I know this question may not be a new one, but training/fine-tuning tesseract is one of the hardest part, I could never find any articles which can explain it properly. All the tutorials or docs no one explained it completely, going through them raises more questions than answer.
So I am really hoping I get some clarification on few aspects, if possible in layman terms.
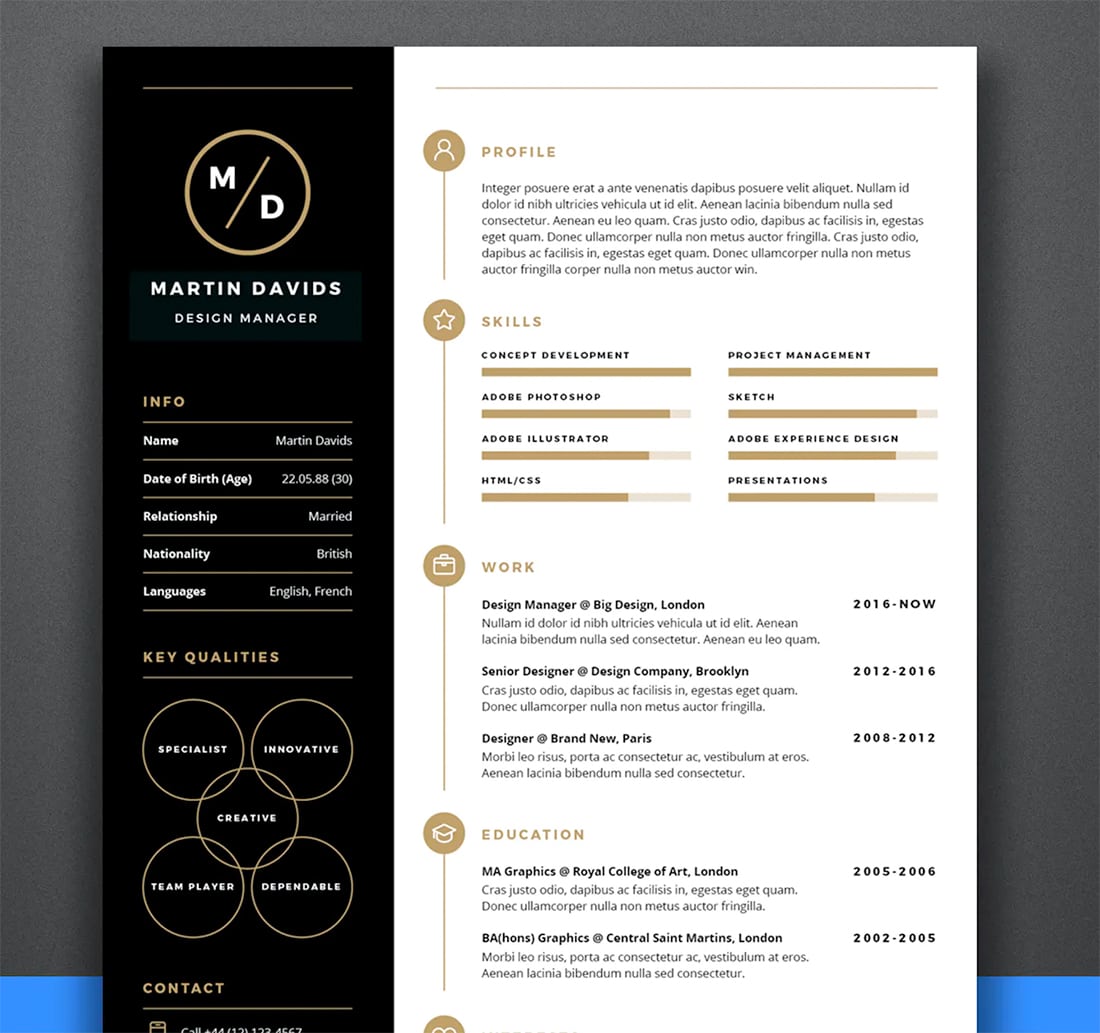
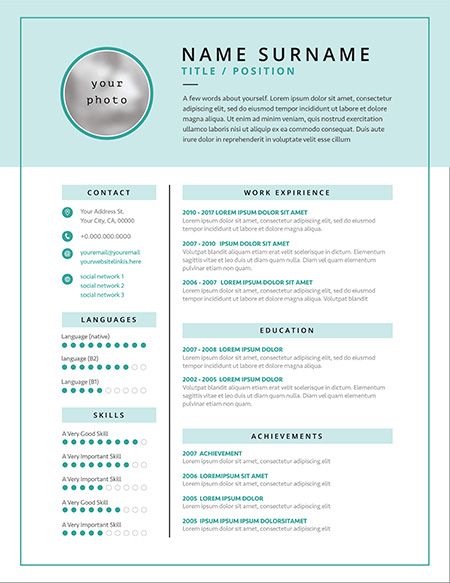
I have some resumes like these, link1 link2 link3
{kind=link}
{kind=link}
{kind=link}
These are some complex resumes and training them would require tesseract understanding whether to extract text from left to right, especially in two column resumes it needs to parse one column text then another column text.
Now, how can I finetune tesseract for this purpose since it was not parsing it properly when tried?
Some says I need to create a box file with coordinates of each character in the image, some docs says you need a image file and a text file with same name containing text? Which is the correct format here? Which has advantage over a problem like mine.
Now, if I need to get each character coordinate can I use a online ocr platform like google vision api for generating such data since manually annotating them would never be a easy task. Even though the google vision api returns text and each character bounding coordinates it might not be the coordinates that tesseract would be looking for?
Also, is tesseract even the answer for my question or do I need to build a seperate ocr model (any github links or pre-trained models that I can utilize)?
Please provide any form of assistance to my questions, I had searched everywhere for answers for weeks now but no luck. Please help me out.
EDIT: Looking forward to more detailed answer.