I'm trying to understand why numpy's dot function behaves as it does:
M = np.ones((9, 9))
V1 = np.ones((9,))
V2 = np.ones((9, 5))
V3 = np.ones((2, 9, 5))
V4 = np.ones((3, 2, 9, 5))
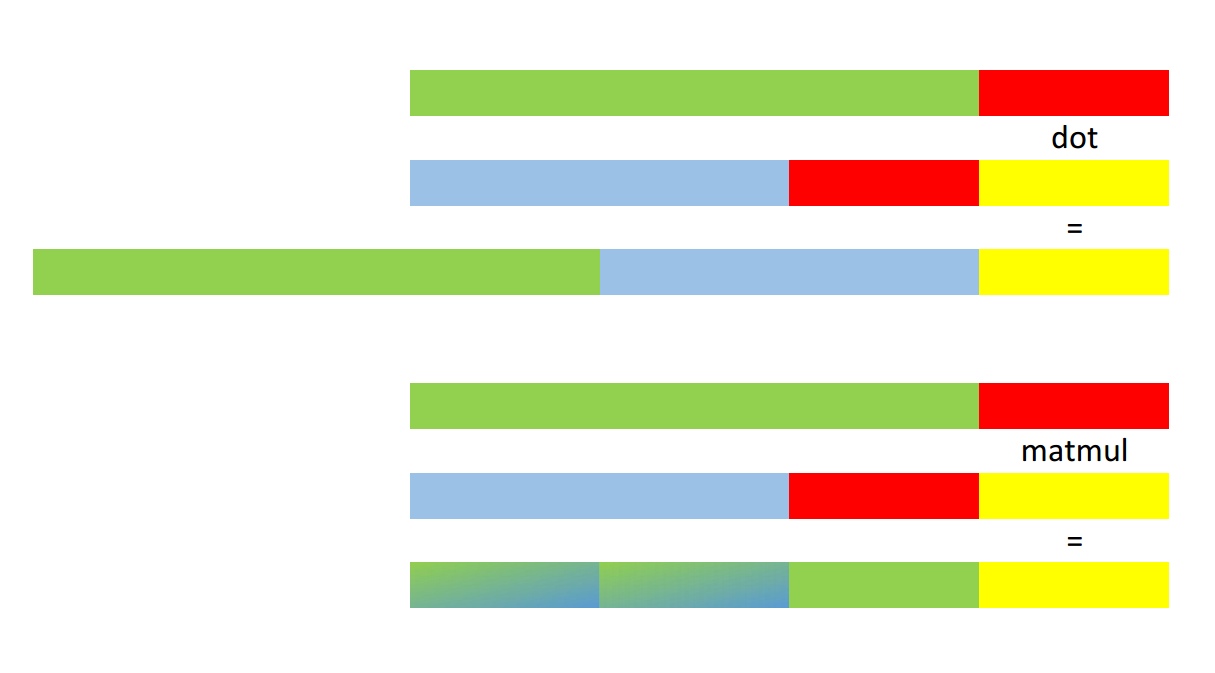
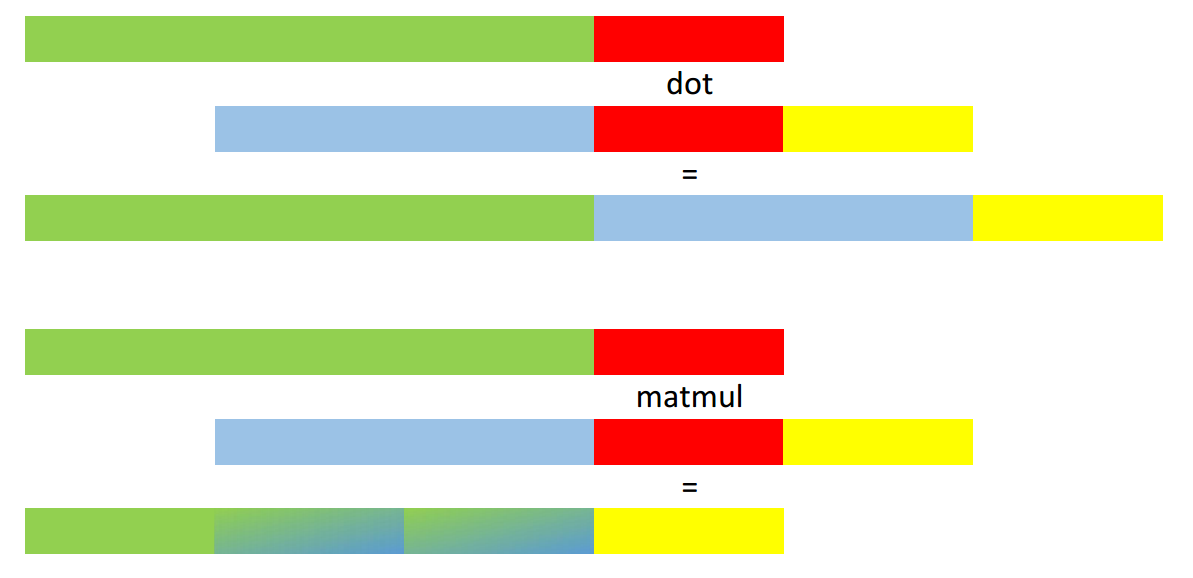
Now np.dot(M, V1) and np.dot(M, V2) behave as
expected. But for V3 and V4 the result surprises
me:
>>> np.dot(M, V3).shape
(9, 2, 5)
>>> np.dot(M, V4).shape
(9, 3, 2, 5)
I expected (2, 9, 5) and (3, 2, 9, 5) respectively. On the other hand, np.matmul
does what I expect: the matrix multiply is broadcast
over the first N - 2 dimensions of the second argument and
the result has the same shape:
>>> np.matmul(M, V3).shape
(2, 9, 5)
>>> np.matmul(M, V4).shape
(3, 2, 9, 5)
So my question is this: what is the rationale for
np.dot behaving as it does? Does it serve some particular purpose,
or is it the result of applying some general rule?

{kind=link}