Background
We maintain a "cluster" of Ubuntu hosts which run our production applications. The hosts run a wide variety of docker containers such as
- consul for container monitoring and prometheus service discovery
- elasticsearch cluster with multiple logstash's and kibana
- prometheus
- grafana
- internally developed applications (service A through K on the diagram below)
Each host also runs
- filebeat
- nginx
- keepalived
- consul for the docker overlay network
The setup is as follows:
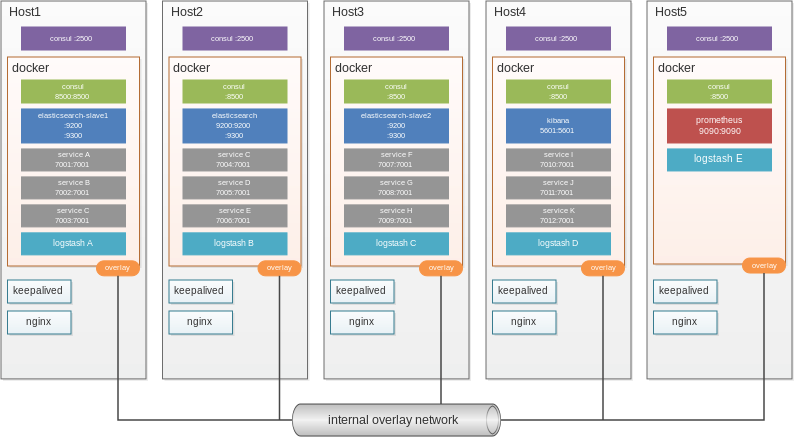
Image info
- Host consul exposes ports in the 2xxx rather than the standard 8xxx
- Not all docker containers are exposed to the outside world, for example
elasticsearch-slave1has no exposed ports but the internally used ports are shown as:9200 - docker consul uses the overlay network for all communication and only the
consul-masteron Host1 has port8500exposed externally.
Configuration
Some of this information may not be at all relevant to the issue.
Host: Ubuntu 16.04.3 LTS
Host services
| Application | Version |
| ----------- | ---------- |
| docker | 18.03.1-ce |
| consul | v1.0.2 |
Docker services
| Application | Version |
| ------------- | ------- |
| consul | v1.0.2 |
| elasticsearch | 5.6.4 |
| logstash | 5.6.4 |
| kibana | 5.6.4 |
| prometheus | 2.0.0 |
docker.service
Docker on each host is configured as follows:
[Service]
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise ${THIS_MACHINES_IP}:2375 --cluster-store consul://${THIS_MACHINES_IP}:2500 --label com.domain.hostname=host05.domain.com
Issues
When we first deployed this configuration it worked incredibly well. But over time the docker overlay network has become increasingly less reliable. Containers on HostX will simply be unable to communicate with other containers on HostY using the overlay network.
For example, prometheus on Host5 scrapes information from service A on Host1 but will frequently report "no route to host" or "context deadline exceeded". If I docker exec into the prometheus container and attempt to ping or curl service A I just receive timeouts. However, if I docker exec into service A and attempt to ping and curl prometheus the packets go through and this seems to "wake up" the network. Now prometheus can see the service again.
The same issue occurs between multiple services - this frequently leads to logstash not being able to post to elasticsearch or the elasticsearch-master being unable to contact the slaves which breaks the cluster.
Because this setup is being actively used in our production environment we cannot afford network downtime like this. I have implemented a set of scheduled jobs that curl/ping between the various services to keep the network alive. This is obviously not a good long term solution!
What makes the situation even worse is there have been occasions where the network has become so bad that the curl/ping jobs do not help and rebooting the host or docker has no effect. The only solution I have found is to
- Create a new
temporary overlaynetwork - Disconnect each container from the
primary overlayand connect them to thetemporary overlay - Delete the
primary overlay - Create a new
primary overlay - Disconnect each container from the
temporary overlayand connect them to theprimary overlay - Delete the
temporary overlay
This approach has been the best solution I have found so far to completely recover the network. It will then operate well for some time before falling over again.
Questions
The burning question for me is how can I debug this issue and get to the root cause?
There are a few people who have experienced this issue but it is generally in small setups and not at the same scale as above. At the moment it feels like I am running Schrodinger's Network...
Secondary to that - Is there a better way to implement an overlay network?
I have started experimenting with weave and Open vSwitch but neither is a good drop in replacement for the current network.
Weave would require redeploying all the containers (which is possible) but it adds a secondary network interface to each container and the ethwe interface is not the primary interface which causes issues with consul and prometheus which bind to specific interface/address.
Open vSwitch seems like a drop in replacement but I could not get it working with the LTS version (2.5.x) and had to build 2.10.x from source. This seemed to work initially but elasticsearch is not clustering and consul seems to really struggle to communicate over the network. prometheus also cannot query consul for some reason. I assume there are some packets being dropped by the switch which may just be a configuration issue.
Edit - 28/09/2018
Since posting this question I have been testing using Docker Swarm to manage the overlay network.
So far it is working quite well and the network does not stop working randomly as it did when using consul cluster store. However, there are some key differences and some common failures. For example:
- Executing
docker network inspect <my overlay network>on a host will only show the containers running on that host. When using Consul as a cluster store you can see the entire network from any host. - It is still possible to get the network into a bad state where containers cannot see each other. This is possible by stopping, removing, and recreating a container (same name as before) relatively quickly. In this scenario the existing containers keep using the old DNS entry and cannot connect.