From RFC 3986:
A URI can be further classified as a locator, a name, or both. The term "Uniform Resource Locator" (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network "location"). The term "Uniform Resource Name" (URN) has been used historically to refer to both URIs under the "urn" scheme [RFC2141], which are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name.
So all URLs are URIs, and all URNs are URIs - but URNs and URLs are different, so you can't say that all URIs are URLs.
If you haven't already read Roger Pate's answer, I'd advise doing so as well.
[ or ] and that's because the spec says "should not" and not "shall not". –
Oink java.net.URI doc itself says "every URL is a URI, abstractly speaking, but not every URI is a URL". And java.net.URL does weird stuff like checking equality of URLs by resolving host names to IP addresses (which seems at odds with RFC 3986 sec 6 in the first place, and breaks w virtual hosts). I think this just means the Java Standard Library has some inconsistent class behavior. –
Aut [ and ] bracket thing. RFC 3986 sec 3.2.2 says "[IPv6 host addresses] is the only place where square bracket characters are allowed in the URI syntax." If you use them in the right place, java.net.URI accepts them. new java.net.URI("foo://[1080:0:0:0:8:800:200C:417A]/a/b") succeeds for me in Java 1.7. "foo://example.com/a[b]" errors. This sounds in line with the RFC. The form new URI("http", "example.com", "/a/b[c]!$&'()*+", null, null) will %-encode the []. That java.net.URL accepts them elsewhere sounds like it's doing less validation. –
Aut urlparse.urlparse('http://blah.com/a[b') and urlparse.parse_qsl('a=[',True,True) should fail but does not (notice how I even passed the strict option on that last one). I blogged about this here which has some more relevant links: adamgent.com/post/25161273526/urls-are-not-a-subset-of-uris . You should also know all of the servlet containers (I have used) will happily pass you URLs with [ and ] in the path. –
Oink [, ] are called unwise hence the should not. I can't find where it says should not for unwise (maybe an older spec) but its definitely inferred. –
Oink [,]: https://mcmap.net/q/18459/-which-characters-make-a-url-invalid –
Oink URIs identify and URLs locate; however, locators are also identifiers, so every URL is also a URI, but there are URIs which are not URLs.
Examples
- Roger Pate
This is my name, which is an identifier. It is like a URI, but cannot be a URL, as it tells you nothing about my location or how to contact me. In this case it also happens to identify at least 5 other people in the USA alone.
- 4914 West Bay Street, Nassau, Bahamas
This is a locator, which is an identifier for that physical location. It is like both a URL and URI (since all URLs are URIs), and also identifies me indirectly as "resident of..". In this case it uniquely identifies me, but that would change if I get a roommate.
I say "like" because these examples do not follow the required syntax.
Popular confusion
From Wikipedia:
In computing, a Uniform Resource Locator (URL) is a subset of the Uniform Resource Identifier (URI) that specifies where an identified resource is available and the mechanism for retrieving it. In popular usage and in many technical documents and verbal discussions it is often incorrectly used as a synonym for URI, ... [emphasis mine]
Because of this common confusion, many products and documentation incorrectly use one term instead of the other, assign their own distinction, or use them synonymously.
URNs
My name, Roger Pate, could be like a URN (Uniform Resource Name), except those are much more regulated and intended to be unique across both space and time.
Because I currently share this name with other people, it's not globally unique and would not be appropriate as a URN. However, even if no other family used this name, I'm named after my paternal grandfather, so it still wouldn't be unique across time. And even if that wasn't the case, the possibility of naming my descendants after me make this unsuitable as a URN.
URNs are different from URLs in this rigid uniqueness constraint, even though they both share the syntax of URIs.
URNs are different from URLs in this rigid uniqueness constraint Does this mean that URLs don't uniquely identify a location? –
Showily https://localhost into the browser's address bar, we'll end up in different places. –
Matthew From RFC 3986:
A URI can be further classified as a locator, a name, or both. The term "Uniform Resource Locator" (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network "location"). The term "Uniform Resource Name" (URN) has been used historically to refer to both URIs under the "urn" scheme [RFC2141], which are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name.
So all URLs are URIs, and all URNs are URIs - but URNs and URLs are different, so you can't say that all URIs are URLs.
If you haven't already read Roger Pate's answer, I'd advise doing so as well.
[ or ] and that's because the spec says "should not" and not "shall not". –
Oink java.net.URI doc itself says "every URL is a URI, abstractly speaking, but not every URI is a URL". And java.net.URL does weird stuff like checking equality of URLs by resolving host names to IP addresses (which seems at odds with RFC 3986 sec 6 in the first place, and breaks w virtual hosts). I think this just means the Java Standard Library has some inconsistent class behavior. –
Aut [ and ] bracket thing. RFC 3986 sec 3.2.2 says "[IPv6 host addresses] is the only place where square bracket characters are allowed in the URI syntax." If you use them in the right place, java.net.URI accepts them. new java.net.URI("foo://[1080:0:0:0:8:800:200C:417A]/a/b") succeeds for me in Java 1.7. "foo://example.com/a[b]" errors. This sounds in line with the RFC. The form new URI("http", "example.com", "/a/b[c]!$&'()*+", null, null) will %-encode the []. That java.net.URL accepts them elsewhere sounds like it's doing less validation. –
Aut urlparse.urlparse('http://blah.com/a[b') and urlparse.parse_qsl('a=[',True,True) should fail but does not (notice how I even passed the strict option on that last one). I blogged about this here which has some more relevant links: adamgent.com/post/25161273526/urls-are-not-a-subset-of-uris . You should also know all of the servlet containers (I have used) will happily pass you URLs with [ and ] in the path. –
Oink [, ] are called unwise hence the should not. I can't find where it says should not for unwise (maybe an older spec) but its definitely inferred. –
Oink [,]: https://mcmap.net/q/18459/-which-characters-make-a-url-invalid –
Oink URI -- Uniform Resource Identifier
URIs are a standard for identifying documents using a short string of numbers, letters, and symbols. They are defined by RFC 3986 - Uniform Resource Identifier (URI): Generic Syntax. URLs, URNs, and URCs are all types of URI.
URL -- Uniform Resource Locator
Contains information about how to fetch a resource from its location. For example:
http://example.com/mypage.htmlftp://example.com/download.zipmailto:[email protected]file:///home/user/file.txttel:1-888-555-5555http://example.com/resource?foo=bar#fragment/other/link.html(A relative URL, only useful in the context of another URL)
URLs always start with a protocol (http) and usually contain information such as the network host name (example.com) and often a document path (/foo/mypage.html). URLs may have query parameters and fragment identifiers.
URN -- Uniform Resource Name
Identifies a resource by a unique and persistent name, but doesn't necessarily tell you how to locate it on the internet. It usually starts with the prefix urn: For example:
urn:isbn:0451450523to identify a book by its ISBN number.urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66a globally unique identifierurn:publishing:book- An XML namespace that identifies the document as a type of book.
URNs can identify ideas and concepts. They are not restricted to identifying documents. When a URN does represent a document, it can be translated into a URL by a "resolver". The document can then be downloaded from the URL.
URC -- Uniform Resource Citation
Points to meta data about a document rather than to the document itself. An example of a URC is one that points to the HTML source code of a page like: view-source:http://example.com/
Data URI
Rather than locating it on the internet, or naming it, data can be placed directly into a URI. An example would be data:,Hello%20World.
Frequently Asked Questions
I've heard that I shouldn't say URL anymore, why?
The W3 spec for HTML says that the href of an anchor tag can contain a URI, not just a URL. You should be able to put in a URN such as <a href="urn:isbn:0451450523">. Your browser would then resolve that URN to a URL and download the book for you.
Do any browsers actually know how to fetch documents by URN?
Not that I know of, but modern web browser do implement the data URI scheme.
Does the difference between URL and URI have anything to do with whether it is relative or absolute?
No. Both relative and absolute URLs are URLs (and URIs.)
Does the difference between URL and URI have anything to do with whether it has query parameters?
No. Both URLs with and without query parameters are URLs (and URIs.)
Does the difference between URL and URI have anything to do with whether it has a fragment identifier?
No. Both URLs with and without fragment identifiers are URLs (and URIs.)
Does the difference between URL and URI have anything to do with what characters are permitted?
No. URLs are defined to be a strict subset of URIs. If a parser allows a character in a URL but not in a URI, there is a bug in the parser. The specs go into great detail about which characters are allowed in which parts of URLs and URIs. Some characters may be allowed only in some parts of the URL, but characters alone are not a difference between URLs and URIs.
But doesn't the W3C now say that URLs and URIs are the same thing?
Yes. The W3C realized that there is a ton of confusion about this. They issued a URI clarification document that says that it is now OK to use the terms URL and URI interchangeably (to mean URI). It is no longer useful to strictly segment URIs into different types such as URL, URN, and URC.
Can a URI be both a URL and a URN?
The definition of URN is now looser than what I stated above. The latest RFC on URIs says that any URI can now be a URN (regardless of whether it starts with urn:) as long as it has "the properties of a name." That is: It is globally unique and persistent even when the resource ceases to exist or becomes unavailable. An example: The URIs used in HTML doctypes such as http://www.w3.org/TR/html4/strict.dtd. That URI would continue to name the HTML4 transitional doctype even if the page on the w3.org website were deleted.

file:// prefix on it. Although browsers do generally handle non-URL formatted file paths. Mozilla publishes their test cases for file URLs. –
Visby In summary: a URI identifies, a URL identifies and locates.
Consider a specific edition of Shakespeare's play Romeo and Juliet, of which you have a digital copy on your home network.
You could identify the text as urn:isbn:0-486-27557-4.
That would be a URI, but more specifically a URN* because it names the text.
You could also identify the text as file://hostname/sharename/RomeoAndJuliet.pdf.
That would also be a URI, but more specifically a URL because it locates the text.
*Uniform Resource Name
(Note that my example is adapted from Wikipedia)
ISBN 0486275574 also names the text and thus qualify as a URN. I choose a format that I believed would be more familiar to readers. –
Sputter These are some very well-written but long-winded answers. Here is the difference as far as CodeIgniter is concerned:
URL - http://example.com/some/page.html
URI - /some/page.html
Put simply, URL is the full way to indentify any resource anywhere and can have different protocols like FTP, HTTP, SCP, etc.
URI is a resource on the current domain, so it needs less information to be found.
In every instance that CodeIgniter uses the word URL or URI this is the difference they are talking about, though in the grand-scheme of the web, it is not 100% correct.
/some/page.html is not a URI. It is a "relative-ref", which is a kind of "URI-reference". Combined with a base URI context, it can be resolved to a URI, but is not itself a URI. See Section 4.1 of RFC 3986. CodeIgniter's probably using the terms wrong and that should be called out; the Q (as currently edited) isn't framed as CodeIgniter-specific. –
Aut $_SERVER['REQUEST_URI'] distinguishes like this. –
Mcclellan /some/page.html is not an URI then it is definitely not an URL - it's not complete enough for me to locate the resource. –
Complexity First of all get your mind out of confusion and take it simple and you will understand.
URI => Uniform Resource Identifier Identifies a complete address of resource i-e location, name or both.
URL => Uniform Resource Locator Identifies location of the resource.
URN => Uniform Resource Name Identifies the name of the resource
Example
We have address https://www.google.com/folder/page.html where,
URI(Uniform Resource Identifier) => https://www.google.com/folder/page.html
URL(Uniform Resource Locator) => https://www.google.com/
URN(Uniform Resource Name) => /folder/page.html
URI => (URL + URN) or URL only or URN only
Identity = Name with Location
Every URL(Uniform Resource Locator) is a URI(Uniform Resource Identifier), abstractly speaking, but every URI is not a URL. There is another subcategory of URI is URN (Uniform Resource Name), which is a named resource but do not specify how to locate them, like mailto, news, ISBN is URIs. Source
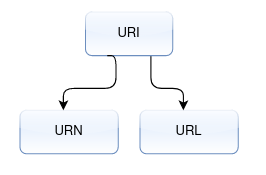
URN:
- URN Format :
urn:[namespace identifier]:[namespace specific string] - urn: and : stand for themselves.
- Examples:
- urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66
- urn:ISSN:0167-6423
- urn:isbn:096139210x
- Amazon Resource Names (ARNs) is a uniquely identify AWS resources.
- ARN Format :
arn:partition:service:region:account-id:resource
- ARN Format :
URL:
- URL Format :
[scheme]://[Domain][Port]/[path]?[queryString]#[fragmentId] - :,//,? and # stand for themselves.
- schemes are https,ftp,gopher,mailto,news,telnet,file,man,info,whatis,ldap...
- Examples:
- http://ip_server/path?query
- ftp://ip_server/path
- mailto:email-address
- news:newsgroup-name
- telnet://ip_server/
- file://ip_server/path_segments
- ldap://hostport/dn?attributes?scope?filter?extensions
Analogy:
To reach a person: Driving(protocol others SMS, email, phone), Address(hostname other phone-number, emailid) and person name(object name with a relative path).
mailto URL ? –
Tenderize A small addition to the answers already posted, here's a Venn's diagram to sum up the theory (from Prateek Joshi's beautiful explanation):

And an example (also from Prateek's website):

#posts fragment identifier could be part of the URL –
Atonement This is one of the most confusing and possibly irrelevant topics I've encountered as a web professional.
As I understand it, a URI is a description of something, following an accepted format, that can define both or either the unique name (identification) of something or its location.
There are two basic subsets:
- URLs, which define location (especially to a browser trying to look up a webpage) and
- URNs, which define the unique name of something.
I tend to think of URNs as being similar to GUIDs. They are simply a standardized methodology for providing unique names for things. As in the namespace declarative that uses a company's name—it's not like there is a resource sitting on a server somewhere to correspond to that line of text—it simply uniquely identifies something.
I also tend to completely avoid the term URI and discuss things only in terms of URL or URN as appropriate, because it causes so much confusion. The question we should really try answering for people isn't so much the semantics, but how to identify when encountering the terms whether or not there is any practical difference in them that will change the approach to a programming situation. For example, if someone corrects me in conversation and says, "oh, that's not a URL it's a URI" I know they're full of it. If someone says, "we're using a URN to define the resource," I'm more likely to understand we are only naming it uniquely, not locating it on a server.
If I'm way off base, please let me know!
redirect_url instead of redirect_uri, would anyone really care? –
Tearle URI => http://en.wikipedia.org/wiki/Uniform_Resource_Identifier
URL's are a subset of URI's (which also contain URNs).
Basically, a URI is a general identifier, where a URL specifies a location and a URN specifies a name.
[ and ] but not a URI. –
Oink Another example I like to use when thinking about URIs is the xmlns attribute of an XML document:
<rootElement xmlns:myPrefix="com.mycompany.mynode">
<myPrefix:aNode>some text</myPrefix:aNode>
</rootElement>
In this case com.mycompany.mynode would be a URI that uniquely identifies the "myPrefix" namespace for all of the elements that use it within my XML document. This is NOT a URL because it is only used to identify, not to locate something per se.
They're the same thing. A URI is a generalization of a URL. Originally, URIs were planned to be divided into URLs (addresses) and URNs (names) but then there was little difference between a URL and URI and http URIs were used as namespaces even though they didn't actually locate any resources.
Due to difficulties to clearly distinguish between URI and URL, as far as I remember W3C does not make a difference any longer between URI and URL (http://www.w3.org/Addressing/).

URI, URL, URN
As the image above indicates, there are three distinct components at play here. It’s usually best to go to the source when discussing matters like these, so here’s an exerpt from Tim Berners-Lee, et. al. in RFC 3986: Uniform Resource Identifier (URI): Generic Syntax:
A Uniform Resource Identifier (URI) is a compact sequence of characters that identifies an abstract or physical resource.
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”).
URI is kind of the super class of URL's and URN's. Wikipedia has a fine article about them with links to the right set of RFCs.
Wikipedia will give all the information you need here. Quoting from http://en.wikipedia.org/wiki/URI:
A URL is a URI that, in addition to identifying a resource, provides means of acting upon or obtaining a representation of the resource by describing its primary access mechanism or network "location".
URL
A URL is a specialization of URI that defines the network location of a specific resource. Unlike a URN, the URL defines how the resource can be obtained. We use URLs every day in the form of http://example.com etc. But a URL doesn't have to be an HTTP URL, it can be ftp://example.com etc., too.
URI
A URI identifies a resource either by location, or a name, or both. More often than not, most of us use URIs that defines a location to a resource. The fact that a URI can identify a resources by both name and location has lead to a lot of the confusion in my opinion. A URI has two specializations known as URL and URN.
Difference between URL and URI
A URI is an identifier for some resource, but a URL gives you specific information as to obtain that resource. A URI is a URL and as one commenter pointed out, it is now considered incorrect to use URL when describing applications. Generally, if the URL describes both the location and name of a resource, the term to use is URI. Since this is generally the case most of us encounter everyday, URI is the correct term.
A URI identifies a resource either by location, or a name, or both. More often than not, most of us use URIs that defines a location to a resource. The fact that a URI can identify a resources by both name and location has lead to a lot of the confusion in my opinion. A URI has two specializations known as URL and URN.
A URL is a specialization of URI that defines the network location of a specific resource. Unlike a URN, the URL defines how the resource can be obtained. We use URLs every day in the form of http://stackoverflow.com, etc. But a URL doesn’t have to be an HTTP URL, it can be ftp://example.com, etc.
As per RFC 3986, URIs are comprised of the following pieces:
scheme://authority/path?query
The URI describes the protocol for accessing a resource (path) or application (query) on a server (authority).

All the URLs are URIs, and all the URNs are URIs, but all the URIs are not URLs.
Please refer for more details:
Although the terms URI and URL are strictly defined, many use the terms for other things than they are defined for.
Let’s take Apache for example. If http://example.com/foo is requested from an Apache server, you’ll have the following environment variables set:
REDIRECT_URL:/fooREQUEST_URI:/foo
With mod_rewrite enabled, you will also have these variables:
REDIRECT_SCRIPT_URL:/fooREDIRECT_SCRIPT_URI:http://example.com/fooSCRIPT_URL:/fooSCRIPT_URI:http://example.com/foo
This might be the reason for some of the confusion.
See this document. Specifically,
a URL is a type of URI that identifies a resource via a representation of its primary access mechanism (e.g., its network "location"), rather than by some other attributes it may have.
It's not an extremely clear term, really.
After reading through the posts, I find some very relevant comments. In short, the confusion between the URL and URI definitions is based in part on which definition depends on which and also informal use of the word URI in software development.
By definition URL is a subset of URI [RFC2396]. URI contain URN and URL. Both URI and URL each have their own specific syntax that confers upon them the status of being either URI or URL. URN are for uniquely identifying a resource while URL are for locating a resource. Note that a resource can have more than one URL but only a single URN.[RFC2611]
As web developers and programmers we will almost always be concerned with URL and therefore URI. Now a URL is specifically defined to have all the parts scheme:scheme-specific-part, like for example https://stackoverflow.com/questions. This is a URL and it is also a URI. Now consider a relative link embedded in the page such as ../index.html. This is no longer a URL by definition. It is still what is referred to as a "URI-reference" [RFC2396].
I believe that when the word URI is used to refer to relative paths, "URI-reference" is actually what is being thought of. So informally, software systems use URI to refer to relative pathing and URL for the absolute address. So in this sense, a relative path is no longer a URL but still URI.
URIs came about from the need to identify resources on the Web, and other Internet resources such as electronic mailboxes in a uniform and coherent way. So, one can introduce a new type of widget: URIs to identify widget resources or use tel: URIs to have web links cause telephone calls to be made when invoked.
Some URIs provide information to locate a resource (such as a DNS host name and a path on that machine), while some are used as pure resource names. The URL is reserved for identifiers that are resource locators, including 'http' URLs such as http://stackoverflow.com, which identifies the web page at the given path on the host. Another example is 'mailto' URLs, such as mailto:[email protected], which identifies the mailbox at the given address.
URNs are URIs that are used as pure resource names rather than locators. For example, the URI: mid:[email protected] is a URN that identifies the email message containing it in its 'Message-Id' field. The URI serves to distinguish that message from any other email message. But it does not itself provide the message's address in any store.
Here is my simplification:
URN: unique resource name, i.e. "what" (eg urn:issn:1234-5678 ). This is meant to be unique .. as in no two different docs can have the same urn. A bit like "uuid"
URL: "where" to find it ( eg https://google.com/pub?issnid=1234-5678 .. or ftp://somesite.com/doc8.pdf )
URI: can be either a URN or a URL. This fuzzy definition is thanks to RFC 3986 produced by W3C and IETF.
The definition of URI has changed over the years, so it makes sense for most people to be confused. However, you can now take solace in the fact that you can refer to http://somesite.com/something as either a URL or URI ... an you will be right either way (at least fot the time being anyway...)
In order to answer this I'll lean on an answer I modified to another question. A good example of a URI is how you identify an Amazon S3 resource. Let's take:
s3://www-example-com/index.html [fig. 1]
which I created as a cached copy of
http://www.example.com/index.html [fig. 2]
in Amazon's S3-US-West-2 datacenter.
Even if StackOverflow would allow me to hyperlink to the s3:// protocol scheme, it wouldn't do you any good in locating the resource. Because it Identifies a Resource, fig. 1 is a valid URI. It is also a valid URN, because Amazon requires that the bucket (their term for the authority portion of the URI) be unique across datacenters. It is helpful in locating it, but it does not indicate the datacenter. Therefore it does not work as a URL.
So, how do URI, URL, and URN differ in this case?
- fig. 1 is a URI
- fig. 1 is a URN
- fig. 2 is a URI
- fig. 2 is a URL
- The URL for fig. 1 is http://www-example-com.s3-website-us-west-2.amazonaws.com/
- also http://www-example-com.s3.amazonaws.com/index.html
- but not http://www-example-com.s3.amazonaws.com/ (no datacenter and no filename is too generic for Amazon S3)
NOTE: RFC 3986 defines URIs as scheme://authority/path?query#fragment
The best (technical) summary imo is this one
IRI, URI, URL, URN and their differences from Jan Martin Keil:
IRI, URI, URL, URN and their differences
Everybody dealing with the Semantic Web repeatedly comes across the terms IRI, URI, URL and URN. Nevertheless, I frequently observe that there is some confusion about their exact meaning. And, of course, others noticed that as well (see e.g. RFC3305 or search on Google). To be honest, I even was confused myself at the outset. But actually the issue is not that complex. Let’s have a look on the definitions of the mentioned terms to see what the differences are:
URI
A Uniform Resource Identifier is a compact sequence of characters that identifies an abstract or physical resource. The set of characters is limited to US-ASCII excluding some reserved characters. Characters outside the set of allowed characters can be represented using Percent-Encoding. A URI can be used as a locator, a name, or both. If a URI is a locator, it describes a resource’s primary access mechanism. If a URI is a name, it identifies a resource by giving it a unique name. The exact specifications of syntax and semantics of a URI depend on the used Scheme that is defined by the characters before the first colon. [RFC3986]
URN
A Uniform Resource Name is a URI in the scheme urn intended to serve as persistent, location-independent, resource identifier. Historically, the term also referred to any URI. [RFC3986] A URN consists of a Namespace Identifier (NID) and a Namespace Specific String (NSS): urn:: The syntax and semantics of the NSS is specific specific for each NID. Beside the registered NIDs, there exist several more NIDs, that did not go through the official registration process. [RFC2141]
URL
A Uniform Resource Locator is a URI that, in addition to identifying a resource, provides a means of locating the resource by describing its primary access mechanism [RFC3986]. As there is no exact definition of URL by means of a set of Schemes, "URL is a useful but informal concept", usually referring to a subset of URIs that do not contain URNs [RFC3305].
IRI
An Internationalized Resource Identifier is defined similarly to a URI, but the character set is extended to the Universal Coded Character Set. Therefore, it can contain any Latin and non Latin characters except the reserved characters. Instead of extending the definition of URI, the term IRI was introduced to allow for a clear distinction and avoid incompatibilities. IRIs are meant to replace URIs in identifying resources in situations where the Universal Coded Character Set is supported. By definition, every URI is an IRI. Furthermore, there is a defined surjective mapping of IRIs to URIs: Every IRI can be mapped to exactly one URI, but different IRIs might map to the same URI. Therefore, the conversion back from a URI to an IRI may not produce the original IRI. [RFC3987]
Summarizing we can say:
IRI is a superset of URI (IRI ⊃ URI)
URI is a superset of URL (URI ⊃ URL)
URI is a superset of URN (URI ⊃ URN)
URL and URN are disjoint (URL ∩ URN = ∅)
Conclusions for Semantic Web Issues
RDF explicitly allows to use IRIs to name entities [RFC3987]. This means that we can use almost every character in entity names. On the other hand, we often have to deal with early state software. Thus, it is not unlikely to run into problems using non ASCII characters. Therefore, I suggest to avoid non URI names for entities and recommend to use http URIs [LINKED-DATA]. To put it briefly: only use URLs to name your entities. Of course, we can refer to existing entities named by a URN. However, we should avoid to newly create this kind of identifiers.
httsp://www.google.com/lala/example?something=1. –
Applaud I was wondering about the same thing and I've found this: http://docs.kohanaphp.com/helpers/url.
You can see a clear example using the url::current() method.
If you have this URL: http://example.com/kohana/index.php/welcome/home.html?query=string then using url:current() gives you the URI which, according to the documentation, is: welcome/home
Easy to explain:
Lets assume the following
URI is your Name
URL is your address with your name in-order to communicate with you.
my name is Loyola
Loyola is URI
my address is TN, Chennai 600001.
TN, Chennai 600 001, Loyola is URL
Hope you understand,
Now lets see a precise example
http://www.google.com/fistpage.html
in the above you can communicate with a page called firstpage.html (URI) using following http://www.google.com/fistpage.html(URL).
Hence URI is subset of URL but not vice-versa.
I found:
A uniform resource identifier(URI) represents something of a big picture. You can split URIs/ URIs can be classified as locators (uniform resource locators- URL), or as names (uniform resource name-URN), or either both. So basically, a URN functions like a person's name and the URL depicts that person's address. So long story short, a URN defines an item's identity, while the URL provides defines the method for finding it, finally encapsulating these two concepts is the URI
The answer is ambiguous. In Java it is frequently used in this way:
An Uniform Resource Locator (URL) is the term used to identify an Internet resource including the scheme( http, https, ftp, news, etc.). For instance What is the difference between a URI, a URL and a URN?
An Uniform Resource Identifier (URI) is used to identify a single document in the Web Server: For instance /questions/176264/whats-the-difference-between-a-uri-and-a-url
In Java servlets, the URI frequently refers to the document without the web application context.
Everybody seems to have their own answer to this question. Me trying to give proper naming to arguments used in API sessions... ty so much for the confusion all.
My source of truth is gonna be the browser Location API. screw URL, URN and URI.
- location.origin:
https://www.somedomain.com - location.pathname:
/path/to/the/endpoint
Don't forget URNs. URIs and URLs are both URNs. URLs have a location:
URI: foo
URL: http://some.domain.com/foo
URL: http://some.domain.com:8080/foo
URL: ftp://some.domain.com/foo
They're all URNs.
© 2022 - 2025 — McMap. All rights reserved.
URLto be what a user would use to navigate to a location (whether manually typed or copied/pasted) whereas aURIis the server-side interpretation of the originalURL. But apparently, there's a lot more to it, as described in the numerous answers. – Leolaleoline( URIs ( URLs ) )– Coverley