STEPS:
- Extract the
id_numbers from user_id and convert them to int type.
- Use
groupby and agg to evaluate count/ucount / `frequency.
- use
pivot to restructure the table.
- flatten the columns and
reset_index if required.
df['userid'] = df.userid.str.extract(r'(\d+)').astype(int)
k = df.groupby(["type", 'cid']).agg(count=('userid', 'count'), ucount=(
'userid', 'nunique'), frequency=('userid', lambda x: x.value_counts().to_dict())).reset_index()
k = k.pivot(index=[k.index, 'cid'], columns='type').fillna(0)
OUTPUT:
count ucount frequency
type c i c i c i
cid
0 1 1.0 0.0 1.0 0.0 {1: 1} 0
1 1 0.0 3.0 0.0 2.0 0 {1: 2, 2: 1}
2 2 0.0 1.0 0.0 1.0 0 {1: 1}
Then to transform columns:
k.columns = k.columns.map(lambda x: '_'.join(x[::-1]))
OUTPUT:
c_count i_count c_ucount i_ucount c_frequency i_frequency
cid
0 1 1.0 0.0 1.0 0.0 {1: 1} 0
1 1 0.0 3.0 0.0 2.0 0 {1: 2, 2: 1}
2 2 0.0 1.0 0.0 1.0 0 {1: 1}
updated answer (according to your edited question):
k = df.groupby(["type" , 'cid']).agg(count = ('userid' ,'count') , ucount = ('userid', 'nunique') , frequency=('userid', lambda x: x.value_counts().to_dict())).reset_index()
k = k.pivot(index=['cid'], columns ='type').fillna(0)
OUTPUT:
count ucount frequency
type c i c i c i
cid
1 1.0 3.0 1.0 2.0 {'userid001': 1} {'userid001': 2, 'userid002': 1}
2 0.0 1.0 0.0 1.0 0 {'userid001': 1}
NOTE: use df.userid = df.userid.factorize()[0] to encode userid if required.

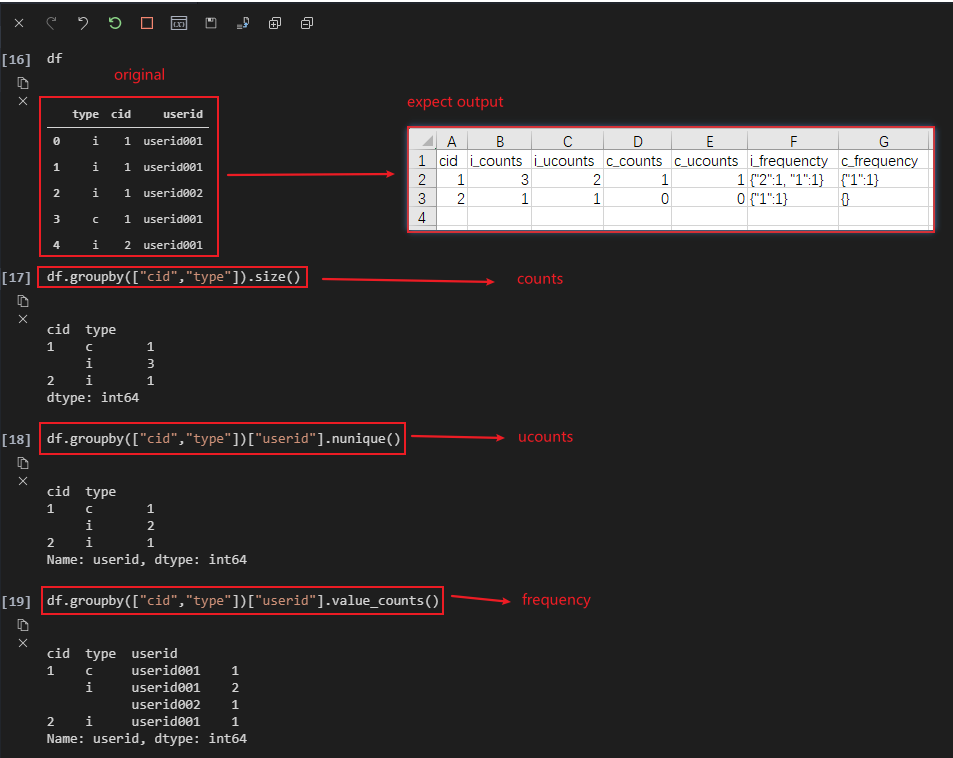
df.groupby(["cid","type"]).agg(counts=("userid", np.size), ucounts=("userid", "nunique")).reset_index(), but don't know how to do the next to get what I want as expect – Decamp