I am using this GSDMM python implementation to cluster a dataset of text messages. GSDMM converges fast (around 5 iterations) according the inital paper. I also have a convergence to a certain number of clusters, but there are still a lot of messages transferred in each iteration, so a lot of messages are still changing their cluster.
My output looks like:
In stage 0: transferred 9511 clusters with 150 clusters populated
In stage 1: transferred 4974 clusters with 138 clusters populated
In stage 2: transferred 2533 clusters with 90 clusters populated
….
In stage 34: transferred 1403 clusters with 47 clusters populated
In stage 35: transferred 1410 clusters with 47 clusters populated
In stage 36: transferred 1430 clusters with 48 clusters populated
In stage 37: transferred 1463 clusters with 48 clusters populated
In stage 38: transferred 1359 clusters with 48 clusters populated
In the initial paper figure 3 shows the same pattern, the number of clusters in nearly constant.
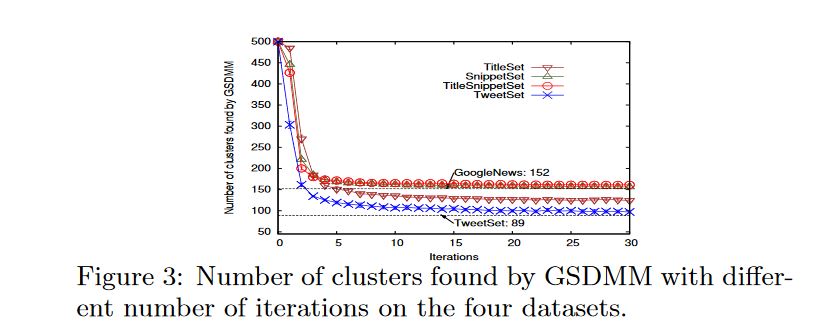
What I can't figure out is how many messages of their dataset where still transfering. My understanding is, that this number should be as small as possible, in best case zero (so every message "found" the right cluster). So the number of clusters might be converging, but that doens´t say much about the quality of the algorithm/clusters. Is my understanding correct?
It also is a possibility that my data is not good enough to get proper clustering.
K=600, converging toN=47-48Cluster. I think it is ok that it doesn´t corverge to a specific number, there might just be some messages that fit well in several clusters.You can also see this behaviour in the figure "TweetSet", it is moving a little bit. My Hyperparameters after some Grid Search with long Runtime are: alpha=0.01, beta=0.05. For K I think it is just important, that it is big enought. – Maryjomarylalpha=0.05, beta=0.01– Maryjomarylmgp.scorewhere you can see, how sure the algorithm is in assigning an input text to a cluster. I use the average of how sure the algorithm is over all input documents to compare different Hyperparameters. It is a metrik that I came up with one my own because I had the same stuggles like you :) I´m also discussing things like that in this post – Maryjomaryllog-likelihood,u-massandtopic coherencefor LDA, but wasn´t really happy with the results. What do you use? – Maryjomaryl