Is there any performance difference between tuples and lists when it comes to instantiation and retrieval of elements?
Are tuples more efficient than lists in Python?
Asked Answered
Related: "Why is tuple faster than list?" –
Plywood
If you are interested in memory used between varies type see this plot I made: https://mcmap.net/q/18867/-data-size-in-memory-vs-on-disk –
Barrick
The dis module disassembles the byte code for a function and is useful to see the difference between tuples and lists.
In this case, you can see that accessing an element generates identical code, but that assigning a tuple is much faster than assigning a list.
>>> def a():
... x=[1,2,3,4,5]
... y=x[2]
...
>>> def b():
... x=(1,2,3,4,5)
... y=x[2]
...
>>> import dis
>>> dis.dis(a)
2 0 LOAD_CONST 1 (1)
3 LOAD_CONST 2 (2)
6 LOAD_CONST 3 (3)
9 LOAD_CONST 4 (4)
12 LOAD_CONST 5 (5)
15 BUILD_LIST 5
18 STORE_FAST 0 (x)
3 21 LOAD_FAST 0 (x)
24 LOAD_CONST 2 (2)
27 BINARY_SUBSCR
28 STORE_FAST 1 (y)
31 LOAD_CONST 0 (None)
34 RETURN_VALUE
>>> dis.dis(b)
2 0 LOAD_CONST 6 ((1, 2, 3, 4, 5))
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (2)
12 BINARY_SUBSCR
13 STORE_FAST 1 (y)
16 LOAD_CONST 0 (None)
19 RETURN_VALUE
Err, just that the same bytecode is generated absolutely does not mean the same operations happen at the C (and therefore cpu) level. Try creating a class
ListLike with a __getitem__ that does something horribly slow, then disassemble x = ListLike((1, 2, 3, 4, 5)); y = x[2]. The bytecode will be more like the tuple example above than the list example, but do you really believe that means performance will be similar? –
Edmond It seems you're saying that that some types are more efficient than others. That makes sense, but the overhead of list and tuple generations seems to be orthogonal to the data type involved, with the caveat that they are lists and tuples of the same data type. –
Harrier
Number of byte-codes, like number of lines-of-code, bears little relationship to speed-of-execution (and therefore efficiency and performance). –
Rhodian
Although the suggestion you can conclude anything from counting ops is misguided, this does show the key difference: constant tuples are stored as such in the bytecode and just referenced when used, whereas lists need to be built at runtime. –
Phrensy
This answer shows us that Python acknowledges tuple constants. That's good to know! But what happens when trying to build a tuple or a list from variable values? –
Audun
In Python >= 3.9, whole items of both
list and tuple will store in one LOAD_CONST opname. –
Market Summary
Tuples tend to perform better than lists in almost every category:
Tuples can be constant folded.
Tuples can be reused instead of copied.
Tuples are compact and don't over-allocate.
Tuples directly reference their elements.
Tuples can be constant folded
Tuples of constants can be precomputed by Python's peephole optimizer or AST-optimizer. Lists, on the other hand, get built-up from scratch:
>>> from dis import dis
>>> dis(compile("(10, 'abc')", '', 'eval'))
1 0 LOAD_CONST 2 ((10, 'abc'))
3 RETURN_VALUE
>>> dis(compile("[10, 'abc']", '', 'eval'))
1 0 LOAD_CONST 0 (10)
3 LOAD_CONST 1 ('abc')
6 BUILD_LIST 2
9 RETURN_VALUE
Tuples do not need to be copied
Running tuple(some_tuple) returns immediately itself. Since tuples are immutable, they do not have to be copied:
>>> a = (10, 20, 30)
>>> b = tuple(a)
>>> a is b
True
In contrast, list(some_list) requires all the data to be copied to a new list:
>>> a = [10, 20, 30]
>>> b = list(a)
>>> a is b
False
Tuples do not over-allocate
Since a tuple's size is fixed, it can be stored more compactly than lists which need to over-allocate to make append() operations efficient.
This gives tuples a nice space advantage:
>>> import sys
>>> sys.getsizeof(tuple(iter(range(10))))
128
>>> sys.getsizeof(list(iter(range(10))))
200
Here is the comment from Objects/listobject.c that explains what lists are doing:
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
* Note: new_allocated won't overflow because the largest possible value
* is PY_SSIZE_T_MAX * (9 / 8) + 6 which always fits in a size_t.
*/
Tuples refer directly to their elements
References to objects are incorporated directly in a tuple object. In contrast, lists have an extra layer of indirection to an external array of pointers.
This gives tuples a small speed advantage for indexed lookups and unpacking:
$ python3.6 -m timeit -s 'a = (10, 20, 30)' 'a[1]'
10000000 loops, best of 3: 0.0304 usec per loop
$ python3.6 -m timeit -s 'a = [10, 20, 30]' 'a[1]'
10000000 loops, best of 3: 0.0309 usec per loop
$ python3.6 -m timeit -s 'a = (10, 20, 30)' 'x, y, z = a'
10000000 loops, best of 3: 0.0249 usec per loop
$ python3.6 -m timeit -s 'a = [10, 20, 30]' 'x, y, z = a'
10000000 loops, best of 3: 0.0251 usec per loop
Here is how the tuple (10, 20) is stored:
typedef struct {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
PyObject *ob_item[2]; /* store a pointer to 10 and a pointer to 20 */
} PyTupleObject;
Here is how the list [10, 20] is stored:
PyObject arr[2]; /* store a pointer to 10 and a pointer to 20 */
typedef struct {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
PyObject **ob_item = arr; /* store a pointer to the two-pointer array */
Py_ssize_t allocated;
} PyListObject;
Note that the tuple object incorporates the two data pointers directly while the list object has an additional layer of indirection to an external array holding the two data pointers.
Internally, tuples are stored a little more efficiently than lists, and also tuples can be accessed slightly faster. How could you explain the results from dF.'s answer then? –
Agustinaah When working with ~50k lists of ~100 element lists, moving this structure to tuples decreased lookup times by multiple orders of magnitude for multiple lookups. I believe this to be due to the greater cache locality of the tuple once you start using the tuple due to the removal of the second layer of indirection you demonstrate. –
Gamine
tuple(some_tuple) only returns some_tuple itself if some_tuple is hashable—when its contents are recursively immutable and hashable. Otherwise, tuple(some_tuple) returns a new tuple. For example, when some_tuple contains mutable items. –
Byrann Tuples are not always faster .Consider ``` t=() for i in range(1,100): t+=i l = [] for i in range(1,1000): a.append(i) ``` The second one is faster –
Doorpost
@LucianoRamalho Your comment is easily shown to be incorrect:
t = (10, 20, [30, 40], 50); tuple(t) is s returns True. The reason is that tuple(sometuple) is only required to make a shallow copy, so it is allowed to reuse the sometuple without examining its contents. –
Sophrosyne @melvil james Your understanding of tuples is incorrect here, tuples are immutable, so when you perform
t+=i, what you think happens is adding elements to same element, however in reality you are creating a new tuple at every iteration by adding elements of previous tuple and that's why this operation is slow, with list version you are appending to same list. –
Buttress If
PyTupleObject's PyObject *ob_item[2]; stores the two pointers to the two objects, i.e., the number of pointers is hardcoded as 2, then how can there be tuples with more than two elements? Something isn't right. The version linked to by @ead even only has PyObject *ob_item[1];. How does that work? –
Georgetown @Gamine "multiple orders of magnitude"? I highly doubt that's due to not having that indirection, more likely the tuple version "cheated" somehow (e.g., they were found by identity rather than by equality, or you even also changed the outer list to a set). –
Georgetown
In general, you might expect tuples to be slightly faster. However you should definitely test your specific case (if the difference might impact the performance of your program -- remember "premature optimization is the root of all evil").
Python makes this very easy: timeit is your friend.
$ python -m timeit "x=(1,2,3,4,5,6,7,8)"
10000000 loops, best of 3: 0.0388 usec per loop
$ python -m timeit "x=[1,2,3,4,5,6,7,8]"
1000000 loops, best of 3: 0.363 usec per loop
and...
$ python -m timeit -s "x=(1,2,3,4,5,6,7,8)" "y=x[3]"
10000000 loops, best of 3: 0.0938 usec per loop
$ python -m timeit -s "x=[1,2,3,4,5,6,7,8]" "y=x[3]"
10000000 loops, best of 3: 0.0649 usec per loop
So in this case, instantiation is almost an order of magnitude faster for the tuple, but item access is actually somewhat faster for the list! So if you're creating a few tuples and accessing them many many times, it may actually be faster to use lists instead.
Of course if you want to change an item, the list will definitely be faster since you'd need to create an entire new tuple to change one item of it (since tuples are immutable).
What version of python were your tests with! –
Football
@Matt Not sure, but just re-ran them under 2.6.6 (on mac) and get basically the same results. –
Sinh
There is another interesting test -
python -m timeit "x=tuple(xrange(999999))" vs python -m timeit "x=list(xrange(999999))". As one might expect, it takes a bit longer to materialize a tuple than a list. –
Booted @HamishGrubijan Why might one expect that? –
Sam
@gerrit, a tuple is of fixed size while a list is not. A tuple takes less space in memory than a list stackoverflow.com/questions/449560/…. Therefore, when constructing a tuple from a generator of an unknown size, there must be an extra effort of releasing unused buffer space, whereas a list would not need to do so. That is what I guessed. –
Booted
on the other hand, the same timeit for a very short list (xrange(10)) is slightly faster with tuples, (of course, these are measured in the usec range, so unless you are doing a lot of them, it probably won't matter) –
Bangs
@HamishGrubijan perhaps
xrange is not a good example, because the size is known (try len(xrange(999999))). However, I see your point with a general generator. –
Freed Seems bizarre that tuple access is slower than list access. However, trying that in Python 2.7 on my Windows 7 PC, the difference is only 10%, so unimportant. –
Stadler
FWIW, list access is faster that tuple access in Python 2 but only because there is a special case for lists in BINARY_SUBSCR in Python/ceval.c. In Python 3, that optimization is gone, and tuples access becomes slighty faster than list access. –
Sophrosyne
@Sinh Why is the first timing (
0.363 usec) of list 5 times slower than the second(0.0649 usec)? I cannot reproduce that. –
Wellrounded The first test is probably wrong. You are assigning a tuple of constants, which is a constant, so the compiler creates the tuple as a code constant instead of generating code to create it. –
Circumbendibus
@yoopoo, the first test creates a list a million times, but the second creates a list once and accesses it a million times. The
-s "SETUP_CODE" is run before the actual timed code. –
Circumbendibus @RaymondHettinger FWIW, it seems that was the case in python 3.8.10 (tests give approximately the same time), but in python 3.9.7(which wasn't a thing) some optimization was added back in and list access is about twice as fast for my tests –
Desiree
@AdrienLevert I'm unable to reproduce your result with a fresh download of 3.8, 3.9, and 3.10. These all give timings similar to those shown above. Looking at the source code confirms that the BINARY_SUBSCR opcode has not changed: github.com/python/cpython/blob/… –
Sophrosyne
The dis module disassembles the byte code for a function and is useful to see the difference between tuples and lists.
In this case, you can see that accessing an element generates identical code, but that assigning a tuple is much faster than assigning a list.
>>> def a():
... x=[1,2,3,4,5]
... y=x[2]
...
>>> def b():
... x=(1,2,3,4,5)
... y=x[2]
...
>>> import dis
>>> dis.dis(a)
2 0 LOAD_CONST 1 (1)
3 LOAD_CONST 2 (2)
6 LOAD_CONST 3 (3)
9 LOAD_CONST 4 (4)
12 LOAD_CONST 5 (5)
15 BUILD_LIST 5
18 STORE_FAST 0 (x)
3 21 LOAD_FAST 0 (x)
24 LOAD_CONST 2 (2)
27 BINARY_SUBSCR
28 STORE_FAST 1 (y)
31 LOAD_CONST 0 (None)
34 RETURN_VALUE
>>> dis.dis(b)
2 0 LOAD_CONST 6 ((1, 2, 3, 4, 5))
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (2)
12 BINARY_SUBSCR
13 STORE_FAST 1 (y)
16 LOAD_CONST 0 (None)
19 RETURN_VALUE
Err, just that the same bytecode is generated absolutely does not mean the same operations happen at the C (and therefore cpu) level. Try creating a class
ListLike with a __getitem__ that does something horribly slow, then disassemble x = ListLike((1, 2, 3, 4, 5)); y = x[2]. The bytecode will be more like the tuple example above than the list example, but do you really believe that means performance will be similar? –
Edmond It seems you're saying that that some types are more efficient than others. That makes sense, but the overhead of list and tuple generations seems to be orthogonal to the data type involved, with the caveat that they are lists and tuples of the same data type. –
Harrier
Number of byte-codes, like number of lines-of-code, bears little relationship to speed-of-execution (and therefore efficiency and performance). –
Rhodian
Although the suggestion you can conclude anything from counting ops is misguided, this does show the key difference: constant tuples are stored as such in the bytecode and just referenced when used, whereas lists need to be built at runtime. –
Phrensy
This answer shows us that Python acknowledges tuple constants. That's good to know! But what happens when trying to build a tuple or a list from variable values? –
Audun
In Python >= 3.9, whole items of both
list and tuple will store in one LOAD_CONST opname. –
Market Tuples, being immutable, are more memory efficient; lists, for speed efficiency, overallocate memory in order to allow appends without constant reallocs. So, if you want to iterate through a constant sequence of values in your code (eg for direction in 'up', 'right', 'down', 'left':), tuples are preferred, since such tuples are pre-calculated in compile time.
Read-access speeds should be the same (they are both stored as contiguous arrays in the memory).
But, alist.append(item) is much preferred to atuple+= (item,) when you deal with mutable data. Remember, tuples are intended to be treated as records without field names.
what is compile time in python? –
Juicy
@balki: the time when python source is compiled to bytecode (which bytecode might be saved as a .py[co] file). –
Photomural
A citation would be great if possible. –
Infelicitous
Here is another little benchmark, just for the sake of it..
In [11]: %timeit list(range(100))
749 ns ± 2.41 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [12]: %timeit tuple(range(100))
781 ns ± 3.34 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [1]: %timeit list(range(1_000))
13.5 µs ± 466 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
In [2]: %timeit tuple(range(1_000))
12.4 µs ± 182 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
In [7]: %timeit list(range(10_000))
182 µs ± 810 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [8]: %timeit tuple(range(10_000))
188 µs ± 2.38 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [3]: %timeit list(range(1_00_000))
2.76 ms ± 30.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [4]: %timeit tuple(range(1_00_000))
2.74 ms ± 31.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [10]: %timeit list(range(10_00_000))
28.1 ms ± 266 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [9]: %timeit tuple(range(10_00_000))
28.5 ms ± 447 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Let's average these out:
In [3]: l = np.array([749 * 10 ** -9, 13.5 * 10 ** -6, 182 * 10 ** -6, 2.76 * 10 ** -3, 28.1 * 10 ** -3])
In [2]: t = np.array([781 * 10 ** -9, 12.4 * 10 ** -6, 188 * 10 ** -6, 2.74 * 10 ** -3, 28.5 * 10 ** -3])
In [11]: np.average(l)
Out[11]: 0.0062112498000000006
In [12]: np.average(t)
Out[12]: 0.0062882362
In [17]: np.average(t) / np.average(l) * 100
Out[17]: 101.23946713590554
You can call it almost inconclusive.
But sure, tuples took 101.239% the time, or 1.239% extra time to do the job compared to lists.
Can you state which python version you used? –
Arita
You should also consider the array module in the standard library if all the items in your list or tuple are of the same C type. It will take less memory and can be faster.
It'll take less memory, but access time will probably be a bit slower, rather than faster. Accessing an element requires the packed value to be unboxed to a real integer, which will slow the process down. –
Delibes
Tuples perform better but if all the elements of tuple are immutable. If any element of a tuple is mutable a list or a function, it will take longer to be compiled. here I compiled 3 different objects:
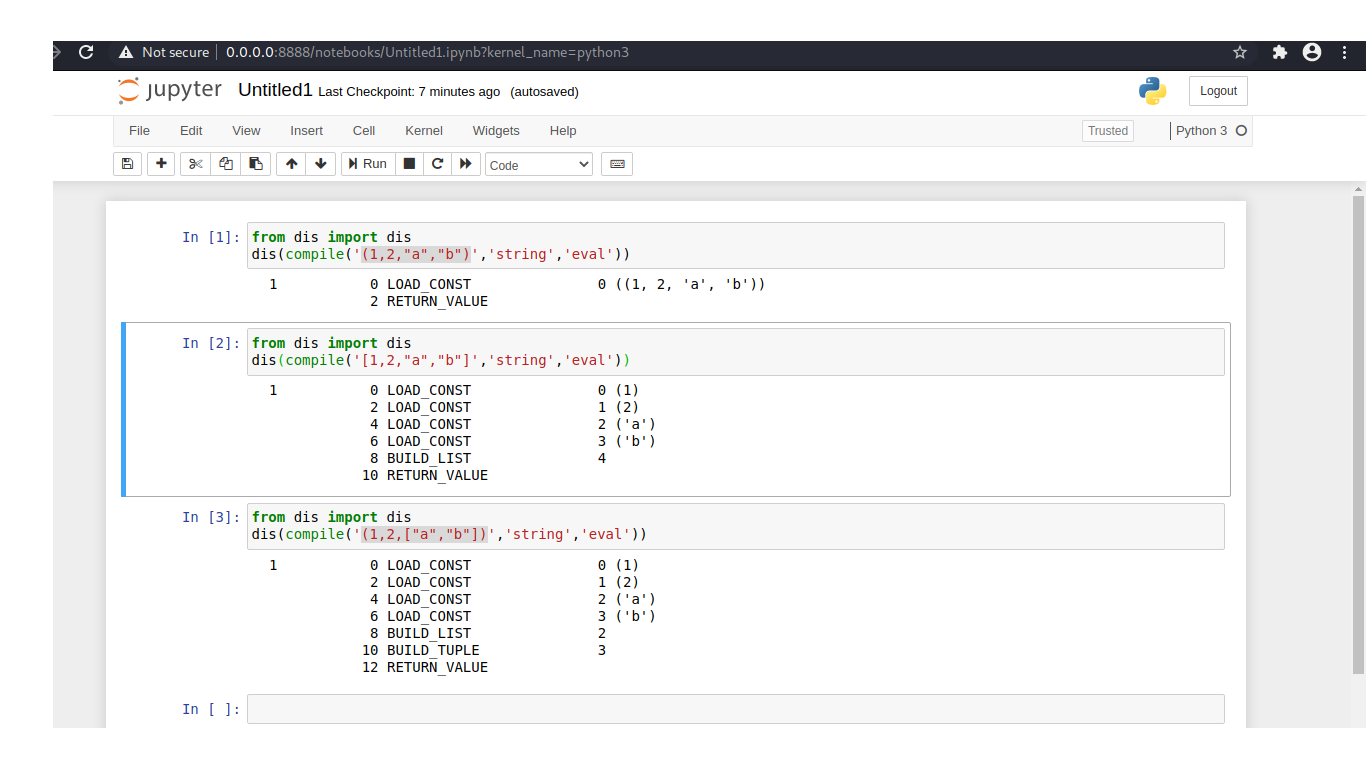
In the first example, I compiled a tuple. it loaded at the tuple as constant, it loaded and returned value. it took one step to compile. this is called constant folding. when I compiled a list with the same elements, it has to load each individual constant first, then it builds the list and returns it. in the third example, I used a tuple that includes a list. I timed each operation.
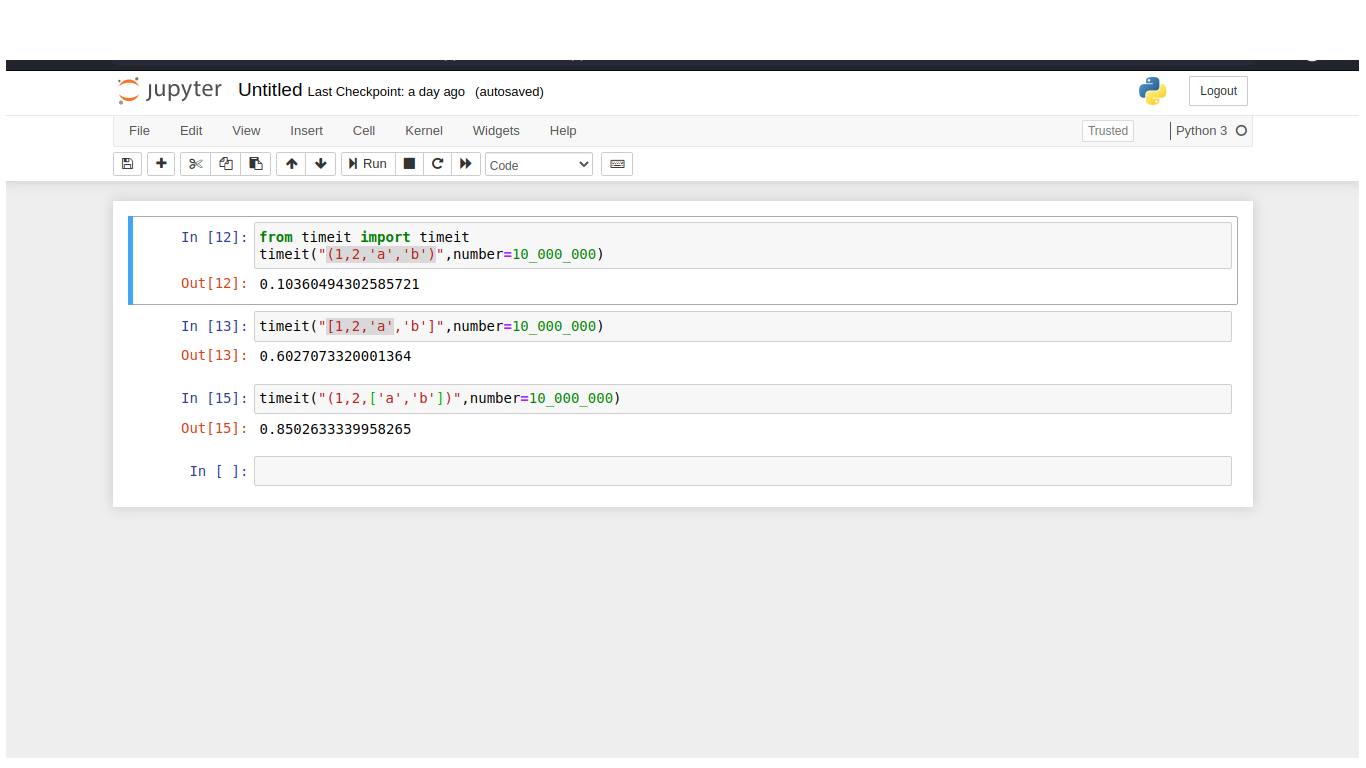
-- MEMORY ALLOCATION
When mutable container objects such as lists, sets, dictionaries, etc are created, and during their lifetime, the allocated capacity of these containers (the number of items they can contain) is greater than the number of elements in the container. This is done to make adding elements to the collection more efficient, and is called over-allocating. Thus size of the list doesn't grow every time we append an element - it only does so occasionally. Resizing a list is very expensive, so not resizing every time an item is added helps out but you don't want to overallocate too much as this has a memory cost.
Immutable containers on the other hand, since their item count is fixed once they have been created, do not need this overallocation - so their storage efficiency is greater. As tuples get larger, their size increases.
-- COPY
it does not make sense to make a shallow copy of immutable sequence because you cannot mutate it anyways. So copying tuple just returns itself, with the memory address. That is why copying tuple is faster
Retrieving elements
I timeD retrieving an element from a tuple and a list:
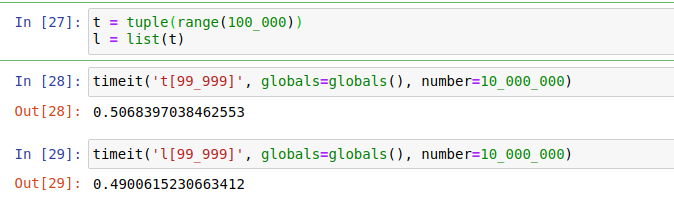
Retrieving elements from a tuple are very slightly faster than from a list. Because, in CPython, tuples have direct access (pointers) to their elements, while lists need to first access another array that contains the pointers to the elements of the list.
Could you verify your initial statement? I think you meant either: tuples performs better if all the elements, or tuples performs better but only if all the elements –
Griffen
I meant if all the elements inside tuple are immutable. for example ([1,2]) list inside tuple and list is mutable, so it wont perform better –
Euripides
Tuples should be slightly more efficient and because of that, faster, than lists because they are immutable.
Why do you say that immutability, in and of itself, increases efficiency? Especially efficiency of instantiation and retrieval? –
Travesty
It seems Mark's reply above mine has covered the disassembled instructions of what happens inside of Python. You can see that instantiation takes fewer instructions, however in this case, retrieval is apparently identical. –
Pifer
immutable tuples have quicker access than mutable lists –
Hintz
The main reason for Tuple to be very efficient in reading is because it's immutable.
Why immutable objects are easy to read?
The reason is tuples can be stored in the memory cache, unlike lists. The program always read from the lists memory location as it is mutable (can change any time).
© 2022 - 2024 — McMap. All rights reserved.