You don't mention your operating system, nor how you created the zip file, but I managed to recreate your problem anyway, using 7-Zip on Windows 10:
- Create a simple text file with some trivial content (e.g. nothing but the three characters "abc").
- Save the file as D:\Temp\Aufhänge.txt. Note the umlaut in the file name.
- Locate that file in Windows File Explorer.
- Select the file and right click. From the context menu select 7-Zip > Add to "Aufhänge.zip" to create Aufhänge.zip.
Then, in NetBeans run the following code to unzip the file you just created:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class GermanZip {
static String ZIP_PATH = "D:\\Temp\\Aufhänge.zip";
public static void main(String[] args) throws FileNotFoundException, IOException {
ZipInputStream zipInputStream = new ZipInputStream(new FileInputStream(ZIP_PATH), Charset.forName("UTF-8"));
ZipEntry zipEntry;
while ((zipEntry = zipInputStream.getNextEntry()) != null) {
System.out.println(zipEntry.getName());
}
}
}
As you pointed out, the code throws java.lang.IllegalArgumentException: MALFORMED when executing this statement: zipEntry = zipInputStream.getNextEntry()) != null.
The problem arises because by default 7-Zip encodes the names of the files within the zip file using Cp437, as noted in this comment from 7-Zip:
Default encoding is OEM (DOS) encoding. It's for compatibility with
old zip software.
That's why the unzip works when using Charset.forName("Cp437") instead of Charset.forName("UTF-8").
If you want to unzip using Charset.forName("UTF-8") then you have to force 7-Zip to encode the filenames within the zip in UTF-8. To do this specify the cu parameter when running 7-Zip, as noted in the linked comment:
- In Windows File Explorer select the file and right click.
- From the context menu select 7-Zip > Add to Archive...".
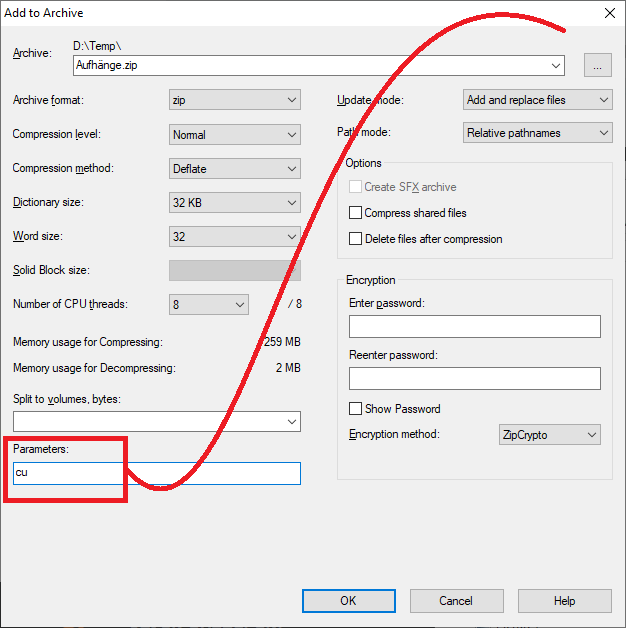
In the Add to Archive dialog specify cu in the Parameters field:
![AddToArchive]()
Having stored the zipped filenames in UTF-8 format, you can then replace Charset.forName("Cp437") with Charset.forName("UTF-8") in your code, and no exception will be thrown when unzipping.
This answer is specific to Windows 10 and 7-Zip, but the general principle should apply in any environment: if specifying an encoding of UTF-8 for your ZipInputStream be certain that the filenames within the zip file really are encoded using UTF-8. You can easily verify this by opening the zip file in a binary editor and searching for the names of the zipped files.
Update based on OP's comment/question below:
Unfortunately the .ZIP File Format Specification does not currently provide a way to store the encoding used for zipped file names apart from one exception, as described in "APPENDIX D - Language Encoding (EFS)":
D.2 If general purpose bit 11 is unset, the file name and comment
SHOULD conform to the original ZIP character encoding. If general
purpose bit 11 is set, the filename and comment MUST support The
Unicode Standard, Version 4.1.0 or greater using the character
encoding form defined by the UTF-8 storage specification. The
Unicode Standard is published by the The Unicode Consortium
(www.unicode.org). UTF-8 encoded data stored within ZIP files is
expected to not include a byte order mark (BOM).
So in your code, for each zipped file, first check whether bit 11 of the general purpose bit flag is set. If it is then you can be certain that the name of that zipped fie is encoded using UTF-8. Otherwise the encoding is whatever was used when the zipped file was created. That is Cp437 by default on Windows, but if you are running on Windows and processing a zip file created on Linux I don't think there is an easy way of determining the encoding(s) used.
- Unfortunately ZipEntry does not provide a method to access the general purpose bit flag field of a zipped file, so you would need to process the zip file at the byte level to do that.
- To add a further complication, "encoding" in this context relates to the encoding used for each zipped filename rather than for the zip file itself. One zipped file name could be encoded in UTF-8, another zipped file name could have been added using Cp437, etc.