Basically, what you want is:
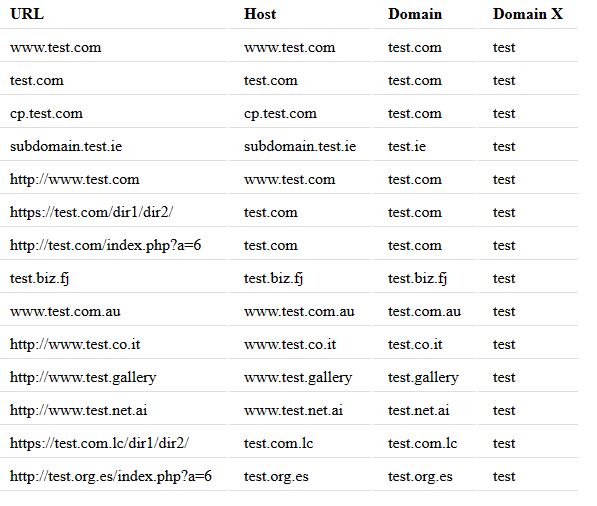
google.com -> google.com -> google
www.google.com -> google.com -> google
google.co.uk -> google.co.uk -> google
www.google.co.uk -> google.co.uk -> google
www.google.org -> google.org -> google
www.google.org.uk -> google.org.uk -> google
Optional:
www.google.com -> google.com -> www.google
images.google.com -> google.com -> images.google
mail.yahoo.co.uk -> yahoo.co.uk -> mail.yahoo
mail.yahoo.com -> yahoo.com -> mail.yahoo
www.mail.yahoo.com -> yahoo.com -> mail.yahoo
You don't need to construct an ever-changing regex as 99% of domains will be matched properly if you simply look at the 2nd last part of the name:
(co|com|gov|net|org)
If it is one of these, then you need to match 3 dots, else 2. Simple. Now, my regex wizardry is no match for that of some other SO'ers, so the best way I've found to achieve this is with some code, assuming you've already stripped off the path:
my @d=split /\./,$domain; # split the domain part into an array
$c=@d; # count how many parts
$dest=$d[$c-2].'.'.$d[$c-1]; # use the last 2 parts
if ($d[$c-2]=~m/(co|com|gov|net|org)/) { # is the second-last part one of these?
$dest=$d[$c-3].'.'.$dest; # if so, add a third part
};
print $dest; # show it
To just get the name, as per your question:
my @d=split /\./,$domain; # split the domain part into an array
$c=@d; # count how many parts
if ($d[$c-2]=~m/(co|com|gov|net|org)/) { # is the second-last part one of these?
$dest=$d[$c-3]; # if so, give the third last
$dest=$d[$c-4].'.'.$dest if ($c>3); # optional bit
} else {
$dest=$d[$c-2]; # else the second last
$dest=$d[$c-3].'.'.$dest if ($c>2); # optional bit
};
print $dest; # show it
I like this approach because it's maintenance-free. Unless you want to validate that it's actually a legitimate domain, but that's kind of pointless because you're most likely only using this to process log files and an invalid domain wouldn't find its way in there in the first place.
If you'd like to match "unofficial" subdomains such as bozo.za.net, or bozo.au.uk, bozo.msf.ru just add (za|au|msf) to the regex.
I'd love to see someone do all of this using just a regex, I'm sure it's possible.
{kind=link}
http://en.wikipedia.org/wiki/URL, the domain name in that URL isen.wikipedia.org– Chickweed