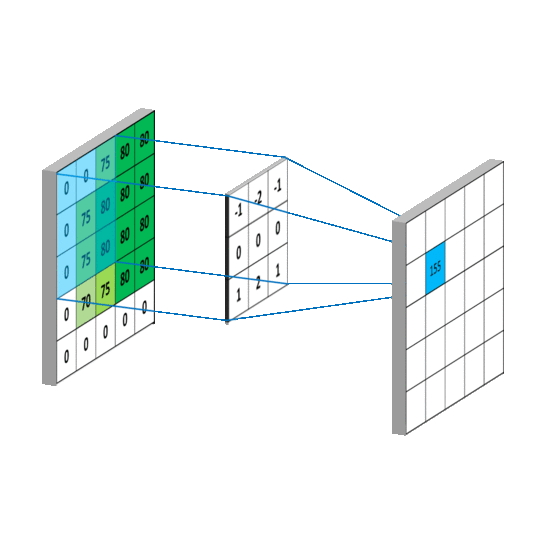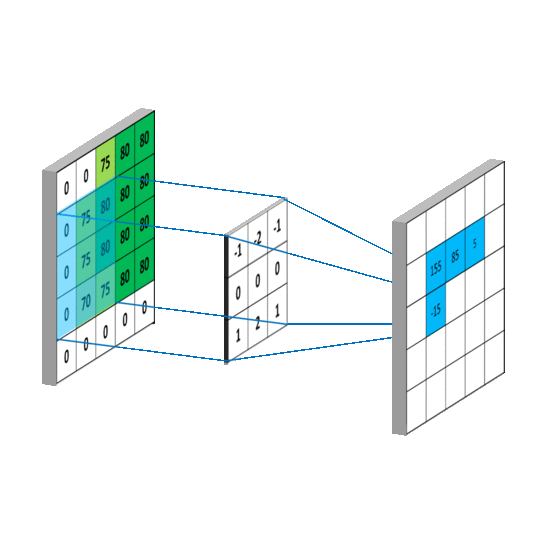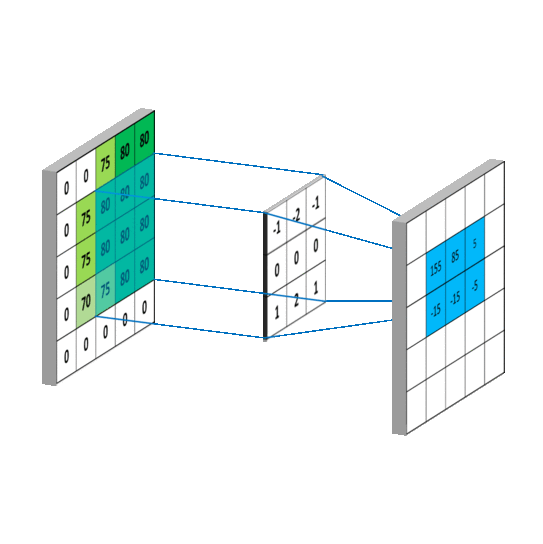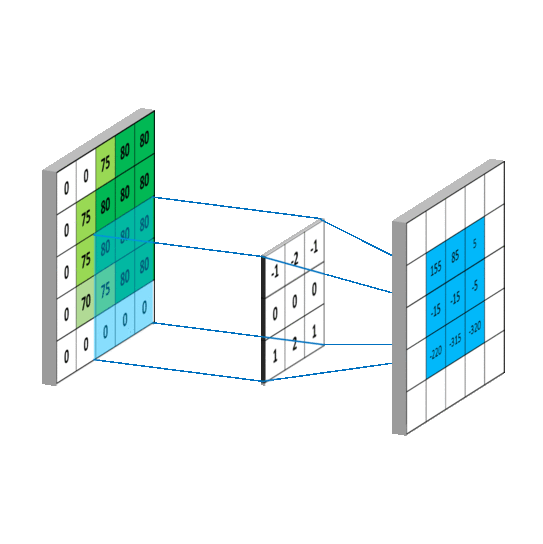
I'm learning image classification using PyTorch (using CIFAR-10 dataset) following this link.
I'm trying to understand the input & output parameters for the given Conv2d code:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
My conv2d() understanding (Please correct if I am wrong/missing anything):
- since image has 3 channels that's why first parameter is
3.6is no of filters (randomly chosen) 5is kernel size (5, 5) (randomly chosen)- likewise we create next layer (previous layer output is input of this layer)
- Now creating a fully connected layer using
linearfunction: self.fc1 = nn.Linear(16 * 5 * 5, 120)
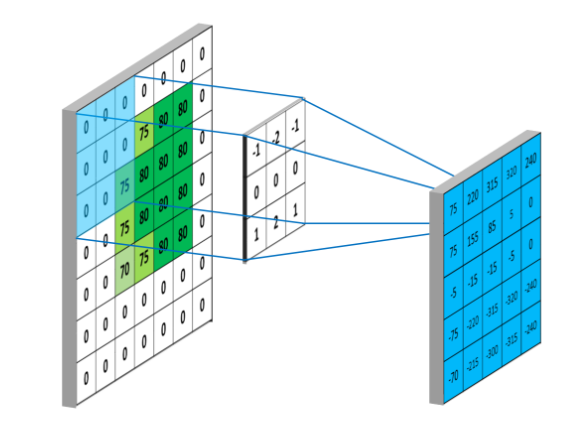
16 * 5 * 5: here 16 is the output of last conv2d layer, But what is 5 * 5 in this?.
Is this kernel size ? or something else? How to know we need to multiply by 5*5 or 4*4 or 3*3.....
I researched & got to know that since image size is 32*32, applying max pool(2) 2 times, so image size would be 32 -> 16 -> 8, so we should multiply it by last_ouput_size * 8 * 8 But in this link its 5*5.
Could anyone please explain?