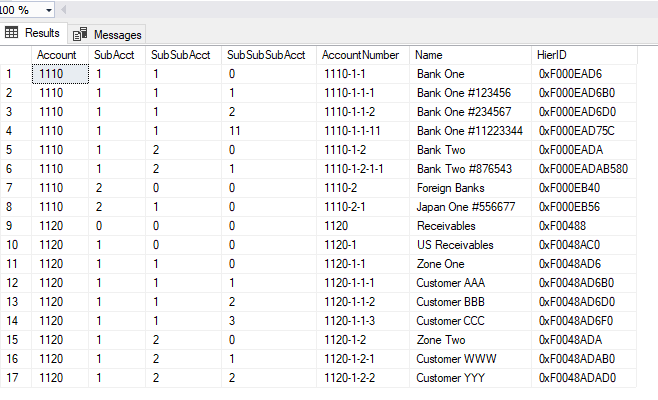
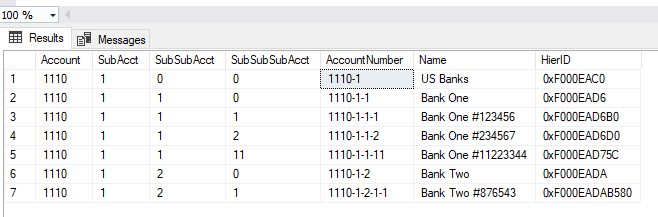
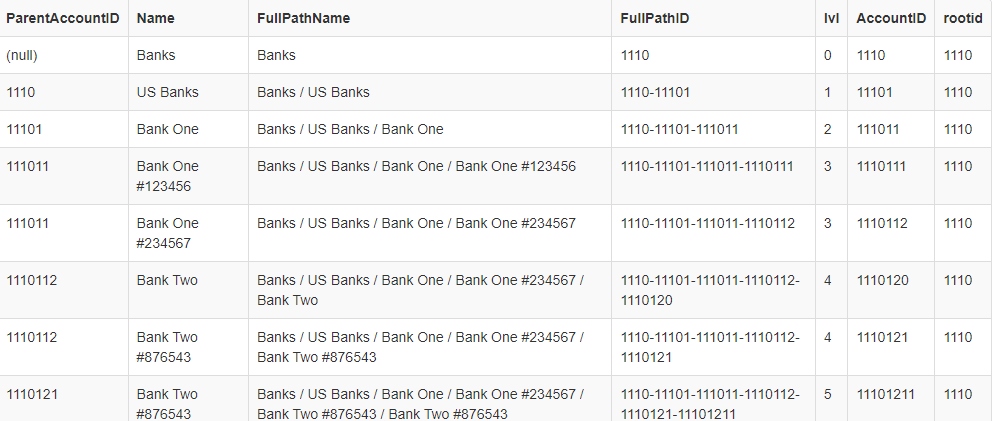
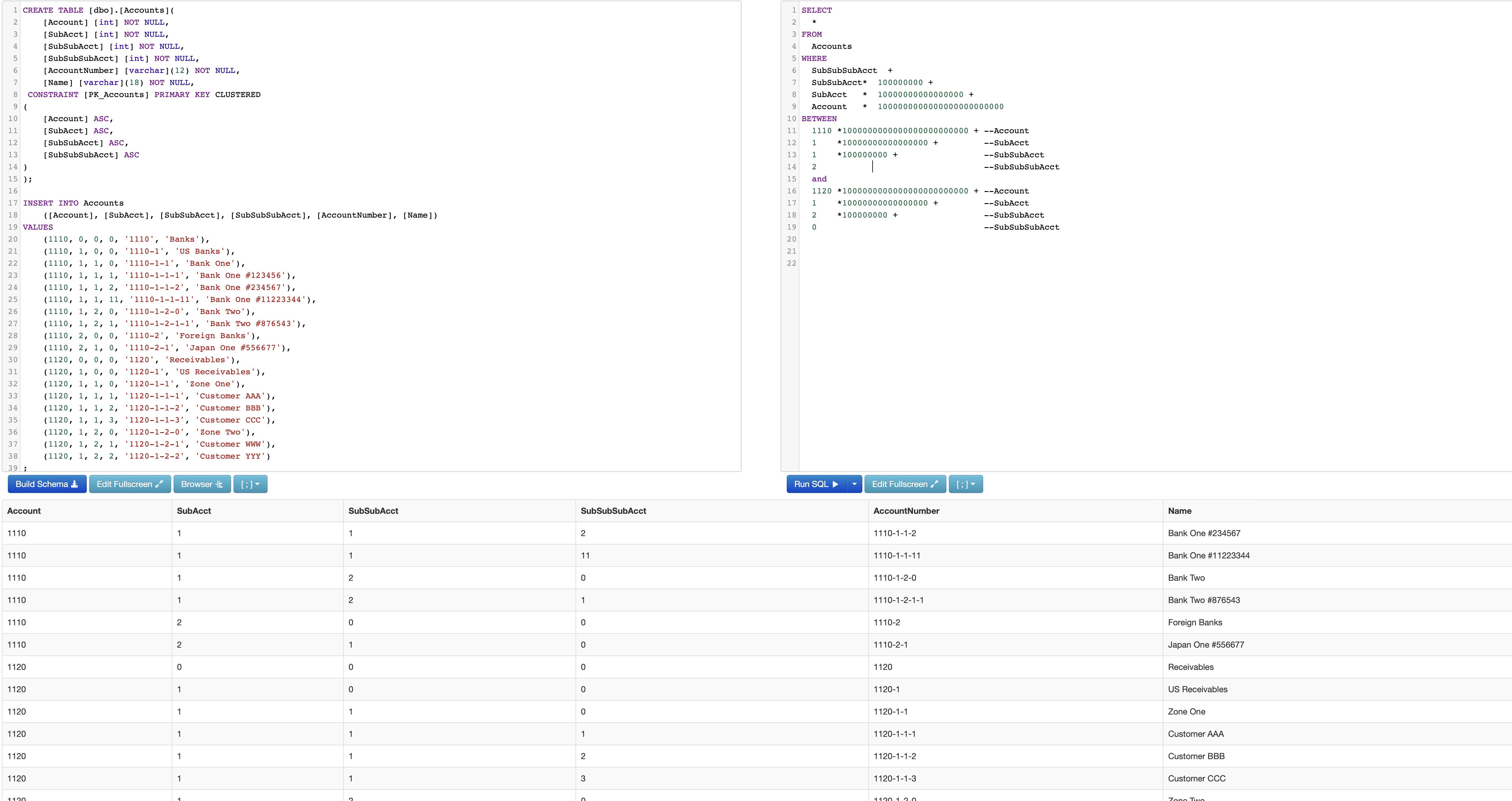
The key requirement: "I need to query any range of accounts" regardless of whether or not either "account number" in the range endpoint(s) actually exists. The first piece of code needed is a function to reliably parse the components of the endpoints of the range. In this case the function relies on an ordinal splitter called dbo.DelimitedSplit8K_LEAD (explained here)
DelimitedSplit8K_LEAD
CREATE FUNCTION [dbo].[DelimitedSplit8K_LEAD]
--===== Define I/O parameters
(@pString VARCHAR(8000), @pDelimiter CHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), --10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS (--==== This provides the "zero base" and limits the number of rows right up front
-- for both a performance gain and prevention of accidental "overruns"
SELECT 0 UNION ALL
SELECT TOP (DATALENGTH(ISNULL(@pString,1))) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (--==== This returns N+1 (starting position of each "element" just once for each delimiter)
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@pString,t.N,1) = @pDelimiter OR t.N = 0)
)
--===== Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found.
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY s.N1),
Item = SUBSTRING(@pString,s.N1,ISNULL(NULLIF((LEAD(s.N1,1,1) OVER (ORDER BY s.N1) - 1),0)-s.N1,8000))
FROM cteStart s
;
Function to split endpoint "account number"
create function dbo.test_fnAccountParts(
@acct varchar(12))
returns table with schemabinding as return
select max(case when dl.ItemNumber=1 then Item else 0 end) a,
max(case when dl.ItemNumber=2 then Item else 0 end) sa,
max(case when dl.ItemNumber=3 then Item else 0 end) ssa,
max(case when dl.ItemNumber=4 then Item else 0 end) sssa
from dbo.DelimitedSplit8K_LEAD(@acct,'-') dl;
Query to locate rows based on sequence number
declare
@acct1 varchar(12)='1110-1-1-2',
@acct2 varchar(12)='1120-1-2';
with
rn_cte as (
select a.*, row_number() over (order by Account, SubAcct, SubSubAcct, SubSubSubAcct) rn
from #accounts a),
rn1_cte as (select max(rn) max_rn
from rn_cte r
cross apply dbo.test_fnAccountParts(@acct1) ap
where r.Account<=ap.a
and r.SubAcct<=ap.sa
and r.SubSubAcct<=ap.ssa
and r.SubSubSubAcct<=ap.sssa),
rn2_cte as (select max(rn) max_rn
from rn_cte r
cross apply dbo.test_fnAccountParts(@acct2) ap
where r.Account<=ap.a
and r.SubAcct<=ap.sa
and r.SubSubAcct<=ap.ssa
and r.SubSubSubAcct<=ap.sssa)
select rn.*
from rn_cte rn
cross join rn1_cte r1
cross join rn2_cte r2
where rn.rn between r1.max_rn
and r2.max_rn;
Account SubAcct SubSubAcct SubSubSubAcct AccountNumber Name rn
1110 1 1 2 1110-1-1-2 Bank One #234567 5
1110 1 1 11 1110-1-1-11 Bank One #11223344 6
1110 1 2 0 1110-1-2-0 Bank Two 7
1110 1 2 1 1110-1-2-1-1 Bank Two #876543 8
1110 2 0 0 1110-2 Foreign Banks 9
1110 2 1 0 1110-2-1 Japan One #556677 10
1120 0 0 0 1120 Receivables 11
1120 1 0 0 1120-1 US Receivables 12
1120 1 1 0 1120-1-1 Zone One 13
1120 1 1 1 1120-1-1-1 Customer AAA 14
1120 1 1 2 1120-1-1-2 Customer BBB 15
1120 1 1 3 1120-1-1-3 Customer CCC 16
1120 1 2 0 1120-1-2-0 Zone Two 17
Suppose you were to add an indexed computed column (as suggested in Marcus Vinicius Pompeu's answer) called AccountNumberNormalized. It's a good suggestion. Then you would need a function to return the normalized account number of the end points. Something like this
drop function if exists dbo.test_fnAccountNumberNormalized;
go
create function dbo.test_fnAccountNumberNormalized(
@acct varchar(12))
returns table with schemabinding as return
select concat_ws('-', RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=1 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=2 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=3 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=4 then Item else 0 end)) ), 8))
AccountNumberNormalized
from dbo.DelimitedSplit8K_LEAD(@acct,'-') dl;
Then this query returns the same results (13 rows) as above
declare
@acct1 varchar(12)='1110-1-1-2',
@acct2 varchar(12)='1120-1-2';
SELECT a.*
FROM #Accounts a
cross apply dbo.test_fnAccountNumberNormalized(@acct1) fn1
cross apply dbo.test_fnAccountNumberNormalized(@acct2) fn2
WHERE
a.AccountNumberNormalized
BETWEEN fn1.AccountNumberNormalized
AND fn2.AccountNumberNormalized
ORDER BY Account,SubAcct,SubSubAcct,SubSubSubAcct;
These are inline table valued functions. If you're using SQL 2019 (or compatability level 150) you maybe could change these into inline scalar functions.
[Edit] Here's a scalar function which returns CHAR(35). It definitely cleans up the code. Performance wise it would depend on specific circumstance and would need to be tested. This query returns the same results (13 rows) as above.
create function dbo.test_scalar_fnAccountNumberNormalized(
@acct varchar(12))
returns char(35) as
begin
return (
select concat_ws('-', RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=1 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=2 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=3 then Item else 0 end)) ), 8),
RIGHT('00000000' + CONVERT(VARCHAR, (max(case when dl.ItemNumber=4 then Item else 0 end)) ), 8))
AccountNumberNormalized
from dbo.DelimitedSplit8K_LEAD(@acct,'-') dl);
end
declare
@acct1 varchar(12)='1110-1-1-2',
@acct2 varchar(12)='1120-1-2';
SELECT a.*
FROM #Accounts a
WHERE
a.AccountNumberNormalized
BETWEEN dbo.test_scalar_fnAccountNumberNormalized(@acct1)
AND dbo.test_scalar_fnAccountNumberNormalized(@acct2)
ORDER BY Account,SubAcct,SubSubAcct,SubSubSubAcct;