I've been having some issues when trying to synchronously playback and record audio to/from a device, in this case, my laptop speakers and microphone.
The problem
I've tried to implement this using the Python modules: "sounddevice" and "pyaudio"; but both implementations have this weird issue where the first few frames of recorded audio are always zero. Has anyone else experienced this type of issue? This issue seems to be independent of the chunksize that is used (i.e., its always the same amount of samples being zero).
Is there anything I can do to prevent this from happening?
Code
import queue
import matplotlib.pyplot as plt
import numpy as np
import pyaudio
import soundfile as sf
FRAME_SIZE = 512
excitation, fs = sf.read("excitation.wav", dtype=np.float32)
# Instantiate PyAudio
p = pyaudio.PyAudio()
q = queue.Queue()
output_idx = 0
mic_buffer = np.zeros((excitation.shape[0] + FRAME_SIZE
- (excitation.shape[0] % FRAME_SIZE), 1))
def rec_play_callback(in_data, framelength, time_info, status):
global output_idx
# print status of playback in case of event
if status:
print(f"status: {status}")
chunksize = min(excitation.shape[0] - output_idx, framelength)
# write data to output buffer
out_data = excitation[output_idx:output_idx + chunksize]
# write input data to input buffer
inputsamples = np.frombuffer(in_data, dtype=np.float32)
if not np.sum(inputsamples):
print("Empty frame detected")
# send input data to buffer for main thread
q.put(inputsamples)
if chunksize < framelength:
out_data[chunksize:] = 0
return (out_data.tobytes(), pyaudio.paComplete)
output_idx += chunksize
return (out_data.tobytes(), pyaudio.paContinue)
# Define playback and record stream
stream = p.open(rate=fs,
channels=1,
frames_per_buffer=FRAME_SIZE,
format=pyaudio.paFloat32,
input=True,
output=True,
input_device_index=1, # Macbook Pro microphone
output_device_index=2, # Macbook Pro speakers
stream_callback=rec_play_callback)
stream.start_stream()
input_idx = 0
while stream.is_active():
data = q.get(timeout=1)
mic_buffer[input_idx:input_idx + FRAME_SIZE, 0] = data
input_idx += FRAME_SIZE
stream.stop_stream()
stream.close()
p.terminate()
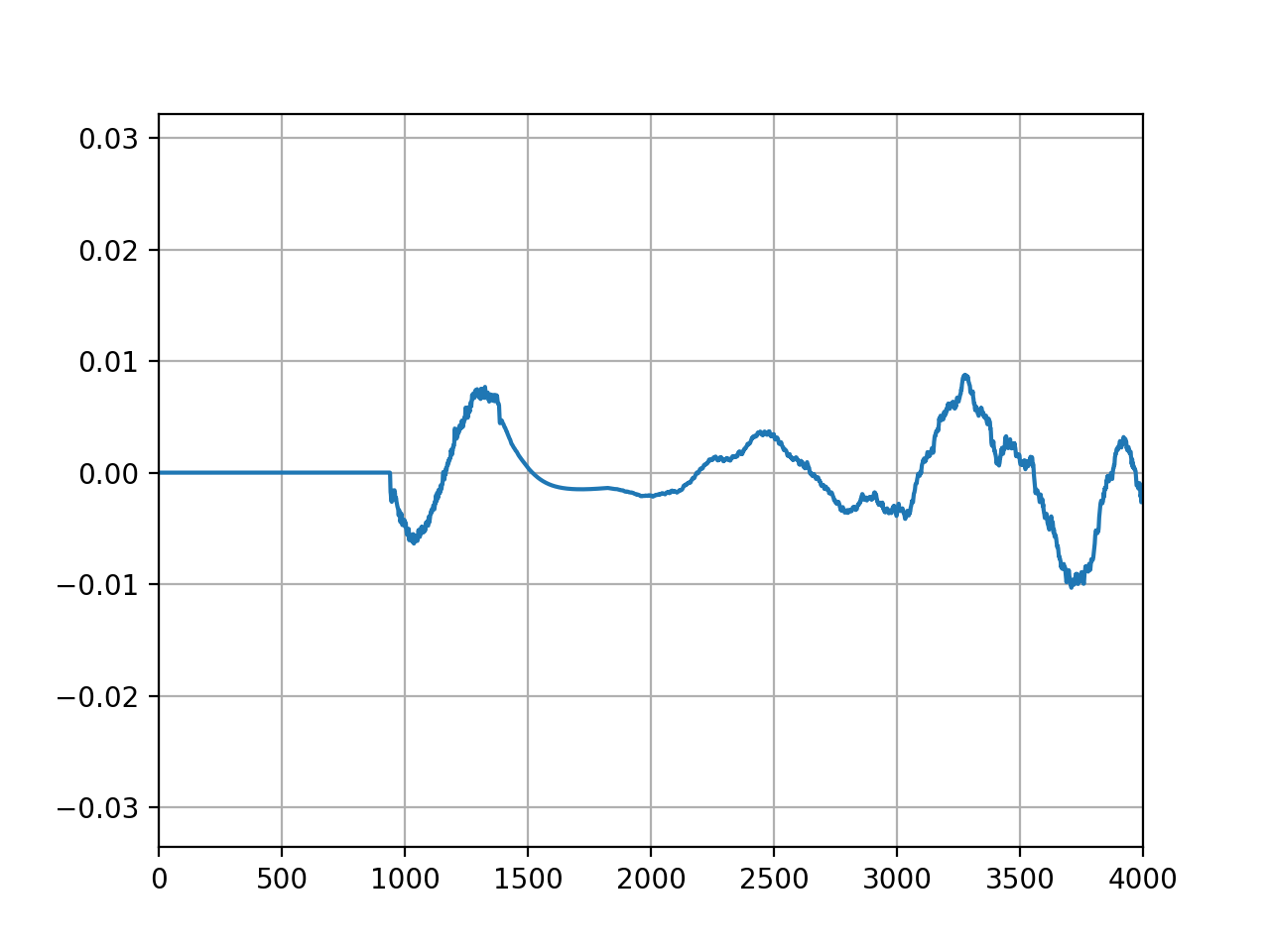
# Plot captured microphone signal
plt.plot(mic_buffer)
plt.show()
Output
Empty frame detected
Edit: running this on MacOS using CoreAudio. This might be relevant, as pointed out by @2e0byo.
time.sleepafter starting the read? source – Vincechannels=2– Vince