While the proposed solution addresses the issue, it is likely that another problem will arise when dealing with larger datasets. pandas groupby is slow and memory hungry; may need 5-10x the memory of the dataset. A more effective solution is to use a tool that is order of magnitude faster, less memory hungry, and seamlessly integrates with pandas; it reads directly from the dataframe memory. No need for data round trip, and typically no need for extensive data chunking.
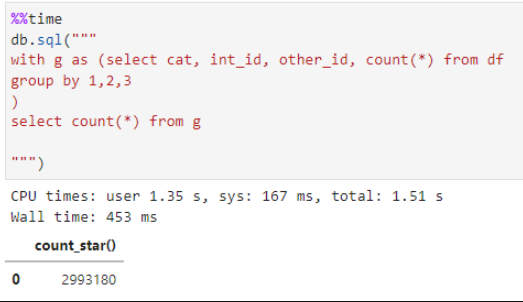
My new tool of choice for quick data aggregation is https://duckdb.org. It takes your existing dataframe df and query directly on it without even importing it into the database. Here is an example final result using your dataframe generation code. Notice that total time was 0.45sec. Not sure why pandas does not use DuckDB for the groupby under the hood.
![enter image description here]()
db object is created using this small wrapper class that allows you to simply just type db = DuckDB() and you are ready to explore the data in any project. You can expand this further or you can even simplify it using %sql using this documentation page: enter link description here. By the way, the sql returns a dataframe, so you can do also db.sql(...).pivot_table(...) it is that simple.
class DuckDB:
def __init__(self, db=None):
self.db_loc = db or ':memory:'
self.db = duckdb.connect(self.db_loc)
def sql(self, sql=""):
return self.db.execute(sql).fetchdf()
def __del__():
self.db.close()
Note: DuckDB is good but not perfect, but it turned way more stable than Dusk or even PySpark with much simpler set up. For larger data sets you may need a real database, but for datasets that can fit in memory this is great. Regarding memory usage, if you have a larger dataset ensure that you limite DuckDB using pragmas as it will eat it all in no time. Limit simply places extra onto disk without dealing with data chunking. Also do not assume that this is a database. Assume this is in-memory database, if you need some results stored, then just export them into parquet instead of saving the database. Because the format is not stable between releases and you will have to export to parquet anyway to move from one version to the next.
I expanded this data frame to 300mn records so in total it had around 1.2bn records or around 9GB. It still completed your groupby and other summary stats on a 32GB machine 18GB was still free.
![enter image description here]()

df['cat'] = df.cat.astype(str).astype('category')line and it works. Still trying to understand why – Erikgroupby.agg()operation with string and categorical variables in the index. Is there a link to a bug report? – Choking