I would like to feed TFRecords into my model at a super fast rate. However, currently, my GPU(Single K80 on GCP) is at 0% load which is super slow on CloudML.
I have TFRecords in GCS: train_directory = gs://bucket/train/*.tfrecord, (around 100 files of 30mb-800mb in size), but for some reason it struggles to feed the data into my model fast enough for GPU.
Interestingly, loading data into memory and using numpy arrays using fit_generator() is 7x faster. There I can specify multi-processing and multi workers.
My current set up parses tf records and loads an infinite tf.Dataset. Ideally, the solution would save/prefecth some batches in memory, for the gpu to use on demand.
def _parse_func(record):
""" Parses TF Record"""
keys_to_features = {}
for _ in feature_list: # 300 features ['height', 'weights', 'salary']
keys_to_features[_] = tf.FixedLenFeature([TIME_STEPS], tf.float32)
parsed = tf.parse_single_example(record, keys_to_features)
t = [tf.manip.reshape(parsed[_], [-1, 1]) for _ in feature_list]
numeric_tensor = tf.concat(values=t, axis=1)
x = dict()
x['numeric'] = numeric_tensor
y = ...
w = ...
return x, y, w
def input_fn(file_pattern, b=BATCH_SIZE):
"""
:param file_pattern: GCS bucket to read from
:param b: Batch size, defaults to BATCH_SIZE in hparams.py
:return: And infinitely iterable data set using tf records of tf.data.Dataset class
"""
files = tf.data.Dataset.list_files(file_pattern=file_pattern)
d = files.apply(
tf.data.experimental.parallel_interleave(
lambda filename: tf.data.TFRecordDataset(filename),
cycle_length=4,
block_length=16,
buffer_output_elements=16,
prefetch_input_elements=16,
sloppy=True))
d = d.apply(tf.contrib.data.map_and_batch(
map_func=_parse_func, batch_size=b,
num_parallel_batches=4))
d = d.cache()
d = d.repeat()
d = d.prefetch(1)
return d
Get train data
# get files from GCS bucket and load them into dataset
train_data = input_fn(train_directory, b=BATCH_SIZE)
Fit the model
model.fit(x=train_data.make_one_shot_iterator())
I am running it on CloudML so GCS and CloudML should be pretty fast.
CloudML CPU Usage:
As we can see below, the CPU is at 70% and the memory doesn't increase past 10%. So what does the dataset.cache() do?
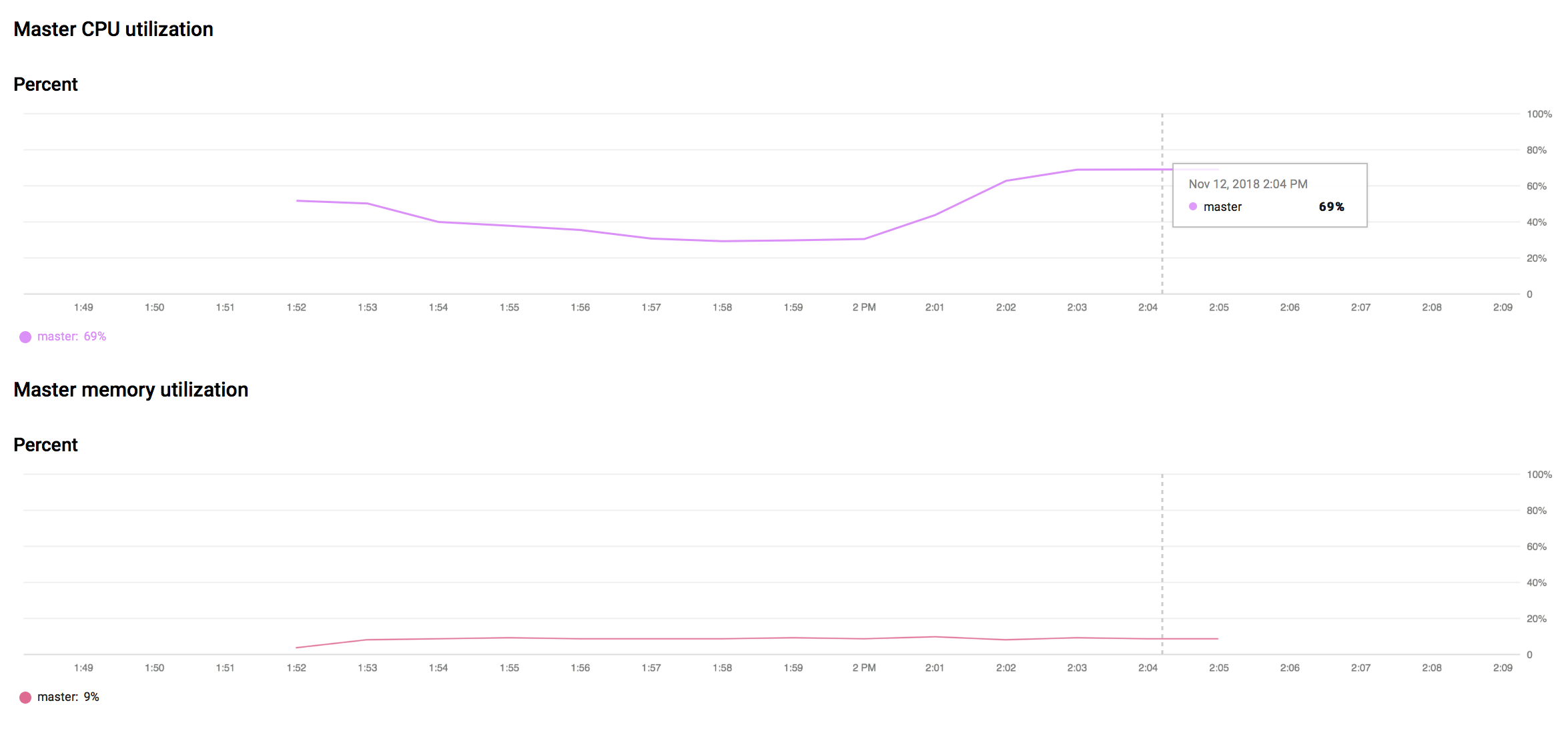
GPU metrics in CloudML logs
As seen below, it seems that the GPU is off! Also the memory is at 0mb. Where is the cache stored?
No processes running on GPU!
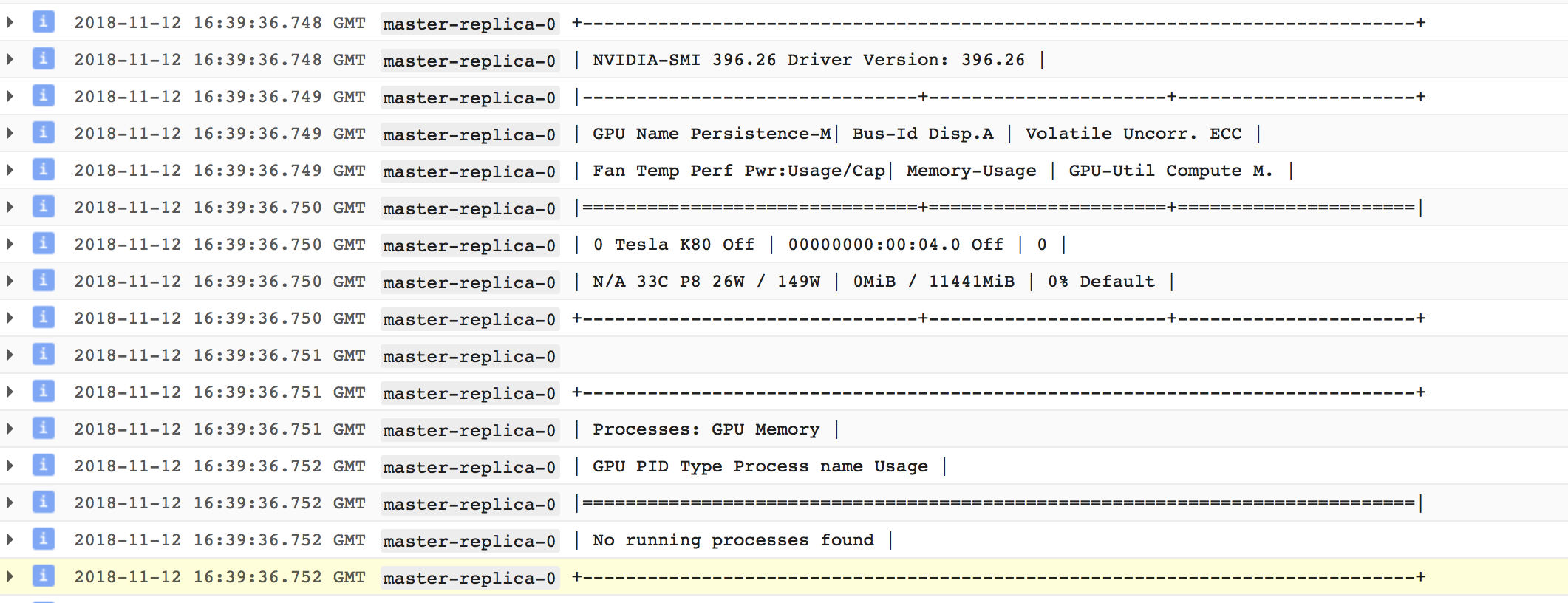
Edit:
It seems that indeed, there are not processes running on GPU. I tried to explicitly state:
tf.keras.backend.set_session(tf.Session(config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=True)))
train_data = input_fn(file_pattern=train_directory, b=BATCH_SIZE)
model = create_model()
with tf.device('/gpu:0'):
model.fit(x=train_data.make_one_shot_iterator(),
epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_data=test_data.make_one_shot_iterator(),
validation_steps=VALIDATION_STEPS)
but everything still utilises the CPU!