*Note: while this post is pretty much asking about bilinear interpolation I kept the title more general and included extra information in case someone has any ideas on how I can possibly do this better
I have been having trouble implementing a way to identify letters from an image in order to create a word search solving program. For mainly educational but also portability purposes, I have been attempting this without the use of a library. It can be assumed that the image the characters will be picked off of contains nothing else but the puzzle. Although this page is only recognizing a small set of characters, I have been using it to guide my efforts along with this one as well. As the article suggested I have an image of each letter scaled down to 5x5 to compare each unknown letter to. I have had the best success by scaling down the unknown to 5x5 using bilinear resampling and summing the squares of the difference in intensity of each corresponding pixel in the known and unknown images. To attempt to get more accurate results I also added the square of the difference in width:height ratios, and white:black pixel ratios of the top half and bottom half of each image. The known image with the closest "difference score" to the unknown image is then considered the unknown letter. The problem is that this seems to have only about a 50% accuracy. To improve this I have tried using larger samples (instead of 5x5 I tried 15x15) but this proved even less effective. I also tried to go through the known and unknown images and look for features and shapes, and determine a match based on two images having about the same amount of the same features. For example shapes like the following were identified and counted up (Where ■ represents a black pixel). This proved less effective as the original method.
■ ■ ■ ■
■ ■
So here is an example: the following image gets loaded:

The program then converts it to monochrome by determining if each pixel has an intensity above or below the average intensity of an 11x11 square using a summed area table, fixes the skew and picks out the letters by identifying an area of relatively equal spacing. I then use the intersecting horizontal and vertical spaces to get a general idea of where each character is. Next I make sure that the entire letter is contained in each square picked out by going line by line, above, below, left and right of the original square until the square's border detects no dark pixels on it.

Then I take each letter, resample it and compare it to the known images.
*Note: the known samples are using arial font size 12, rescaled in photoshop to 5x5 using bilinear interpolation.
Here is an example of a successful match: The following letter is picked out:

scaled down to:
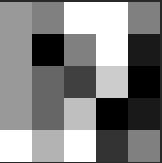
which looks like

from afar. This is successfully matched to the known N sample:

Here is a failed match:

is picked out and scaled down to:

which, to no real surprise does not match to the known R sample

I changed how images are picked out, so that the letter is not cut off as you can see in the above images so I believe the issue comes from scaling the images down. Currently I am using bilinear interpolation to resample the image. To understand how exactly this works with downsampling I referred to the second answer in this post and came up with the following code. Previously I have tested that this code works (at least to a "this looks ok" point) so it could be a combination of factors causing problems.
void Image::scaleTo(int width, int height)
{
int originalWidth = this->width;
int originalHeight = this->height;
Image * originalData = new Image(this->width, this->height, 0, 0);
for (int i = 0; i < this->width * this->height; i++) {
int x = i % this->width;
int y = i / this->width;
originalData->setPixel(x, y, this->getPixel(x, y));
}
this->resize(width, height); //simply resizes the image, after the resize it is just a black bmp.
double factorX = (double)originalWidth / width;
double factorY = (double)originalHeight / height;
float * xCenters = new float[originalWidth]; //the following stores the "centers" of each pixel.
float * yCenters = new float[originalHeight];
float * newXCenters = new float[width];
float * newYCenters = new float[height];
//1 represents one of the originally sized pixel's side length
for (int i = 0; i < originalWidth; i++)
xCenters[i] = i + 0.5;
for (int i = 0; i < width; i++)
newXCenters[i] = (factorX * i) + (factorX / 2.0);
for (int i = 0; i < height; i++)
newYCenters[i] = (factorY * i) + (factorY / 2.0);
for (int i = 0; i < originalHeight; i++)
yCenters[i] = i + 0.5;
/* p[0] p[1]
p
p[2] p[3] */
//the following will find the closest points to the sampled pixel that still remain in this order
for (int x = 0; x < width; x++) {
for (int y = 0; y < height; y++) {
POINT p[4]; //POINT used is the Win32 struct POINT
float pDists[4] = { FLT_MAX, FLT_MAX, FLT_MAX, FLT_MAX };
float xDists[4];
float yDists[4];
for (int i = 0; i < originalWidth; i++) {
for (int j = 0; j < originalHeight; j++) {
float xDist = abs(xCenters[i] - newXCenters[x]);
float yDist = abs(yCenters[j] - newYCenters[y]);
float dist = sqrt(xDist * xDist + yDist * yDist);
if (xCenters[i] < newXCenters[x] && yCenters[j] < newYCenters[y] && dist < pDists[0]) {
p[0] = { i, j };
pDists[0] = dist;
xDists[0] = xDist;
yDists[0] = yDist;
}
else if (xCenters[i] > newXCenters[x] && yCenters[j] < newYCenters[y] && dist < pDists[1]) {
p[1] = { i, j };
pDists[1] = dist;
xDists[1] = xDist;
yDists[1] = yDist;
}
else if (xCenters[i] < newXCenters[x] && yCenters[j] > newYCenters[y] && dist < pDists[2]) {
p[2] = { i, j };
pDists[2] = dist;
xDists[2] = xDist;
yDists[2] = yDist;
}
else if (xCenters[i] > newXCenters[x] && yCenters[j] > newYCenters[y] && dist < pDists[3]) {
p[3] = { i, j };
pDists[3] = dist;
xDists[3] = xDist;
yDists[3] = yDist;
}
}
}
//channel is a typedef for unsigned char
//getOPixel(point) is a macro for originalData->getPixel(point.x, point.y)
float r1 = (xDists[3] / (xDists[2] + xDists[3])) * getOPixel(p[2]).r + (xDists[2] / (xDists[2] + xDists[3])) * getOPixel(p[3]).r;
float r2 = (xDists[1] / (xDists[0] + xDists[1])) * getOPixel(p[0]).r + (xDists[0] / (xDists[0] + xDists[1])) * getOPixel(p[1]).r;
float interpolated = (yDists[0] / (yDists[0] + yDists[3])) * r1 + (yDists[3] / (yDists[0] + yDists[3])) * r2;
channel r = (channel)round(interpolated);
r1 = (xDists[3] / (xDists[2] + xDists[3])) * getOPixel(p[2]).g + (xDists[2] / (xDists[2] + xDists[3])) * getOPixel(p[3]).g; //yDist[3]
r2 = (xDists[1] / (xDists[0] + xDists[1])) * getOPixel(p[0]).g + (xDists[0] / (xDists[0] + xDists[1])) * getOPixel(p[1]).g; //yDist[0]
interpolated = (yDists[0] / (yDists[0] + yDists[3])) * r1 + (yDists[3] / (yDists[0] + yDists[3])) * r2;
channel g = (channel)round(interpolated);
r1 = (xDists[3] / (xDists[2] + xDists[3])) * getOPixel(p[2]).b + (xDists[2] / (xDists[2] + xDists[3])) * getOPixel(p[3]).b; //yDist[3]
r2 = (xDists[1] / (xDists[0] + xDists[1])) * getOPixel(p[0]).b + (xDists[0] / (xDists[0] + xDists[1])) * getOPixel(p[1]).b; //yDist[0]
interpolated = (yDists[0] / (yDists[0] + yDists[3])) * r1 + (yDists[3] / (yDists[0] + yDists[3])) * r2;
channel b = (channel)round(interpolated);
this->setPixel(x, y, { r, g, b });
}
}
delete[] xCenters;
delete[] yCenters;
delete[] newXCenters;
delete[] newYCenters;
delete originalData;
}
I have utmost respect for anyone even remotely willing to sift through this to try and help. Any and all suggestion will be extremely appreciated.
UPDATE: So as suggested I started augmenting the known data set with scaled down letters from word searches. This greatly improved accuracy from about 50% to 70% (percents calculated from a very small sample size so take the numbers lightly). Basically I'm using the original set of chars as a base (this original set was actually the most accurate out of other sets I've tried ex: a set calculated using the same resampling algorithm, a set using a different font etc.) And I just am manually adding knowns to that set. I basically will manually assign the first 20 or so images picked out in a search their corresponding letter and save that into the known set folder. I still am choosing the closest out of the entire known set to match a letter. Would this still be a good method or should some kind of change be made? I also implemented a feature where if a letter is about a 90% match with a known letter, I assume the match is correct and and the current "unknown" to the list of knowns. I could see this possibly going both ways, I feel like it could either a. make the program more accurate over time or b. solidify the original guess and possibly make the program less accurate over time. I have actually not noticed this cause a change (either for the better or for the worse). Am I on the right track with this? I'm not going to call this solved just yet, until I get accuracy just a little higher and test the program from more examples.
scaleTofunction do? (Sorry, I think that it takes too much effort to understand it, you should describe in words what it does). Downscaling usually done by sampling from a lowpass filtered version of the image. The simplest one is box filter (just summing the corresponding pixels) or you can use more sophisticated methods (sinc filter, etc.) – Sotelo